Go語言在進行文件操作的時候,可以有多種方法。最常見的比如直接對文件本身進行Read和Write; 除此之外,還可以使用bufio庫的流式處理以及分片式處理;如果文件較小,使用ioutil也不失為一種方法。
面對這么多的文件處理的方式,那么初學者可能就會有困惑:我到底該用那種?它們之間有什么區別?筆者試著從文件讀取來對go語言的幾種文件處理方式進行分析。
os.File、bufio、ioutil比較
效率測試
文件的讀取效率是所有開發者都會關心的話題,尤其是當文件特別大的時候。為了盡可能的展示這三者對文件讀取的性能,我準備了三個文件,分別為small.txt,midium.txt、large.txt,分別對應KB級別、MB級別和GB級別。

這三個文件大小分別為4KB、21MB、1GB。其中內容是比較常規的json格式的文本。
測試代碼如下:
//使用File自帶的Read
func read1(filename string) int {
fi, err := os.Open(filename)
if err != nil {
panic(err)
}
defer fi.Close()
buf := make([]byte, 4096)
var nbytes int
for {
n, err := fi.Read(buf)
if err != nil err != io.EOF {
panic(err)
}
if n == 0 {
break
}
nbytes += n
}
return nbytes
}
read1函數使用的是os庫對文件進行直接操作,為了確定確實都到了文件內容,并將讀到的大小字節數返回。
//使用bufio
func read2(filename string) int {
fi, err := os.Open(filename)
if err != nil {
panic(err)
}
defer fi.Close()
buf := make([]byte, 4096)
var nbytes int
rd := bufio.NewReader(fi)
for {
n, err := rd.Read(buf)
if err != nil err != io.EOF {
panic(err)
}
if n == 0 {
break
}
nbytes += n
}
return nbytes
}
read2函數使用的是bufio庫,操作NewReader對文件進行流式處理,和前面一樣,為了確定確實都到了文件內容,并將讀到的大小字節數返回。
//使用ioutil
func read3(filename string) int {
fi, err := os.Open(filename)
if err != nil {
panic(err)
}
defer fi.Close()
fd, err := ioutil.ReadAll(fi)
nbytes := len(fd)
return nbytes
}
read3函數是使用ioutil庫進行文件讀取,這種方式比較暴力,直接將文件內容一次性全部讀到內存中,然后對內存中的文件內容進行相關的操作。
我們使用如下的測試代碼進行測試:
func testfile1(filename string) {
fmt.Printf("============test1 %s ===========\n", filename)
start := time.Now()
size1 := read1(filename)
t1 := time.Now()
fmt.Printf("Read 1 cost: %v, size: %d\n", t1.Sub(start), size1)
size2 := read2(filename)
t2 := time.Now()
fmt.Printf("Read 2 cost: %v, size: %d\n", t2.Sub(t1), size2)
size3 := read3(filename)
t3 := time.Now()
fmt.Printf("Read 3 cost: %v, size: %d\n", t3.Sub(t2), size3)
}
在main函數中調用如下:
func main() {
testfile1("small.txt")
testfile1("midium.txt")
testfile1("large.txt")
// testfile2("small.txt")
// testfile2("midium.txt")
// testfile2("large.txt")
}
測試結果如下所示:
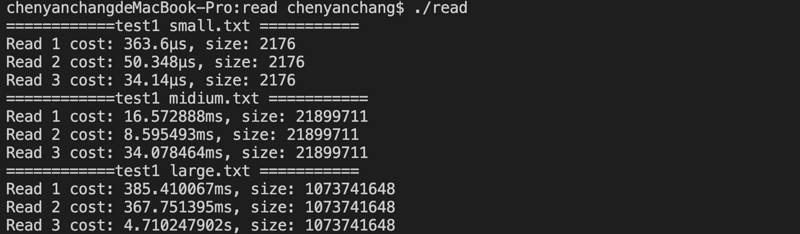
從以上結果可知:
原因分析
為什么會出現上面的不同結果?
