一、分析數據源
這里的數據源是指html網頁?還是Aajx異步。對于爬蟲初學者來說,可能不知道怎么判斷,這里辰哥也手把手過一遍。
提示:以下操作均不需要登錄(當然登錄也可以)
咱們先在瀏覽器里面搜索攜程,然后在攜程里面任意搜索一個景點:長隆野生動物世界,這里就以長隆野生動物世界為例,講解如何去爬取攜程評論數據。
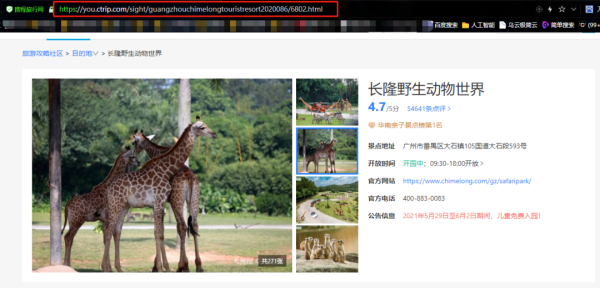
頁面下方則是評論數據
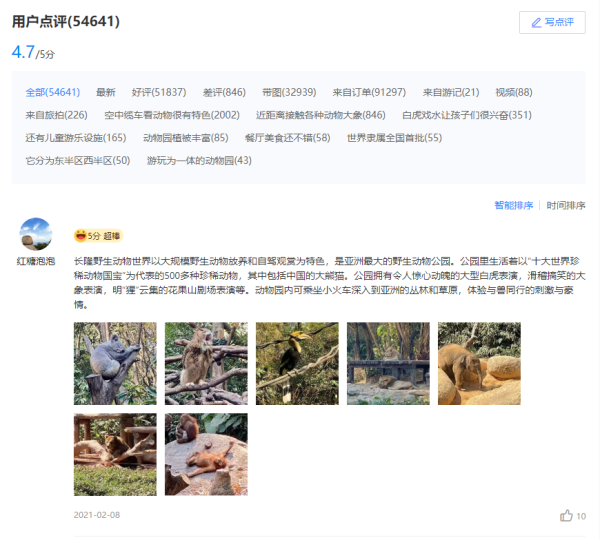
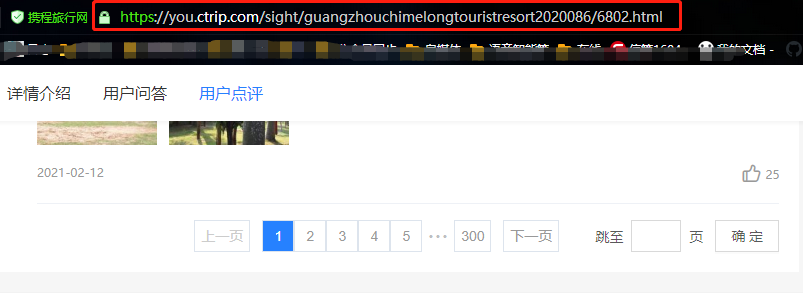
