| 解析器 | 使用方法 | 條件 |
|---|---|---|
| bs4的html解析器 | BeautifulSoup(demo,‘html.parser') | 安裝bs4庫 |
| lxml的html解析器 | BeautifulSoup(demo,‘lxml') | pip install lxml |
| lxml的xml解析器 | BeautifulSoup(demo,‘xml') | pip install lxml |
| html5lib的解析器 | BeautifulSoup(demo,‘html5lib') | pip install html5lib |
假如有一個簡單的網頁,提取百度搜索頁面的一部分源代碼為例
!DOCTYPE html> html> head> meta content="text/html;charset=utf-8" http-equiv="content-type" /> meta content="IE=Edge" http-equiv="X-UA-Compatible" /> meta content="always" name="referrer" /> link href="https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min. css" rel="stylesheet" type="text/css" /> title>百度一下,你就知道 /title> /head> body link="#0000cc"> div > div > div > div > a rel="external nofollow" rel="external nofollow" name="tj_trnews">新聞 /a> a rel="external nofollow" name="tj_trhao123">hao123 /a> a rel="external nofollow" name="tj_trmap">地圖 /a> a rel="external nofollow" name="tj_trvideo">視頻 /a> a rel="external nofollow" name="tj_trtieba">貼吧 /a> a rel="external nofollow" name="tj_briicon" >更多產品 /a> /div> /div> /div> /div> /body> /html>
結合requests庫和使用BeautifulSoup庫的html解析器,對其進行解析有如下
import requests
from bs4 import BeautifulSoup
# 使用Requests庫加載頁面代碼
r = requests.get('https://www.baidu.com')