其實ioutil最好理解,當文件較小時,ioutil使用ReadAll函數將文件中所有內容直接讀入內存,只進行了一次io操作,但是os和bufio都是進行了多次讀取,才將文件處理完,所以ioutil肯定要快于os和bufio的。
但是隨著文件的增大,達到接近GB級別時,ioutil直接讀入內存的弊端就顯現出來,要將GB級別的文件內容全部讀入內存,也就意味著要開辟一塊GB大小的內存用來存放文件數據,這對內存的消耗是非常大的,因此效率就慢了下來。
如果文件繼續增大,達到3GB甚至以上,ioutil這種讀取方式就完全無能為力了。(一個單獨的進程空間為4GB,真正存放數據的堆區和棧區更是遠遠小于4GB)。
而os為什么在面對大文件時,效率會低于bufio?通過查看bufio的NewReader源碼不難發現,在NewReader里,默認為我們提供了一個大小為4096的緩沖區,所以系統調用會每次先讀取4096字節到緩沖區,然后rd.Read會從緩沖區去讀取。
const (
defaultBufSize = 4096
)
func NewReader(rd io.Reader) *Reader {
return NewReaderSize(rd, defaultBufSize)
}
func NewReaderSize(rd io.Reader, size int) *Reader {
// Is it already a Reader?
b, ok := rd.(*Reader)
if ok len(b.buf) >= size {
return b
}
if size minReadBufferSize {
size = minReadBufferSize
}
r := new(Reader)
r.reset(make([]byte, size), rd)
return r
}
而os因為少了這一層緩沖區,每次讀取,都會執行系統調用,因此內核頻繁的在用戶態和內核態之間切換,而這種切換,也是需要消耗的,故而會慢于bufio的讀取方式。
筆者翻閱網上資料,關于緩沖,有內核中的緩沖和進程中的緩沖兩種,其中,內核中的緩沖是內核提供的,即系統對磁盤提供一個緩沖區,不管有沒有提供進程中的緩沖,內核緩沖都是存在的。
而進程中的緩沖是對輸入輸出流做了一定的改進,提供的一種流緩沖,它在讀寫操作發生時,先將數據存入流緩沖中,只有當流緩沖區滿了或者刷新(如調用flush函數)時,才將數據取出,送往內核緩沖區,它起到了一定的保護內核的作用。
因此,我們不難發現,os是典型的內核中的緩沖,而bufio和ioutil都屬于進程中的緩沖。
總結
當讀取小文件時,使用ioutil效率明顯優于os和bufio,但如果是大文件,bufio讀取會更快。
讀取一行數據
前面簡要分析了go語言三種不同讀取文件方式之間的區別。但實際的開發中,我們對文件的讀取往往是以行為單位的,即每次讀取一行進行處理。
go語言并沒有像C語言一樣給我們提供好了類似于fgets這樣的函數可以正好讀取一行內容,因此,需要自己去實現。
從前面的對比分析可以知道,無論是處理大文件還是小文件,bufio始終是最為平滑和高效的,因此我們考慮使用bufio庫進行處理。
翻閱bufio庫的源碼,發現可以使用如下幾種方式進行讀取一行文件的處理:
效率測試
在討論這四種讀取一行文件操作的函數之前,仍然做一下效率測試。
測試代碼如下:
func readline1(filename string) {
fi, err := os.Open(filename)
if err != nil {
panic(err)
}
defer fi.Close()
rd := bufio.NewReader(fi)
for {
_, err := rd.ReadBytes('\n')
if err != nil || err == io.EOF {
break
}
}
}
func readline2(filename string) {
fi, err := os.Open(filename)
if err != nil {
panic(err)
}
defer fi.Close()
rd := bufio.NewReader(fi)
for {
_, err := rd.ReadString('\n')
if err != nil || err == io.EOF {
break
}
}
}
func readline3(filename string) {
fi, err := os.Open(filename)
if err != nil {
panic(err)
}
defer fi.Close()
rd := bufio.NewReader(fi)
for {
_, err := rd.ReadSlice('\n')
if err != nil || err == io.EOF {
break
}
}
}
func readline4(filename string) {
fi, err := os.Open(filename)
if err != nil {
panic(err)
}
defer fi.Close()
rd := bufio.NewReader(fi)
for {
_, _, err := rd.ReadLine()
if err != nil || err == io.EOF {
break
}
}
}
可以看到,這四種操作方式,無論是函數調用,還是函數返回值的處理,其實都是大同小異的。但通過測試效率,則可以看出它們之間的區別。
我們使用下面的測試代碼:
func testfile2(filename string) {
fmt.Printf("============test2 %s ===========\n", filename)
start := time.Now()
readline1(filename)
t1 := time.Now()
