前言
辦公中,偶爾會碰到一種情況,需要提取word文檔中的圖片,決定寫這樣一款工具自動提取圖片。
關于腳本的使用:
情景1:如果你拿到的是一個文件夾,所有的word文件都在這個文件夾的子目錄下,深度為1層,你可以直接使用該腳本
情景2:如果你拿到的是一個文件夾,打開之后,里面雜亂無章的充斥著各種文件,你也不確定word文檔都在哪,那么你需要使用Everything來手動提取出所有的word文檔,雖然我也可以讓腳本實現這個功能,但是使用腳本需要考慮到有可能存在同名文件,再處理起來代碼量會更大,還是用Everything手動移動文件吧,誰讓現在的代碼量已經遠超我預期了呢?
3:預處理前面的兩步之后,就可以直接運行腳本了
4:腳本注釋很詳細,這里不再贅述
5:目前僅支持docx格式的,主要原因是,如果支持doc的話,需要把doc轉為docx,轉換略慢,并且,我也用不到。如果你感興趣的話,我再最下面介紹了互轉的方法,你可以把這個函數加進去即可
代碼
import zipfile
import os
import shutil
import hashlib
import send2trash
'''
假設所有的word文檔存放在某路徑中,這個路徑中包含各種雜七雜八的玩意
使用Everything,或者"篩選文件.py"把所有的docx文件移動到C:\\Users\\asuka\\Desktop\\123
逐個解壓每個docx文檔,并提取圖片
強烈建議使用Everything用來篩選出所有的word文檔,這樣假如有兩個重名的文檔,可以手動處理
如果編寫軟件來實現的話,會麻煩很多
'''
# 一個用來解壓文件的函數
def extract_zip(zip_path):
os.chdir(os.path.dirname(zip_path)) # 需要進入到這個路徑下,這樣解壓的文件,才在這個路徑下
a = zipfile.ZipFile(zip_path) # 調用zipfile.ZipFile()函數,創建一個ZipFile對象
a.extractall()
a.close()
os.chdir(path) # 恢復到之前的路徑
# 用來獲取所有的圖片
'''
測試的時候發現,不同word文件解壓之后,里面的圖片命名格式一致,
導致不能直接移動圖片,否則會造成文件覆蓋,這里需要對找到的每一個文件,進行重命名
'''
def get_picture(demo_path):
count = 1 # 用來個圖片進行重命名
for current_folder, list_folders, files in os.walk(demo_path):
for f in files:
if f.endswith('png') or f.endswith('jpg') or f.endswith('jpeg'): # 設置圖片類型是這種
move_f = current_folder + '\\' + f # 給出要移動的文件的路徑
new_file_path = path1 + '\\' + str(count) + '.' + f.rpartition('.')[-1] # 指定新文件的文件路徑,文件名數字遞增,文件后綴
shutil.move(move_f, new_file_path) # 移動文件
count += 1
print('[-] 總共獲取圖片{}張'.format(count - 1))
# 對圖片去重
# 計算每個圖片的md5值,據此進行去重,去重的文件會被刪除到回收站中
def only_one(test_path):
md5_list = []
count = 0
for current_folder, list_folders, files in os.walk(test_path):
for file in files:
picture_path = current_folder + '\\' + file # 獲取每個圖片的路徑
f = open(picture_path, 'rb') # 開始計算每個圖片的md5值
md5obj = hashlib.md5()
md5obj.update(f.read())
get_hash = md5obj.hexdigest()
f.close()
md5_value = str(get_hash).upper()
# 開始去重
if md5_value in md5_list:
send2trash.send2trash(picture_path) # 如果這個文件的md5值曾經出現過,就刪除這張圖片
count += 1
print('[-] 刪除重復圖片:' + str(file))
else:
md5_list.append(md5_value) # 如果這個圖片的md5值不存在列表中,就添加進列表中
print('[-] 共刪除重復圖片:{}張'.format(count))
print('[+] 只有后綴是docx的word文檔才可以提取圖片!!!')
