在Hadoop2.X之前,Namenode是HDFS集群中可能發生單點故障的節點,每個HDFS集群只有一個namenode,一旦這個節點不可用,則整個HDFS集群將處于不可用狀態。
HDFS高可用(HA)方案就是為了解決上述問題而產生的,在HA HDFS集群中會同時運行兩個Namenode,一個作為活動的Namenode(Active),一個作為備份的Namenode(Standby)。備份的Namenode的命名空間與活動的Namenode是實時同步的,所以當活動的Namenode發生故障而停止服務時,備份Namenode可以立即切換為活動狀態,而不影響HDFS集群服務。
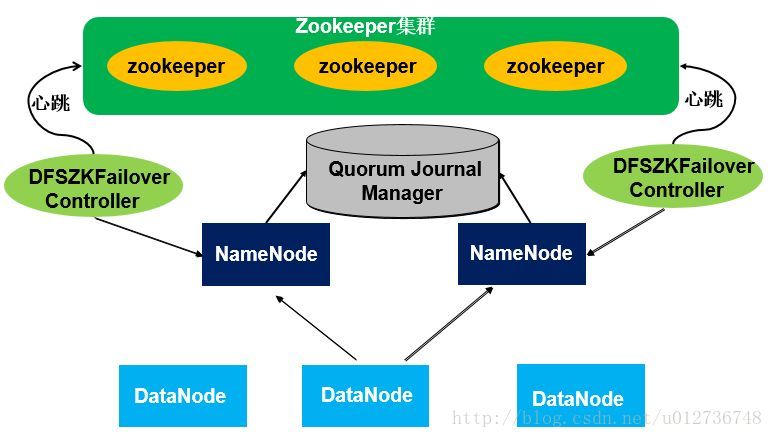
在一個HA集群中,會配置兩個獨立的Namenode。在任意時刻,只有一個節點作為活動的節點,另一個節點則處于備份狀態。活動的Namenode負責執行所有修改命名空間以及刪除備份數據塊的操作,而備份的Namenode則執行同步操作,以保持與活動節點命名空間的一致性。
為了使備份節點與活動節點的狀態能夠同步一致,兩個節點都需要同一組獨立運行的節點(JournalNodes,JNS)通信。當Active Namenode執行了修改命名空間的操作時,它會定期將執行的操作記錄在editlog中,并寫入JNS的多數節點中。而Standby Namenode會一直監聽JNS上editlog的變化,如果發現editlog有改動,Standby Namenode就會讀取editlog并與當前的命名空間合并。當發生了錯誤切換時,Standby節點會保證已經從JNS上讀取了所有editlog并與命名空間合并,然后才會從Standby狀態切換為Active狀態。通過這種機制,保證了Active Namenode與Standby Namenode之間命名空間狀態的一致性,也就是第一關系鏈的一致性。
為了使錯誤切換能夠很快的執行完畢,就要保證Standby節點也保存了實時的數據快的存儲信息,也就是第二關系鏈。這樣發生錯誤切換時,Standby節點就不需要等待所有的數據節點進行全量數據塊匯報,而直接可以切換到Active狀態。為了實現這個機制,Datanode會同時向這兩個Namenode發送心跳以及塊匯報信息。這樣就實現了Active Namenode 和standby Namenode 的元數據就完全一致,一旦發生故障,就可以馬上切換,也就是熱備。
這里需要注意的是 Standby Namenode只會更新數據塊的存儲信息,并不會向namenode 發送復制或者刪除數據塊的指令,這些指令只能由Active namenode發送。
在HA架構中有一個非常重非要的問題,就是需要保證同一時刻只有一個處于Active狀態的Namenode,否則機會出現兩個Namenode同時修改命名空間的問,也就是腦裂(Split-brain)。腦裂的HDFS集群很可能造成數據塊的丟失,以及向Datanode下發錯誤的指令等異常情況。為了預防腦裂的情況,HDFS提供了三個級別的隔離機制(fencing):
- 1.共享存儲隔離:同一時間只允許一個Namenode向JournalNodes寫入editlog數據。
- 2.客戶端隔離:同一時間只允許一個Namenode響應客戶端的請求。
- 3.Datanode隔離:同一時間只允許一個Namenode向Datanode下發名字節點指令,李如刪除、復制數據塊指令等等。
在HA實現中還有一個非常重要的部分就是Active Namenode和Standby Namenode之間如何共享editlog日志文件。Active Namenode會將日志文件寫到共享存儲上。Standby Namenode會實時的從共享存儲讀取edetlog文件,然后合并到Standby Namenode的命名空間中。這樣一旦Active Namenode發生錯誤,Standby Namenode可以立即切換到Active狀態。在Hadoop2.6中,提供了QJM(Quorum Journal Manager)方案來解決HA共享存儲問題。
所有的HA實現方案都依賴于一個保存editlog的共享存儲,這個存儲必須是高可用的,并且能夠被集群中所有的Namenode同時訪問。Quorum Journa是一個基于paxos算法的HA設計方案。
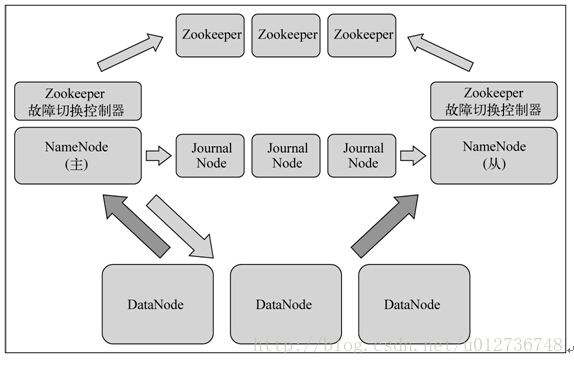
Quorum Journal方案中有兩個重要的組件。
- 1.JournalNoe(JN):運行在N臺獨立的物理機器上,它將editlog文件保存在JournalNode的本地磁盤上,同時JournalNode還對外提供RPC接口QJournalProtocol以執行遠程讀寫editlog文件的功能。