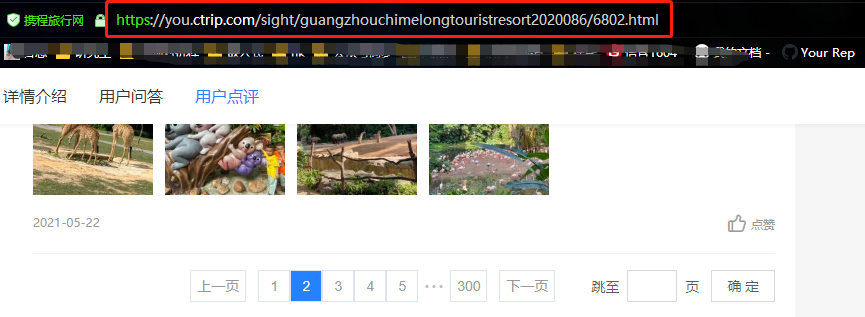
從上面兩張圖可以看出,點擊評論下一頁,瀏覽器的鏈接沒有變化,說明數據是Ajax異步請求。因此我們就找到了數據是異步加載過來的,這時候需要去network里面是查看數據包。
二、分析數據包
在network中找到下面這個數據包
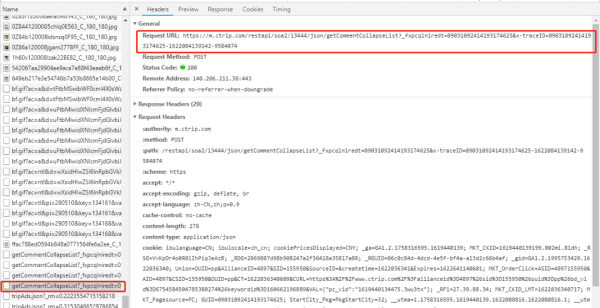
查看Preview里面的內容(請求返回內容)
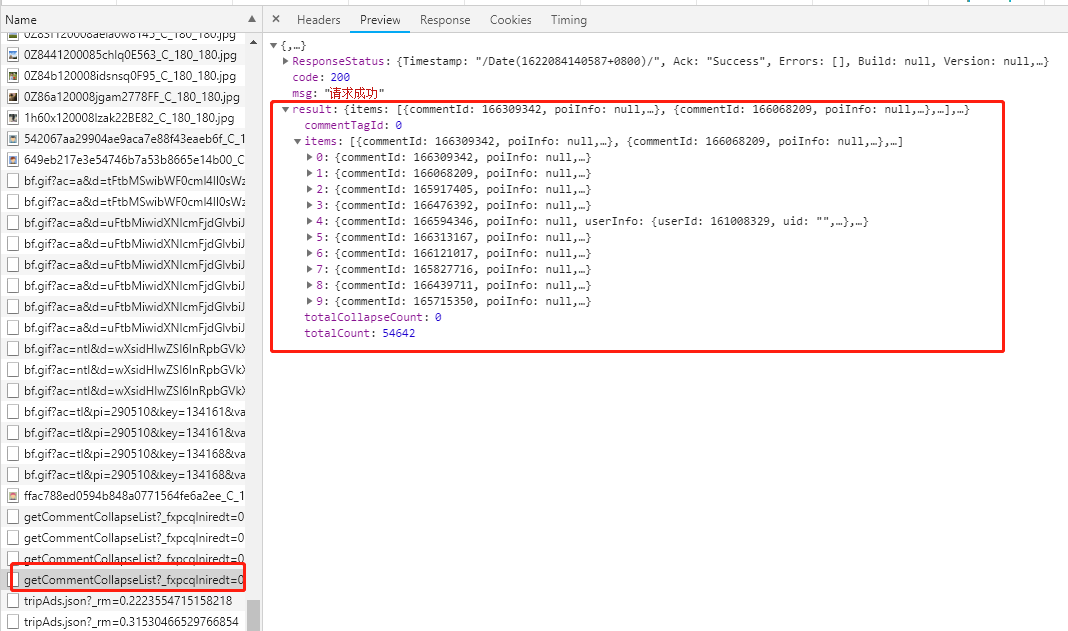
可以看到數據已經請求到了,下面看一下數據是否是正確的(和網頁內容一致)。

