目錄
- 一、urllib庫(kù)是什么?
- 二、urllib庫(kù)的使用
- urllib.request模塊
- urllib.parse模塊
- 利用try-except,進(jìn)行超時(shí)處理
- status狀態(tài)碼 getheaders()
- 突破反爬
一、urllib庫(kù)是什么?
urllib庫(kù)用于操作網(wǎng)頁(yè) URL,并對(duì)網(wǎng)頁(yè)的內(nèi)容進(jìn)行抓取處理
urllib包 包含以下幾個(gè)模塊:
urllib.request - 打開(kāi)和讀取 URL。
urllib.error - 包含 urllib.request 拋出的異常。
urllib.parse - 解析 URL。
urllib.robotparser - 解析 robots.txt 文件
python爬蟲(chóng)主要用到的urllib庫(kù)中的request和parse模塊
二、urllib庫(kù)的使用
下面我們來(lái)詳細(xì)說(shuō)明一下這兩個(gè)常用模塊的基本運(yùn)用
urllib.request模塊
urllib.request 定義了一些打開(kāi) URL 的函數(shù)和類,包含授權(quán)驗(yàn)證、重定向、瀏覽器 cookies等。
語(yǔ)法如下:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None,
capath=None, cadefault=False, context=None)
url:url 地址。
data:發(fā)送到服務(wù)器的其他數(shù)據(jù)對(duì)象,默認(rèn)為 None。
timeout:設(shè)置訪問(wèn)超時(shí)時(shí)間。
cafile 和 capath:cafile 為 CA 證書, capath 為 CA 證書的路徑,使用 HTTPS 需要用到。
cadefault:已經(jīng)被棄用。
context:ssl.SSLContext類型,用來(lái)指定 SSL 設(shè)置。
# -*- codeing = utf-8 -*-
# @Author: Y-peak
# @Time : 2021/9/2 19:24
# @FileName : testUrllib.py
# Software : PyCharm
import urllib.request
#get請(qǐng)求
response = urllib.request.urlopen("http://www.baidu.com") #返回的是存儲(chǔ)網(wǎng)頁(yè)數(shù)據(jù)的對(duì)象
#print(response) 可以嘗試打印一下看一下
print(response.read().decode('utf-8')) #通過(guò)read將數(shù)據(jù)讀取出來(lái), 使用utf-8解碼防止有的地方出現(xiàn)亂碼
將其打印的內(nèi)容寫到一個(gè)html文件中,打開(kāi)和百度一毛一樣
# -*- codeing = utf-8 -*-
# @Author: Y-peak
# @Time : 2021/9/2 19:24
# @FileName : testUrllib.py
# Software : PyCharm
import urllib.request
response = urllib.request.urlopen("http://www.baidu.com") #返回的是存儲(chǔ)網(wǎng)頁(yè)數(shù)據(jù)的對(duì)象
data = response.read().decode('utf-8') #通過(guò)read將數(shù)據(jù)讀取出來(lái), 使用utf-8解碼防止有的地方出現(xiàn)亂碼
#print(data)
with open("index.html",'w',encoding='utf-8') as wfile: #或者你們也可以常規(guī)打開(kāi),不過(guò)需要最后關(guān)閉記得close()
wfile.write(data)
print("讀取結(jié)束")
urllib.parse模塊
有時(shí)我們爬蟲(chóng)需要模擬瀏覽器進(jìn)行用戶登錄等操作,這個(gè)時(shí)候我們就需要進(jìn)行post請(qǐng)求
但是post必須有一個(gè)獲取請(qǐng)求之后的響應(yīng),也就是我們需要有一個(gè)服務(wù)器。給大家介紹一個(gè)免費(fèi)的服務(wù)器網(wǎng)址,就是用來(lái)測(cè)試用的http://httpbin.org/。主要用來(lái)測(cè)試http和https的

