目錄
- 一、前言
- 二、完全切分
- 三、正向最長匹配
- 四、逆向最長匹配
- 五、雙向最長匹配
一、前言
我們需要分析某句話,就必須檢測該條語句中的詞語。
一般來說,一句話肯定包含多個詞語,它們互相重疊,具體輸出哪一個由自然語言的切分算法決定。常用的切分算法有完全切分、正向最長匹配、逆向最長匹配以及雙向最長匹配。
本篇博文將一一介紹這些常用的切分算法。
二、完全切分
完全切分是指,找出一段文本中的所有單詞。
不考慮效率的話,完全切分算法其實非常簡單。只要遍歷文本中的連續序列,查詢該序列是否在詞典中即可。上一篇我們獲取了詞典的所有詞語dic,這里我們直接用代碼遍歷某段文本,完全切分出所有的詞語。代碼如下:
from pyhanlp import *
def load_dictionary():
IOUtil = JClass('com.hankcs.hanlp.corpus.io.IOUtil')
path = HanLP.Config.CoreDictionaryPath.replace('.txt', '.mini.txt')
dic = IOUtil.loadDictionary([path])
return set(dic.keySet())
def fully_segment(text, dic):
list = []
for i in range(len(text)):
for j in range(i + 1, len(text) + 1):
temp = text[i:j]
if temp in dic:
list.append(temp)
return list
if __name__ == "__main__":
dic = load_dictionary()
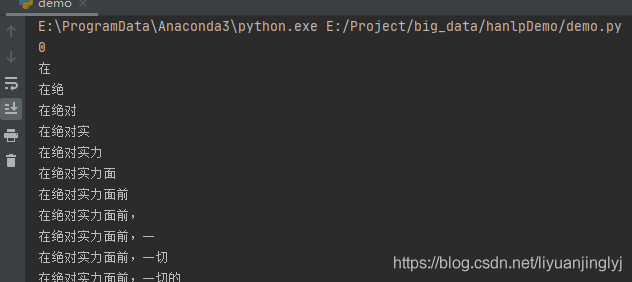
print(fully_segment("在絕對實力面前,一切的說辭都是枉然", dic))

可以看到,完全切分算法輸出了文本中所有的單字與詞匯。
這里的算法原理是:開始遍歷單個字,以該字為首,將后面每個字依次組合到單個字中,分析出這些組合字句是否在詞典中。第二次,從第二個字開始,組合后面的字,以此類推。不懂的看下圖就明白了。
三、正向最長匹配
雖然說完全切分能獲取到所有出現在字典中的單詞,單字,但是我們獲取語句中單字一般來說沒有任何意義,我們更希望獲取的是中文分詞,那種具有意義的詞語序列。
比如,上面我們希望“絕對實力”成為一整個詞,而不是“絕對”+“實力”之類的碎片。為了達到這個目的,我們需要完善一下我們的算法。考慮到越長的單詞表達的意義更加的豐富,于是我們定義單詞越長優先級越高。
具體來說,就是在某個下標為起點遞增查詞的過程中,優先輸出更長的單詞,這種規則被稱為最長匹配算法。該下標的掃描順序如果從前往后,則稱為正向最長匹配,反之則為逆向最長匹配。
下面,我們來實現正向最長匹配,代碼如下:
def forward_segment(text, dic):
list = []
i = 0
while i len(text):
long_word = text[i]
for j in range(i + 1, len(text) + 1):
word = text[i:j]
if word in dic:
if len(word) > len(long_word):
long_word = word
list.append(long_word)
i += len(long_word)
return list
算法的原理:首先通過while循環判斷i是否超出了字符串的大小,如果沒有,獲取當前第一個字符串為第一個最長匹配結果,接著遍歷第一個字符串的所有可能組合結尾,如果在字典中,判斷當前詞語是否大于前面的最長匹配結果,如果是替換掉最長。遍歷完成之后,將最長的結果添加到列表中,然后再獲取第二字符,遍歷所有結尾組合,獲取最長匹配。以此類推。
四、逆向最長匹配
既然了解了正向如何匹配,那么逆向算法應該也很好寫。代碼如下:
def backward_segment(text, dic):
list = []
i = len(text) - 1
while i >= 0:
long_word = text[i]
for j in range(0, i):
word = text[j:i + 1]
if word in dic:
if len(word) > len(long_word):
long_word = word
break
list.append(long_word)
i -= len(long_word)
return list
算法的原理:就是上面的正向反過來,但是這里并不是倒推文字,文字還是按語句的順序,但是長度是從最長到最短,也就是遇到第一個就可以返回了添加了。比正向最長匹配算法節約時間。
五、雙向最長匹配
雖然逆向比正向節約時間,但本身有一個很大的漏洞。假如我現在的句子中有一段“項目的”字符串,那么正向會出現“項目”,“的”兩個詞匯,而逆向會出現:“項”,“目的”兩個詞匯。
為此,我們的算法工程師提出了新的匹配規則,雙向最長匹配。這是一種融合兩種匹配方法的復雜規則,流程如下:
同時執行正向和逆向最長匹配,若兩者的詞數不同,則返回詞數更少的一個否則,返回兩者中單字更少的那一個。當單字也相同時,優先返回逆向最長匹配結果
具體代碼如下:
#統計單字個數
def count_single_char(list):
return sum(1 for word in list if len(word) == 1)
#雙向匹配算法
def bidirectional_segment():
f = forward_segment("在絕對實力面前,一切的說辭都是枉然", dic)
b = backward_segment("在絕對實力面前,一切的說辭都是枉然", dic)
if len(f) len(b):
return f
elif len(f) > len(b):
return b
else:
if count_single_char(f)count_single_char(b):
return f
else:
return b
到此這篇關于Python自然語言處理之切分算法詳解的文章就介紹到這了,更多相關python切分算法內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python 算法題——快樂數的多種解法
- python使用ProjectQ生成量子算法指令集
- Python機器學習算法之決策樹算法的實現與優缺點
- Python集成學習之Blending算法詳解
- python3實現Dijkstra算法最短路徑的實現
- Python實現K-means聚類算法并可視化生成動圖步驟詳解
- python入門之算法學習
- Python實現機器學習算法的分類