path = input('[+] 請輸入word文檔所在文件夾:') # 獲取原始的word文檔所在路徑
os.chdir(path)
print("[+] 請輸入一個路徑,用來存放所有的圖片")
print("[+] 或者按回車鍵,我將自動把圖片整理之后存放在你的桌面")
path1 = input('') # path1 用來存放所有的圖片文件
if len(path1):
pass
else:
desktop_path = os.path.join(os.path.expanduser("~"), 'Desktop') # 獲取桌面路徑
path1 = os.path.join(desktop_path, '所有word文件中的圖片')
os.makedirs(path1)
files = os.listdir(path) # 獲取指定文件夾下的所有文件
for file in files: # 遍歷指定文件夾下的所有文件
if file.endswith('docx'): # 加一個判斷,這樣即使path路徑下有別的類型文件也無妨
filename = file.rpartition('.')[0] # 獲取文件的文件名
file_path = os.path.join(path, filename)
os.makedirs(file_path) # 為獲取到的文件名創建一個文件夾
shutil.move(file, file_path) # 把word文檔移動到同名文件夾中
word_path = os.path.join(file_path, file) # 獲取此時word文件的文件路徑
extract_zip(word_path) # 不用改后綴,直接解壓docx文件
get_picture(path)
only_one(path1)
print('[-] 現有圖片:{}張'.format(len(os.listdir(path1))))
GIF示例

Everything提取文件的演示(手動處理同名word文件,我這里對同名文件進行替換):

附:doc轉docx
介紹一下實現二者互轉
需要說明的是:
要安裝OFFICE,如果是使用金山WPS的,則還不能應用
轉換速度略慢,但還能接受
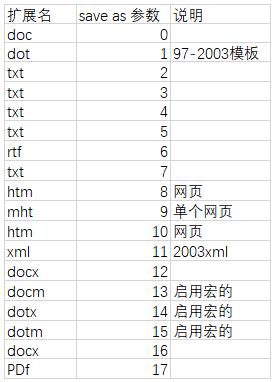
如果想轉換為其他格式文件,需要在format文件名內修改,并用如下save as 參數