我們可以嘗試執(zhí)行一下,去獲取對(duì)應(yīng)的響應(yīng)。

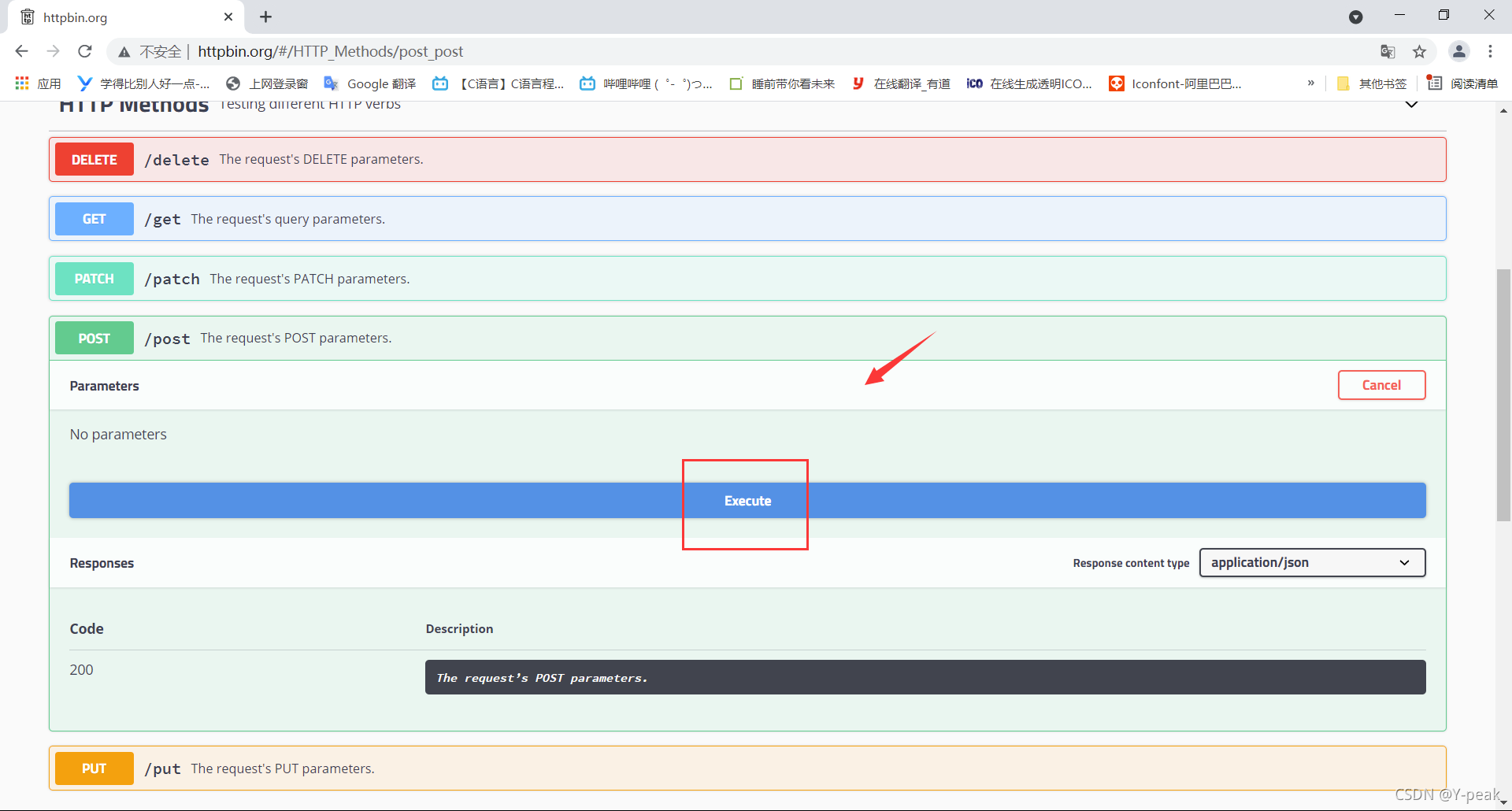
可以用Linux命令去發(fā)起請(qǐng)求,URL地址為http://httpbin.org/post。得到下方的響應(yīng)。

我們也可以通過(guò)爬蟲(chóng)來(lái)實(shí)現(xiàn)
# -*- codeing = utf-8 -*-
# @Author: Y-peak
# @Time : 2021/9/2 19:24
# @FileName : testUrllib.py
# Software : PyCharm
import urllib.request
import urllib.parse #解析器
data = bytes(urllib.parse.urlencode({"hello":"world"}),encoding='utf-8') #轉(zhuǎn)換為二進(jìn)制數(shù)據(jù)包,里面是鍵值對(duì)(有時(shí)輸入的用戶名:密碼就是這樣的),還有一些編碼解碼的數(shù)值等.這里就是按照utf-8的格式進(jìn)行解析封裝生成二進(jìn)制數(shù)據(jù)包
response = urllib.request.urlopen("http://httpbin.org/post",data=data) #返回的請(qǐng)求
print(response.read().decode('utf-8')) #通過(guò)read將數(shù)據(jù)讀取出來(lái), 使用utf-8解碼防止有的地方出現(xiàn)亂碼
兩個(gè)響應(yīng)結(jié)果對(duì)比是不是一樣幾乎