fmt.Printf("Readline 1 cost: %v\n", t1.Sub(start))
readline2(filename)
t2 := time.Now()
fmt.Printf("Readline 2 cost: %v\n", t2.Sub(t1))
readline3(filename)
t3 := time.Now()
fmt.Printf("Readline 3 cost: %v\n", t3.Sub(t2))
readline4(filename)
t4 := time.Now()
fmt.Printf("Readline 4 cost: %v\n", t4.Sub(t3))
}
在main函數中調用如下:
func main() {
// testfile1("small.txt")
// testfile1("midium.txt")
// testfile1("large.txt")
testfile2("small.txt")
testfile2("midium.txt")
testfile2("large.txt")
}
運行結果如下所示:
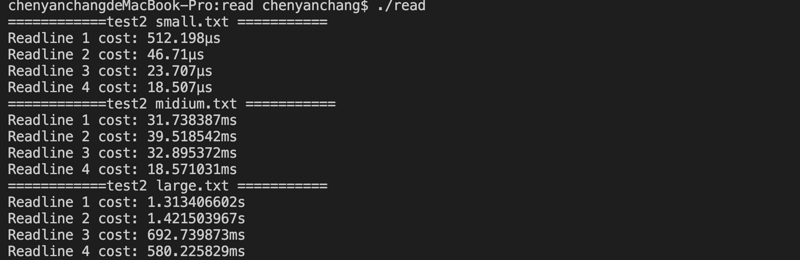
通過現象,除了small.txt之外,大致可以分為兩組:
原因分析
為什么會出現上面的現象,不防從源碼層面進行分析。
通過閱讀源碼,我們發現這四個函數之間存在這樣一個關系:
既然如此,那為什么在處理大文件時,ReadLine效率要明顯高于ReadBytes呢?
首先,我們要知道,ReadSlice是切片式讀取,即根據分隔符去進行切片。
通過源碼發下,ReadLine只是在切片讀取的基礎上,對換行符\n和\r\n做了一些處理:
func (b *Reader) ReadLine() (line []byte, isPrefix bool, err error) {
line, err = b.ReadSlice('\n')
if err == ErrBufferFull {
// Handle the case where "\r\n" straddles the buffer.
if len(line) > 0 line[len(line)-1] == '\r' {
// Put the '\r' back on buf and drop it from line.
// Let the next call to ReadLine check for "\r\n".
if b.r == 0 {
// should be unreachable
panic("bufio: tried to rewind past start of buffer")
}
b.r--
line = line[:len(line)-1]
}
return line, true, nil
}
if len(line) == 0 {
if err != nil {
line = nil
}
return
}
err = nil
if line[len(line)-1] == '\n' {
drop := 1
if len(line) > 1 line[len(line)-2] == '\r' {
drop = 2
}
line = line[:len(line)-drop]
}
return
}
而ReadBytes則是通過append先將讀取的內容暫存到full數組中,最后再copy出來,append和copy都是要消耗內存和io的,因此效率自然就慢了。其源碼如下所示:
func (b *Reader) ReadBytes(delim byte) ([]byte, error) {
// Use ReadSlice to look for array,
// accumulating full buffers.
var frag []byte
var full [][]byte
var err error
n := 0
for {
var e error
frag, e = b.ReadSlice(delim)
if e == nil { // got final fragment
break
}
if e != ErrBufferFull { // unexpected error
err = e
break
}
// Make a copy of the buffer.
buf := make([]byte, len(frag))
copy(buf, frag)
full = append(full, buf)
n += len(buf)
}
n += len(frag)
// Allocate new buffer to hold the full pieces and the fragment.
buf := make([]byte, n)
n = 0
// Copy full pieces and fragment in.
for i := range full {
n += copy(buf[n:], full[i])
}
copy(buf[n:], frag)
return buf, err
}
總結
讀取文件中一行內容時,ReadSlice和ReadLine性能優于ReadBytes和ReadString,但由于ReadLine對換行的處理更加全面(兼容\n和\r\n換行),因此,實際開發過程中,建議使用ReadLine函數。
到此這篇關于Go語言文件讀取的一些總結的文章就介紹到這了,更多相關Go語言文件讀取內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
標簽:阿克蘇 太原 調研邀請 西雙版納 德州 貴陽 慶陽 廣西
巨人網絡通訊聲明:本文標題《Go語言文件讀取的一些總結》,本文關鍵詞 語言,文件,讀,取的,一些,;如發現本文內容存在版權問題,煩請提供相關信息告之我們,我們將及時溝通與處理。本站內容系統采集于網絡,涉及言論、版權與本站無關。