代碼
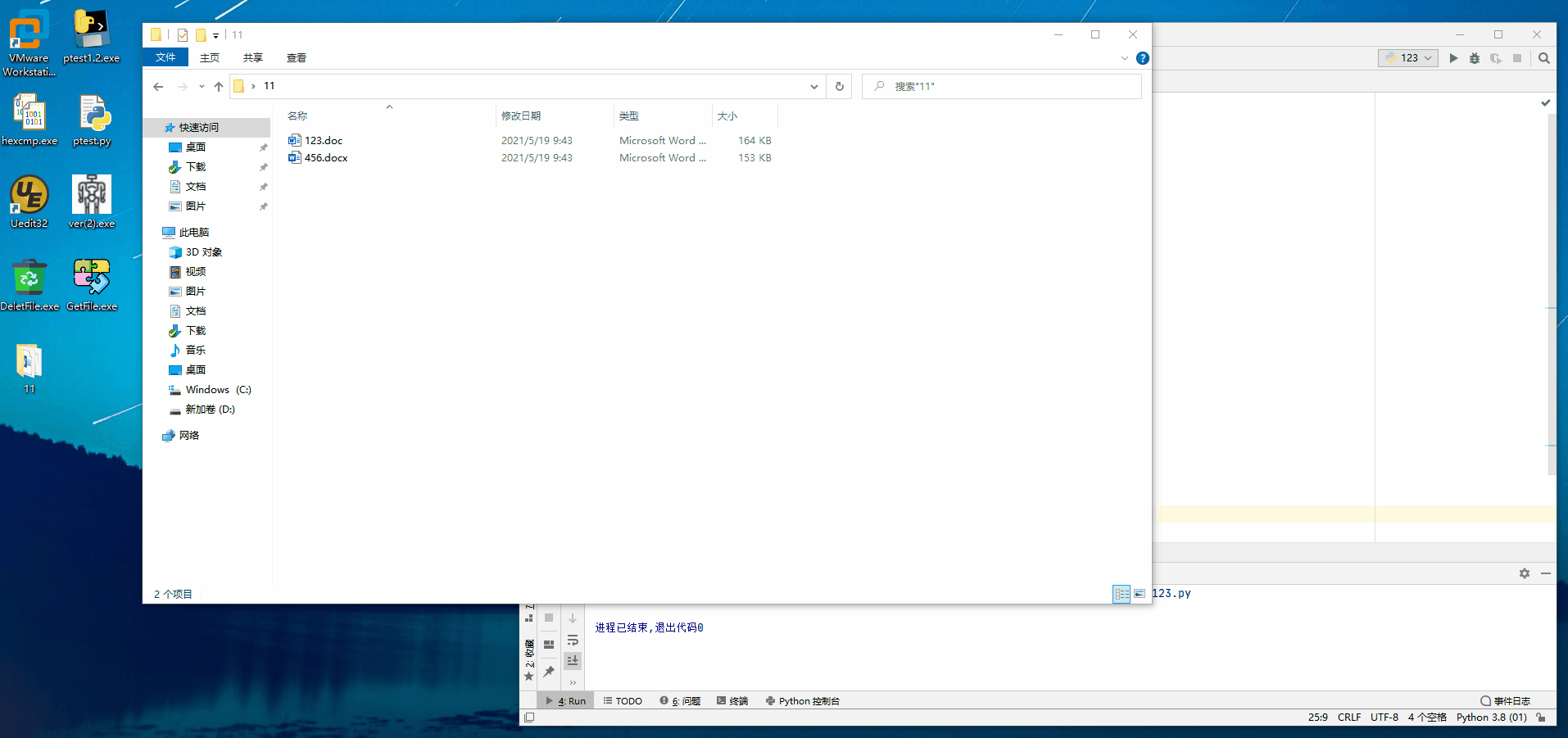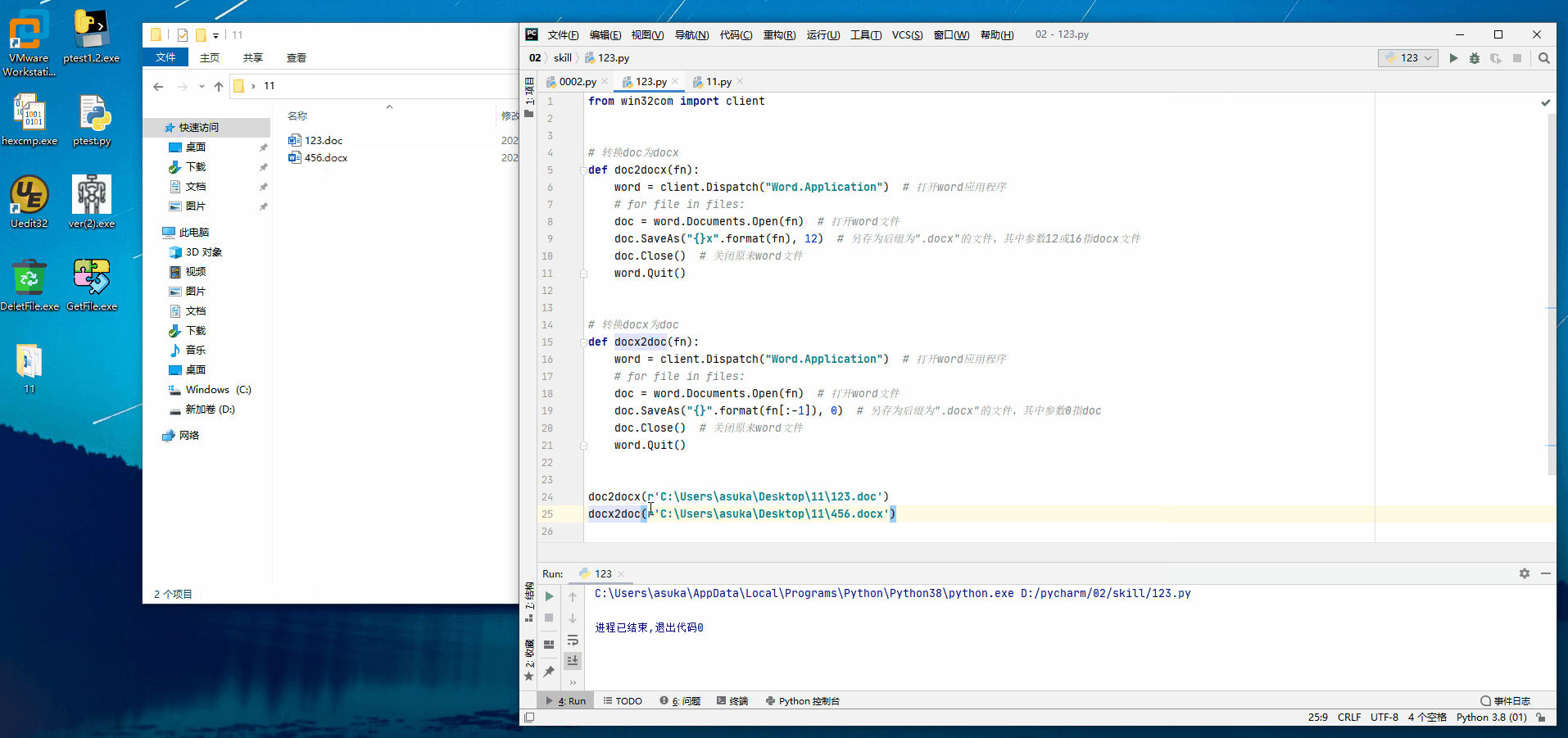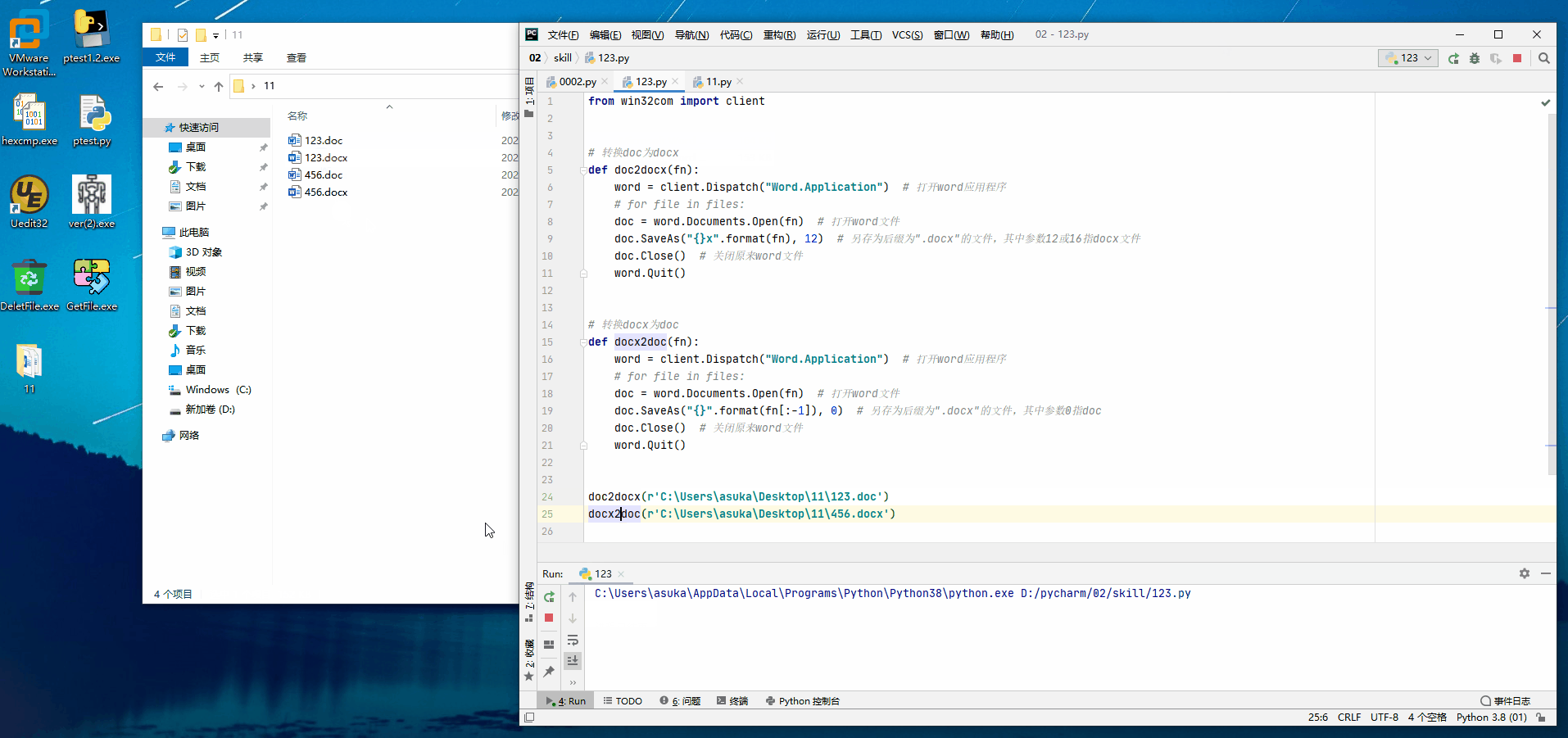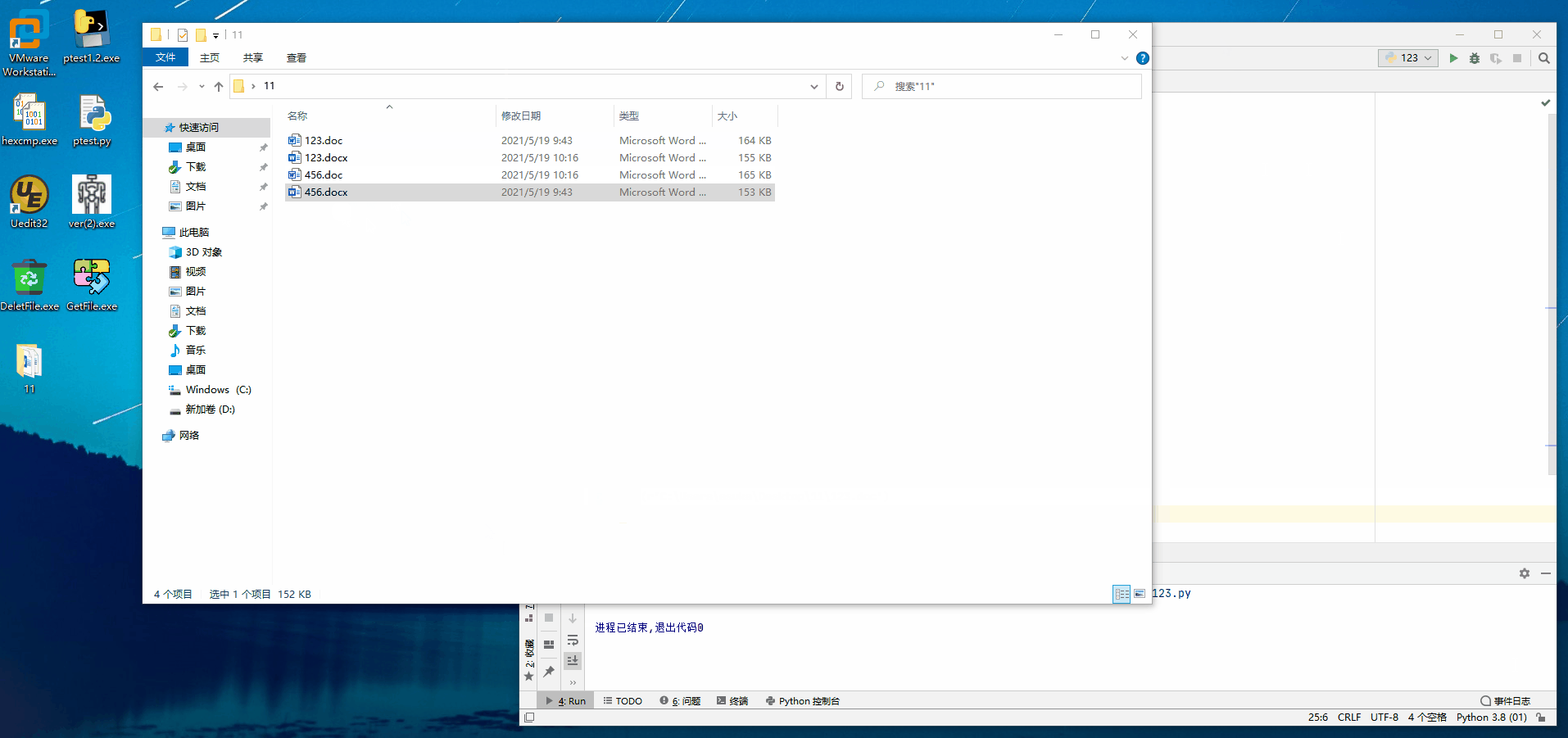
關于第9行、第19行代碼:
第9行doc.SaveAs("{}x".format(fn), 12):
"{}x".format(fn)相當于把C:\Users\asuka\Desktop\11\123.doc變成了C:\Users\asuka\Desktop\11\123.docx,首先是指定了路徑和文件名,然后12表示存儲成docx格式的,保證了后綴名和格式是對應的。
第19行doc.SaveAs("{}".format(fn[:-1]), 0):
"{}".format(fn[:-1])相當于把C:\Users\asuka\Desktop\11\456.docx變成了C:\Users\asuka\Desktop\11\456.doc,指定了要另外保存的文件,保存的路徑和文件名,然后0表示存儲成doc格式的,保證了后綴名和格式是對應的。