r.raise_for_status() # 狀態碼返回
r.encoding = r.apparent_encoding
demo = r.text
# 使用BeautifulSoup庫解析代碼
soup = BeautifulSoup(demo,'html.parser') # 使用html的解析器
print(soup.prettify()) # prettify 方式輸出頁面
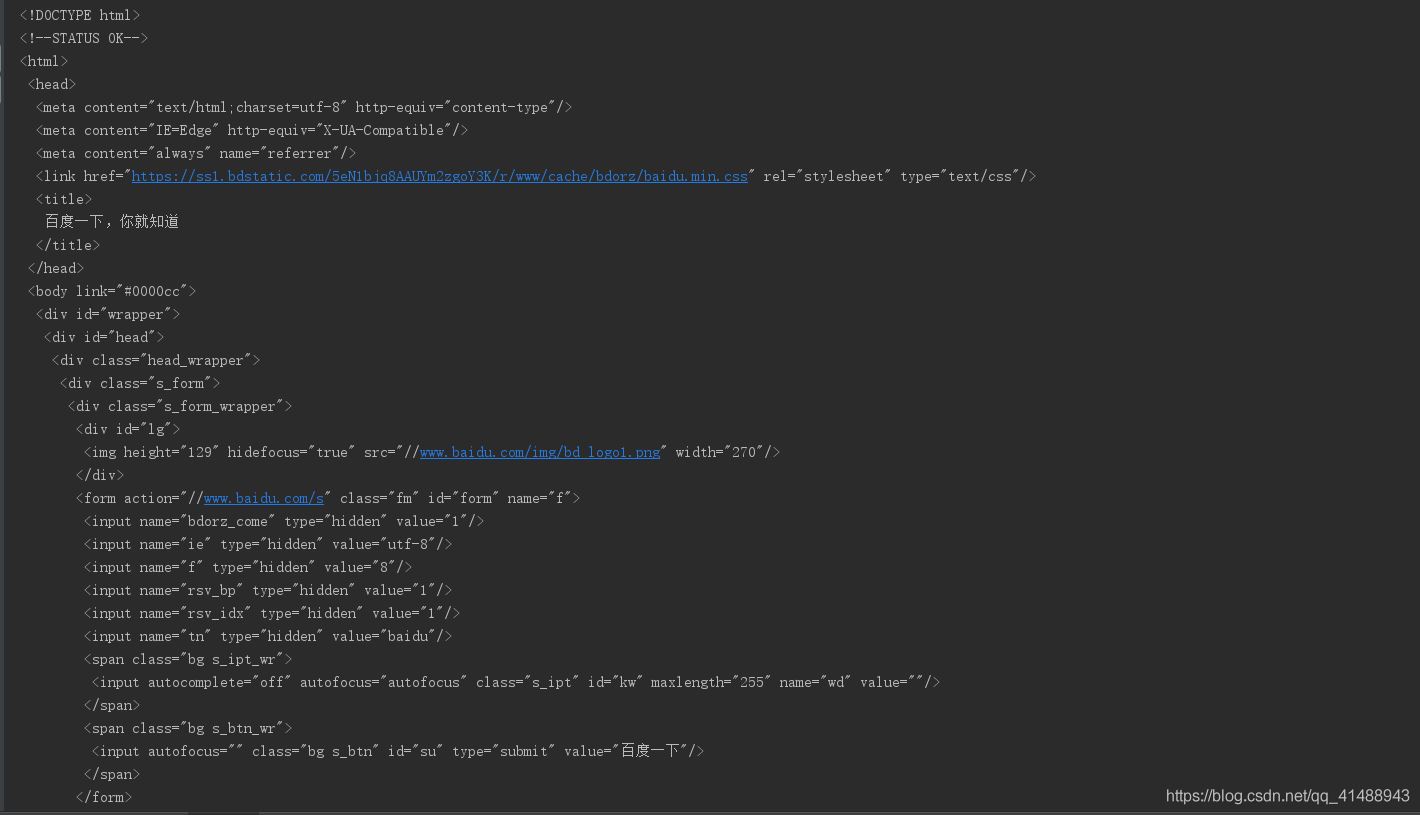
BeautifulSoup4將復雜HTML文檔轉換成一個復雜的樹形結構,每個節點都是Python對象,BeautifulSoup庫有針對于html的標簽數的特定元素,重點有如下三種
p > ... /p>
| 基本元素 | 說明 |
|---|---|
| Tag | 標簽,最基本的信息組織單元,分別用>和/>標明開頭和結尾,格式:soup.a或者soup.p(獲取a標簽中或者p標簽中的內容) |
| Name | 標簽的名字,
… 的名字是‘p' 格式為:.name |
| Attributes | 標簽的屬性,字典形式組織,格式:.attrs |
| NavigableString | 標簽內非屬性字符串,>…/>中的字符串,格式:.string |
| Comment | 標簽內的字符串的注釋部分,一種特殊的Comment類型 |
標簽是html中的最基本的信息組織單元,使用方式如下
from bs4 import BeautifulSoup html = 'https://www.baidu.com' bs = BeautifulSoup(html,"html.parser") print(bs.title) # 獲取title標簽的所有內容 print(bs.head) # 獲取head標簽的所有內容 print(bs.a) # 獲取第一個a標簽的所有內容 print(type(bs.a)) # 類型
在Tag標簽中最重要的就是html頁面中的name哈attrs屬性,使用方式如下
print(bs.name)
print(bs.head.name) # head 之外對于其他內部標簽,輸出的值便為標簽本身的名稱
print(bs.a.attrs) # 把 a 標簽的所有屬性打印輸出了出來,得到的類型是一個字典。
print(bs.a['class']) # 等價 bs.a.get('class') 也可以使用get方法,傳入屬性的名稱,二者是等價的
bs.a['class'] = "newClass" # 對這些屬性和內容進行修改
print(bs.a)
del bs.a['class'] # 對這個屬性進行刪除
print(bs.a)
NavigableString中的string方法用于獲取標簽內部的文字