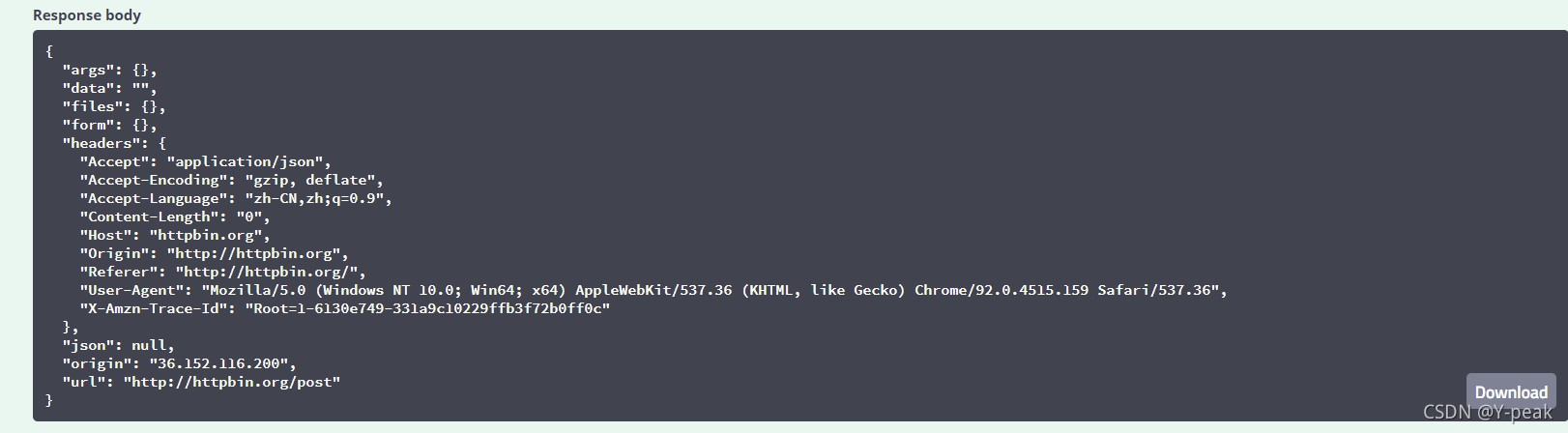
相當(dāng)于進(jìn)行了一次模擬的post請(qǐng)求。這樣有些需要登錄的網(wǎng)站也是可以爬取的。
利用try-except,進(jìn)行超時(shí)處理
一般進(jìn)行爬蟲(chóng)時(shí),不可能一直等待響應(yīng)。有時(shí)網(wǎng)絡(luò)不好或者網(wǎng)頁(yè)有反爬或者一些其他東西時(shí)。無(wú)法快速爬出。我們就可以進(jìn)入下一個(gè)網(wǎng)頁(yè)繼續(xù)去爬。利用timeout屬性就好
# -*- codeing = utf-8 -*-
# @Author: Y-peak
# @Time : 2021/9/2 19:24
# @FileName : testUrllib.py
# Software : PyCharm
import urllib.request
try:
response = urllib.request.urlopen("http://httpbin.org/get",timeout=0.01) #返回的是存儲(chǔ)網(wǎng)頁(yè)數(shù)據(jù)的對(duì)象, 直接用這個(gè)網(wǎng)址的get請(qǐng)求了.timeout表示超時(shí),超過(guò)0.01秒不響應(yīng)就報(bào)錯(cuò),避免持續(xù)等待
print(response.read().decode('utf-8')) #通過(guò)read將數(shù)據(jù)讀取出來(lái), 使用utf-8解碼防止有的地方出現(xiàn)亂碼
except urllib.error.URLError as e:
print("超時(shí)了\t\t錯(cuò)誤為:",e)
status狀態(tài)碼 getheaders()
status:
- 返回200,正確響應(yīng)可以爬取
- 報(bào)錯(cuò)404,沒(méi)有找到網(wǎng)頁(yè)
- 報(bào)錯(cuò)418,老子知道你就是爬蟲(chóng)
- getheaders():獲取Response Headers