- 2.QuorumJournalManager(QJM):運行在NmaeNode上,(目前HA集群只有兩個Namenode),通過調用RPC接口QJournalProtocol中的方法向JournalNode發送寫入、排斥、同步editlog。
Quorum Journal方案依賴于這樣一個概念:HDFS集群中有2N+1個JN存儲editlog文件,這些editlog 文件是保存在JN的本地磁盤上的。每個JN對QJM暴露QJM接口QJournalProtocol,允許Namenode讀寫editlog文件。當Namenode向共享存儲寫入editlog文件時,它會通過QJM向集群中所有的JN發送寫editlog文件請求,當有一半以上的JN返回寫操作成功時,即認為寫成功。這個原理是基于Paxos算法的。
使用Quorum Journal實現的HA方案有一下優點:
- 1.JN進程可以運行在普通的PC上,而無需配置專業的共享存儲硬件。
- 2.不需要單獨實現fencing機制,Quorum Journal模式中內置了fencing功能。
- 3. Quorum Journa不存在單點故障,集群中有2N+1個Journal,可以允許有N個Journal Node死亡。
- 4. JN不會因為其中一個機器的延遲而影響整體的延遲,而且也不會因為JN數量的增多而影響性能(因為Namenode向JournalNode發送日志是并行的)
互斥機制
當HA集群中發生Namenode異常切換時,需要在共享存儲上fencing上一個活動的節點以保證該節點不能再向共享存儲寫入editlog。基于Quorum Journal模式的HA提供了epoch number來解決互斥問題,這個概念可以在分布式文件系統中找到。epoch number具有以下幾個性質。
1.當一個Namenode變為活動狀態時,會分配給他一個epoch number。
2.每個epoch number都是唯一的,沒有任意兩個Namenode有相同的epoch number。
3.epoch number 定義了Namenode寫editlog文件的順序。對于任意兩個namenode ,擁有更大epoch number的Namenode被認為是活動節點。
當一個Namenode切換為活動狀態時,它的QJM會向所有的JN發送命令,以獲取該JN的最后一個promise epoch變量值。當QJM接受到了集群中多于一半的JN回復后,它會將所接收到的最大值加一,并保存到myepoch 中,之后QJM會將該值發送給所有的JN并提出更新請求。每個JN會將該值與自身的epoch值相互比較,如果新的myepoch比較大,則JN更新,并返回更新成功;如果小,則返回更新失敗。如果QJM接收到超過一半的JN返回成功,則設置它的epoch number為myepoch;,否則它終止嘗試為一個活動的Namenode,并拋出異常。
當活動的NameNode成功獲取并更新了epoch number后,調用任何修改editlog的RPC請求都必須攜帶epoch number。當RPC請求到達JN后,JN會將請求者的epoch與自身保存的epoch相互對比,若請求者的epoch更大,JN就會更新自己的epoch,并執行相應的操作,如果請求者的epoch小,就會拒絕相應的請求。當集群中大多數的JN拒絕了請求時,這次操作就失敗了。
當HDFS集群發生Namenode錯誤切換后,原來的standby Namenode將集群的epoch number加一后更新。這樣原來的Active namenode的epoch number肯定小于這個值,當這個節點執行寫editlog操作時,由于JN節點不接收epoch number小于自身的promise epoch的寫請求,所以這次寫請求會失敗,也就達到了fencing的目的。
寫流程
- 1.將editlog輸出流中緩存的數據寫入JN,對于集群中的每一個JN都存在一個獨立的線程調用RPC 接口中的方法向JN寫入數據。
- 2.當JN收到請求之后,JN會執行以下操作:
1)驗證epoch number是否正確
2)確認寫入數據對應的txid是否連續
3)將數據持久化到JN的本地磁盤
4)向QJM發送正確的響應
- 3.QJM等待集群JN的響應,如果多數JN返回成功,則寫操作成功;否則寫操作失敗,QJM會拋出異常。
Namenode會調用FSEditlogLog下面的方法初始化editlog文件的輸出流,然后使用輸出流對象向editlog文件寫入數據。