from bs4 import BeautifulSoup html = 'https://www.baidu.com' bs = BeautifulSoup(html,"html.parser") print(bs.title.string) print(type(bs.title.string))
Comment 對象是一個特殊類型的 NavigableString 對象,其輸出的內容不包括注釋符號,用于輸出注釋中的內容
from bs4 import BeautifulSoup html = 'https://www.baidu.com' bs = BeautifulSoup(html,"html.parser") print(bs.a) # 標簽中的內容a rel="external nofollow" rel="external nofollow" name="tj_trnews">!--新聞-->/a> print(bs.a.string) # 新聞 print(type(bs.a.string)) # class 'bs4.element.Comment'>
在HTML中有如下特定的基本格式,也是構成HTML頁面的基本組成成分
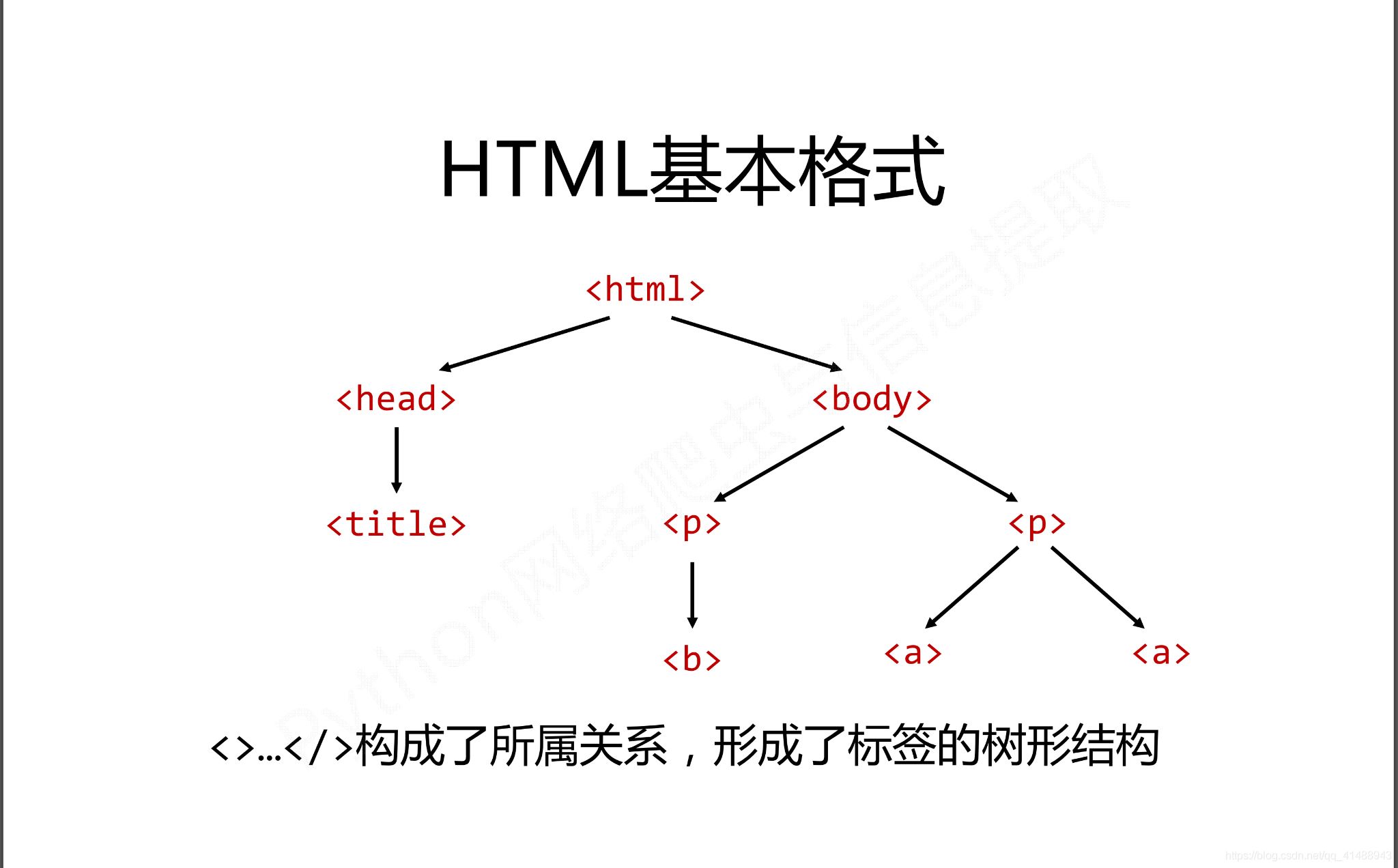
而在這種基本的格式下有三種基本的遍歷流程
三種種遍歷方式分別是從當前節點出發。對之上或者之下或者平行的格式以及關系進行遍歷
下行遍歷有三種遍歷的屬性,分別是
| 屬性 | 說明 |
|---|---|
| .contents | 子節點的列表,將所有兒子節點存入列表 |
| .children | 子節點的迭代類型,用于循環遍歷兒子節點 |
| .descendants | 子孫節點的迭代類型,包含所有子孫節點,用于循環遍歷 |
使用舉例
soup = BeautifulSoup(demo,'html.parser') # 循環遍歷兒子節點 for child in soup.body.children: print(child) # 循環遍歷子孫節點 for child in soup.body.descendants: print(child) # 輸出子節點的列表形式 print(soup.head.contents) print(soup.head.contents[1]) # 用列表索引來獲取它的某一個元素
上行遍歷有兩種方式
| 屬性 | 說明 |
|---|---|
| .parent | 節點的父親標簽 |
| .parents | 節點先輩標簽的迭代類型,用于循環遍歷先輩節點,返回一個生成器 |
soup = BeautifulSoup(demo,'html.parser') for parent in soup.a.parents: if parent is None: parent(parent) else: print(parent.name)