from win32com import client
# 轉換doc為docx
def doc2docx(fn):
word = client.Dispatch("Word.Application") # 打開word應用程序
# for file in files:
doc = word.Documents.Open(fn) # 打開word文件
doc.SaveAs("{}x".format(fn), 12) # 另存為后綴為".docx"的文件,其中參數12或16指docx文件
doc.Close() # 關閉原來word文件
word.Quit()
# 轉換docx為doc
def docx2doc(fn):
word = client.Dispatch("Word.Application") # 打開word應用程序
# for file in files:
doc = word.Documents.Open(fn) # 打開word文件
doc.SaveAs("{}".format(fn[:-1]), 0) # 另存為后綴為".docx"的文件,其中參數0指doc
print(fn[:-1])
doc.Close() # 關閉原來word文件
word.Quit()
doc2docx(r'C:\Users\asuka\Desktop\11\123.doc')
docx2doc(r'C:\Users\asuka\Desktop\11\456.docx')
到此這篇關于python提取word文件中的所有圖片的文章就介紹到這了,更多相關python提取word圖片內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- 使用Python 統計文件夾內所有pdf頁數的小工具
- 20行Python代碼實現一款永久免費PDF編輯工具的實現
- 用python 制作圖片轉pdf工具
- Python開發的單詞頻率統計工具wordsworth使用方法
- Python快速優雅的批量修改Word文檔樣式
- 教你如何利用Python批量翻譯英文Word文檔并保留格式
- 詳解用Python把PDF轉為Word方法總結
- 使用python處理一萬份word表格簡歷操作
- python 三種方法提取pdf中的圖片
- 只用40行Python代碼就能寫出pdf轉word小工具