ok,沒問題之后,下面開始編寫Python程序去請求數據。
1.請求地址

可以獲取到請求鏈接和請求方式。
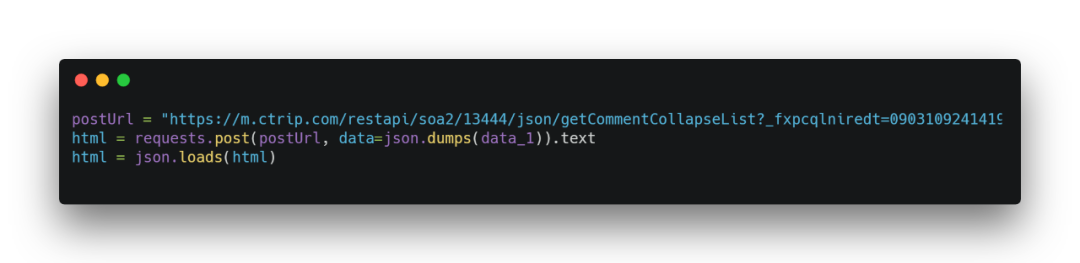
這里請求不用添加請求頭header也是可以的。其中postUrl是請求鏈接,data_1是請求參數。
2.請求參數
在network里可以看到請求參數
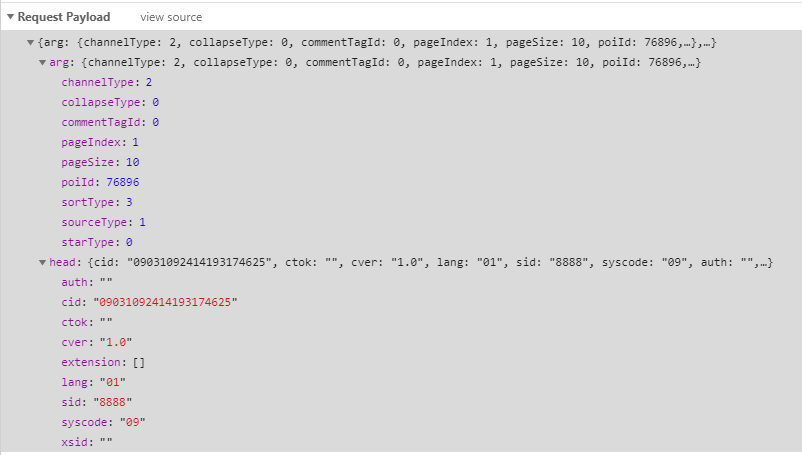
在程序中的構建如下:
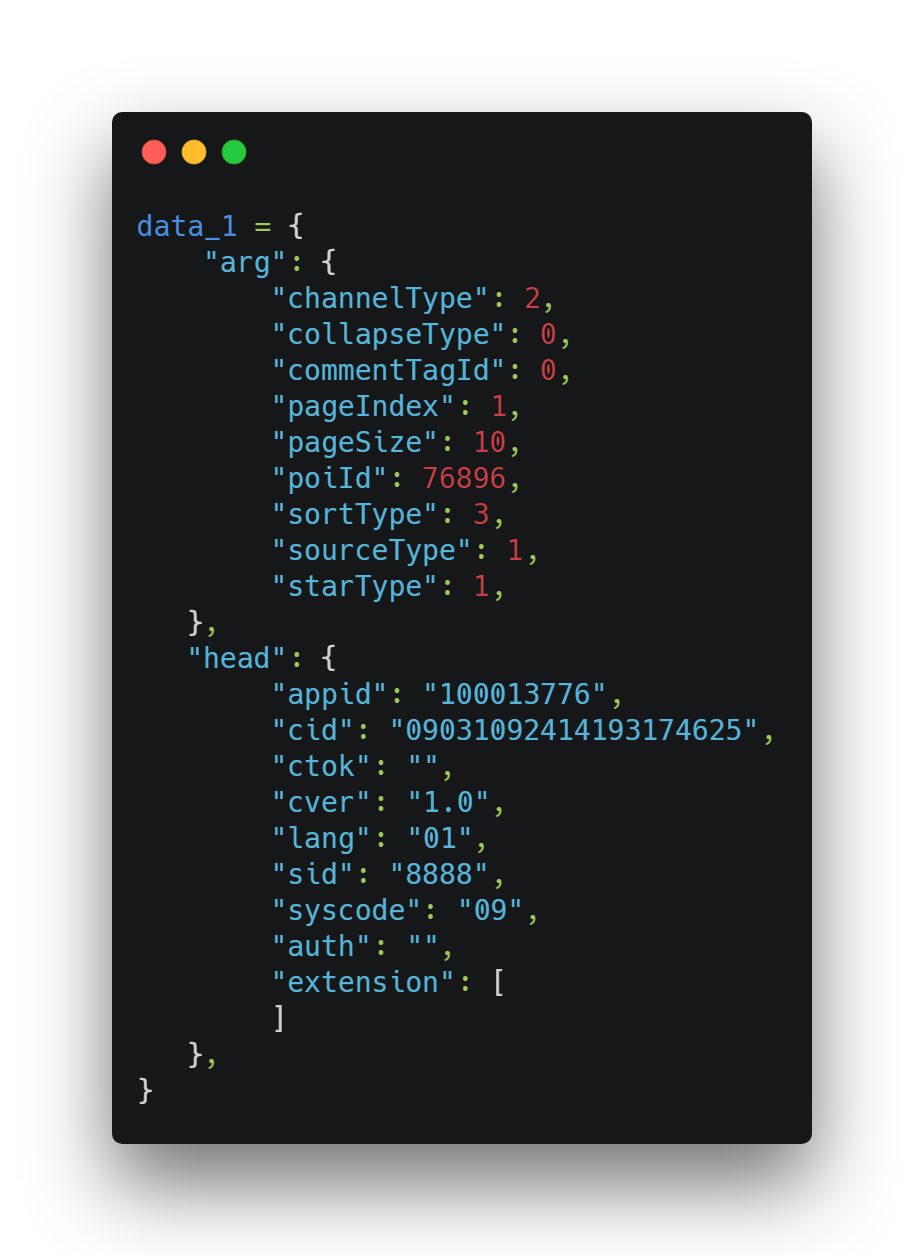