- 也可以通過(guò)gethead(“xx”) 獲取xx對(duì)應(yīng)的值,比如:上圖 gethead(content-encoding) 為 gzip
突破反爬
首先打開(kāi)任何一個(gè)網(wǎng)頁(yè)按F12找到Response Headers,拉到最下面找到 User-Agent。將其復(fù)制保存下來(lái),為反爬做準(zhǔn)備。


下面我們進(jìn)行嘗試,直接爬取豆瓣,直接來(lái)個(gè)418,知道你是爬蟲(chóng),我們來(lái)偽裝一下

為什么418呢,因?yàn)槿绻侵苯舆M(jìn)行請(qǐng)求訪問(wèn)的話,發(fā)過(guò)去的User-Agent 是下面的,直接告訴瀏覽器我們是爬蟲(chóng)。我們需要偽裝
# -*- codeing = utf-8 -*-
# @Author: Y-peak
# @Time : 2021/9/2 19:24
# @FileName : testUrllib.py
# Software : PyCharm
import urllib.request
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"
}
request = urllib.request.Request("http://douban.com", headers=headers) #返回的是請(qǐng)求,將我們偽裝成瀏覽器發(fā)送的請(qǐng)求
response = urllib.request.urlopen(request) #返回的是存儲(chǔ)網(wǎng)頁(yè)數(shù)據(jù)的對(duì)象
data = response.read().decode('utf-8') #通過(guò)read將數(shù)據(jù)讀取出來(lái), 使用utf-8解碼防止有的地方出現(xiàn)亂碼
with open("index.html",'w',encoding='utf-8') as wfile: #或者你們也可以常規(guī)打開(kāi),不過(guò)需要最后關(guān)閉記得close()
wfile.write(data)
當(dāng)然反爬不可能如此簡(jiǎn)單,上面將講的那個(gè) post請(qǐng)求,也是十分常見(jiàn)的突破反爬的方式,不行就將整個(gè)Response Headers全部模仿。下面還有個(gè)例子作為參考。和上面的post訪問(wèn)的網(wǎng)址一樣
瀏覽器訪問(wèn)結(jié)果

爬蟲(chóng)訪問(wèn)結(jié)果
# -*- codeing = utf-8 -*-
# @Author: Y-peak
# @Time : 2021/9/3 0:47
# @FileName : testUrllib.py
# Software : PyCharm
import urllib.request
import urllib.parse
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"
}
url = "http://httpbin.org/post"
data = (bytes)(urllib.parse.urlencode({"賬戶":"密碼"}),encoding = 'utf-8')
request = urllib.request.Request(url, data = data,headers=headers, method='POST') #返回的是請(qǐng)求
response = urllib.request.urlopen(request) #返回的是存儲(chǔ)網(wǎng)頁(yè)數(shù)據(jù)的對(duì)象
data = response.read().decode('utf-8') #通過(guò)read將數(shù)據(jù)讀取出來(lái), 使用utf-8解碼防止有的地方出現(xiàn)亂碼
print(data)

以上就是關(guān)于python爬蟲(chóng)應(yīng)用urllib庫(kù)作用分析的詳細(xì)內(nèi)容,更多關(guān)于python爬蟲(chóng)urllib庫(kù)分析的資料請(qǐng)關(guān)注腳本之家其它相關(guān)文章!
您可能感興趣的文章:- python爬蟲(chóng)Scrapy框架:媒體管道原理學(xué)習(xí)分析
- python爬蟲(chóng)Mitmproxy安裝使用學(xué)習(xí)筆記
- Python爬蟲(chóng)和反爬技術(shù)過(guò)程詳解
- python爬蟲(chóng)之Appium爬取手機(jī)App數(shù)據(jù)及模擬用戶手勢(shì)
- 爬蟲(chóng)Python驗(yàn)證碼識(shí)別入門
- Python爬蟲(chóng)技術(shù)
- Python爬蟲(chóng)爬取商品失敗處理方法
- Python獲取江蘇疫情實(shí)時(shí)數(shù)據(jù)及爬蟲(chóng)分析
- Python爬蟲(chóng)之Scrapy環(huán)境搭建案例教程
- Python爬蟲(chóng)中urllib3與urllib的區(qū)別是什么
- 教你如何利用python3爬蟲(chóng)爬取漫畫島-非人哉漫畫
- Python爬蟲(chóng)分析匯總