平行遍歷有四種屬性
| 屬性 | 說明 |
|---|---|
| .next_sibling | 返回按照HTML文本順序的下一個平行節點標簽 |
| .previous_sibling | 返回按照HTML文本順序的上一個平行節點標簽 |
| .next_siblings | 迭代類型,返回按照html文本順序的后續所有平行節點標簽 |
| .previous_siblings | 迭代類型,返回按照html文本順序的前序所有平行節點標簽 |
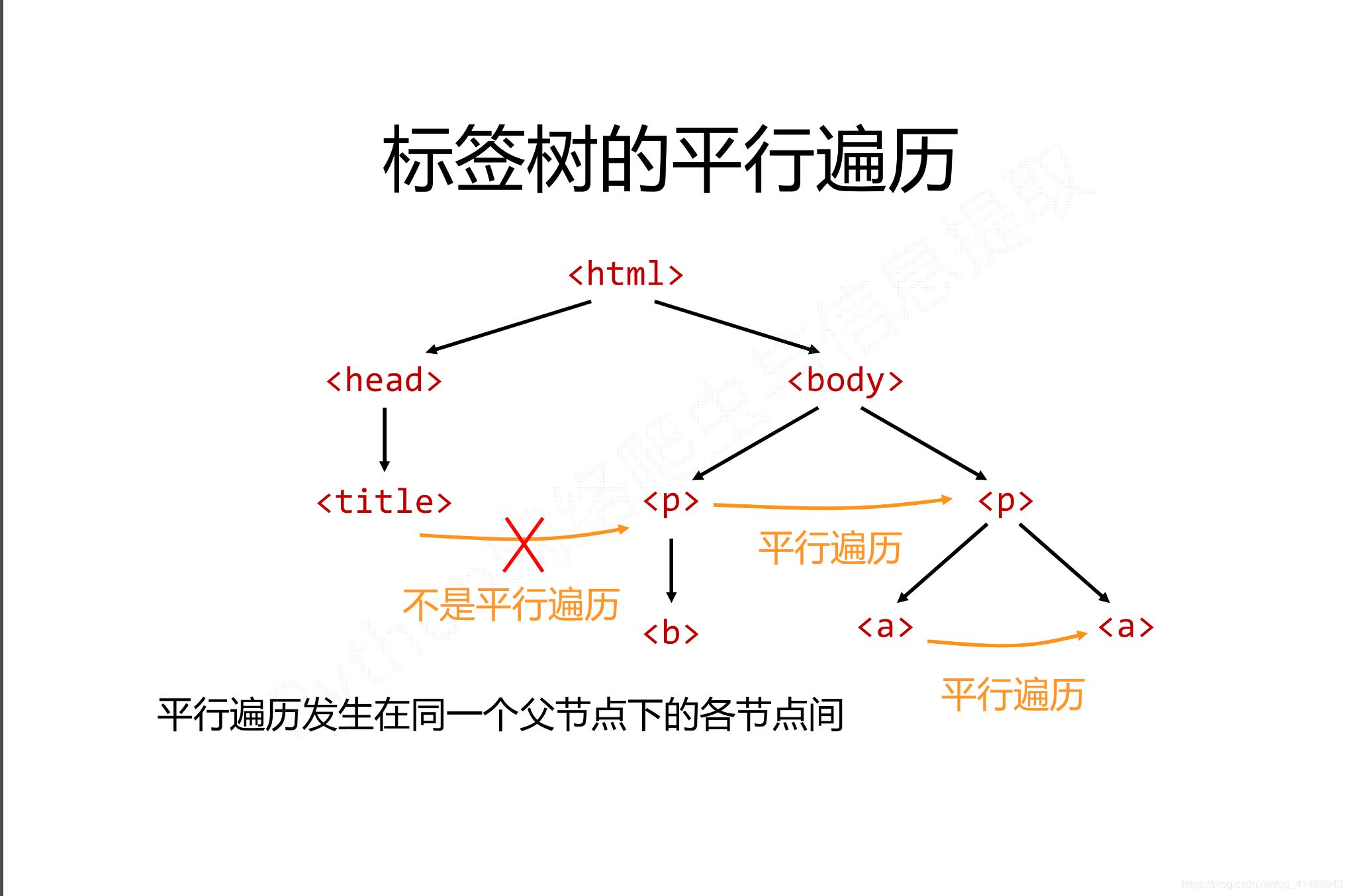
平行遍歷舉例如下
for sibling in soup.a.next_sibling: print(sibling) # 遍歷后續節點 for sibling in soup.a.previous_sibling: print(sibling) # 遍歷
| 屬性 | 說明 |
|---|---|
| .strings | 如果Tag包含多個字符串,即在子孫節點中有內容,可以用此獲取,而后進行遍歷 |
| .stripped_strings | 與strings用法一致,可以去除掉那些多余的空白內容 |
| .has_attr | 判斷Tag是否包含屬性 |
使用soup.find_all(name,attrs,recursive,string,**kwargs)方法,用于返回一個列表類型,存儲查找的結果
如果是指定的字符串:會查找與字符串完全匹配的內容,如下
a_list = bs.find_all("a")
print(a_list) # 將會返回所有包含a標簽的內容
如果是使用正則表達式:將會使用BeautifulSoup4中的search()方法來匹配內容,如下
from bs4 import BeautifulSoup
import re
html = 'https://www.baidu.com'
bs = BeautifulSoup(html,"html.parser")
t_list = bs.find_all(re.compile("a"))
for item in t_list:
print(item) # 輸出列表
如果傳入一個列表:BeautifulSoup4將會與列表中的任一元素匹配到的節點返回,如下
t_list = bs.find_all(["meta","link"]) for item in t_list: print(item)
如果傳入一個函數或者方法:將會根據函數或者方法來匹配
from bs4 import BeautifulSoup
html = 'https://www.baidu.com'
bs = BeautifulSoup(html,"html.parser")
def name_is_exists(tag):