其中需要關注的是arg中的pageIndex(頁數),pageSize(每頁條數)。
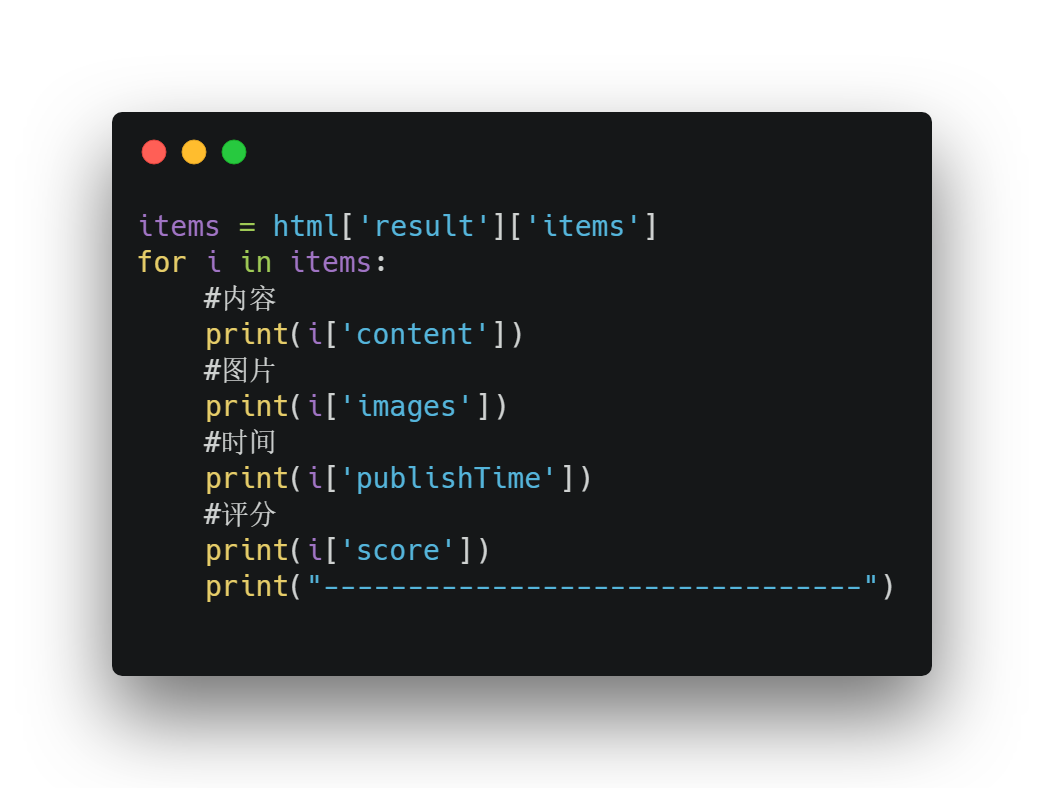
最終結果如下:

該景點的評論就可以成功爬取下來了。
三、采集全部評論
上面只是采集了第一頁的評論數據,通過改變arg中的pageIndex(頁數),就可以遍歷爬取全部的評論。

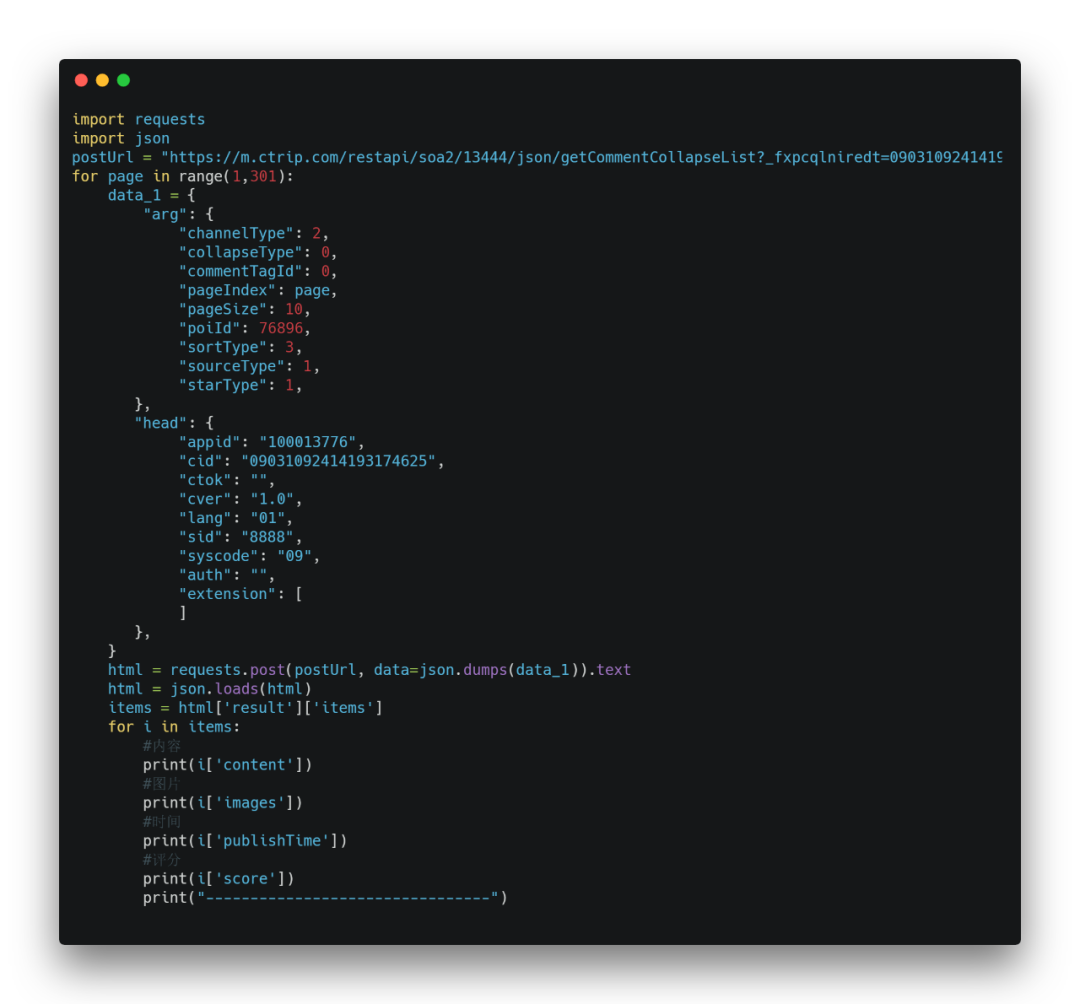
比如這個景點一共是300頁。現在把循環給加上
最終的完整代碼如下:
到此這篇關于Python爬蟲實戰之爬取攜程評論的文章就介紹到這了,更多相關Python爬取攜程評論內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python 爬取吉首大學網站成績單
- python趣味挑戰之爬取天氣與微博熱搜并自動發給微信好友
- python 爬取影視網站下載鏈接
- Python爬蟲之爬取我愛我家二手房數據
- python 爬取京東指定商品評論并進行情感分析
- python結合多線程爬取英雄聯盟皮膚(原理分析)
- python爬取豆瓣電影TOP250數據
- python爬取鏈家二手房的數據
- 教你怎么用python爬取愛奇藝熱門電影
- Python爬蟲之爬取最新更新的小說網站