獲取了QuorumOutputStream輸出流對象之后,Namenode會調用write方法向editlog文件中寫入數據,QuorumOutputStream的底層也調用了EditsDoubleBuffer雙緩存區。數據回先寫入其中一個緩沖區中,然后調用flush方法時,將緩沖區中的數據發送給JN。
讀流程
Standby Namenode會從JN讀取editlog,然后與Sdtandby Namenode的命名空間合并,以保持和Active Namenode命名空間的同步。當Sdtandby Namenode從JN讀取editlog時,它會首先發送RPC請求到集群中所有的JN上。JN接收到這個請求后會將JN本地存儲上保存的所有FINALIZED狀態的editlog段落文件信息返回,之后QJM會為所有JN返回的editlog段落文件構造輸入流對象,并將這些輸入流對象合并到一個新的輸入流對象中,這樣Standby namenode就可以從任一個JN讀取每個editlog段落了。如果其中一個JN失敗了輸入流對象會自動切換到另一個保存了該edirlog段落的JN上。

恢復流程
當Namenode發生主從切換時,原來的Standby namenode會接管共享存儲并執行寫editlog的操作。在切換之前,對于共享存儲會執行以下操作:
1.fencing原來的Active Namenode。這部分在互斥部分已經講述。
2.恢復正在處理的editlog。由于Namenode發生了主從切換,集群中JN上正在執行寫入操作的editlog數據可能不一致。例如,可能出現某些JN上的editlog正在寫入,但是當前Active Namenode發生錯誤,這時該JN上的editlog文件就與已完成寫入的JN不一致。在這種情況下,需要對JN上所有狀態不一致的editlog文件執行恢復操作,將他們的數據同步一致,并且將editlog文件轉化為FINALIZED狀態。
3.當不一致的editlog文件完成恢復之后,這時原來的Standby Namenode就可以切換為Active Namenode并執行寫editlog的操作。
4.寫editlog。在前面已經介紹了。
日志恢復操作可以分為以下幾個階段:
1.確定需要執行恢復操作的editlog段落:在執行恢復操作之前,QJM會執行newEpoch()調用以產生新的epoch number,JN接收到這個請求后除了執行更新epoch number外,還會將該JN上保存的最新的editlog段落的txid返回。當集群中的大多數JN都發回了這個響應后,QJM就可以確定出集群中最新的一個正在處理editlog段落的txid,然后QJM就會對這個txid對應的editlog段落執行恢復操作了。
2.準備恢復:QJM向集群中的所有JN發送RPC請求,查詢執行恢復操作的editlog段落文件在所有JN上的狀態,這里的狀態包括editlog文件是in-propress還是FINALIZED狀態,以及editlog文件的長度。
3.接受恢復:QJM接收到JN發回的JN發回的響應后,會根據恢復算法選擇執行恢復操作的源節點。然后QJM會發送RPC請求給每一個JN,這個請求會包含兩部分信息:源editlog段落文件信息,以及供JN下載這個源editlog段落的url。
接收到這個RPC請求之后,JN會執行以下操作:
1)同步editlog段落文件,如果JN磁盤上的editlog段落文件與請求中的段落文件狀態不同,則JN會從當前請求中的url上下載段落文件,并替換磁盤上的editlog段落文件。
2)持久化恢復元數據,JN會將執行恢復操作的editlog段落文件的狀態、觸發恢復操作的QJM的epoch number等信息(恢復的元數據信息)持久化到磁盤上。
3)當這些操作都執行成功后,JN會返回成功響應給QJM,如果集群中的大多數JN都返回了成功,則此次恢復操作執行成功。
4.完成editlog段落文件:到這步操作時,QJM 就能確定集群中大多數的JN保存的editlog文件的狀態已經一致了,并且JN持久化了恢復信息。QJM就會向JN發送指令,將這個editlog段落文件的狀態轉化為FINALIZED狀態,,并且JN會刪除持久化的恢復元數據,因為磁盤上保存的editlog文件信息已經是正確的了,不需要保存恢復的元數據。
到此這篇關于詳細講解HDFS的高可用機制的文章就介紹到這了,更多相關HDFS的高可用機制內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- HDFS-Hadoop NameNode高可用機制
- JAVA讀取HDFS的文件數據出現亂碼的解決方案
- Hadoop 分布式存儲系統 HDFS的實例詳解
- JAVA操作HDFS案例的簡單實現
- hadoop的hdfs文件操作實現上傳文件到hdfs