return tag.has_attr("name")
t_list = bs.find_all(name_is_exists)
for item in t_list:
print(item)
并不是所有的屬性都可以使用上面這種方式進行搜索,比如HTML的data屬性,用于指定屬性搜索
t_list = bs.find_all(data-foo="value")
通過通過string參數可以搜索文檔中的字符串內容,與name參數的可選值一樣,string參數接受字符串,正則表達式,列表
from bs4 import BeautifulSoup
import re
html = 'https://www.baidu.com'
bs = BeautifulSoup(html, "html.parser")
t_list = bs.find_all(attrs={"data-foo": "value"})
for item in t_list:
print(item)
t_list = bs.find_all(text="hao123")
for item in t_list:
print(item)
t_list = bs.find_all(text=["hao123", "地圖", "貼吧"])
for item in t_list:
print(item)
t_list = bs.find_all(text=re.compile("\d"))
for item in t_list:
print(item)
使用find_all()方法的時,常用到正則表達式的形式import re如下所示
soup.find_all(sring = re.compile('pyhton')) # 指定查找內容
# 或者指定使用正則表達式要搜索的內容
sring = re.compile('pyhton') # 字符為python
soup.find_all(string) # 調用方法模板

此文列舉了BeautifulSoup庫在爬蟲中的基本使用,不正確之處望指教,參考
到此這篇關于python爬蟲beautifulsoup庫使用操作教程全解(python爬蟲基礎入門)的文章就介紹到這了,更多相關python爬蟲beautifulsoup庫內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
標簽:平頂山 哈爾濱 烏蘭察布 海南 合肥 郴州 大慶 烏蘭察布
巨人網絡通訊聲明:本文標題《python爬蟲beautifulsoup庫使用操作教程全解(python爬蟲基礎入門)》,本文關鍵詞 python,爬蟲,beautifulsoup,庫,;如發現本文內容存在版權問題,煩請提供相關信息告之我們,我們將及時溝通與處理。本站內容系統采集于網絡,涉及言論、版權與本站無關。
上一篇:python繪制高斯曲線