1. map的使用
golang中的map是一種數據類型,將鍵與值綁定到一起,底層是用哈希表實現的,可以快速的通過鍵找到對應的值。
類型表示:map[keyType][valueType] key一定要是可比較的類型(可以理解為支持==的操作),value可以是任意類型。
初始化:map只能使用make來初始化,聲明的時候默認為一個為nil的map,此時進行取值,返回的是對應類型的零值(不存在也是返回零值)。添加元素無任何意義,還會導致運行時錯誤。向未初始化的map賦值引起 panic: assign to entry in nil map。
package main
import (
"fmt"
)
// bool 的零值是false
var m map[int]bool
a, ok := m[1]
fmt.Println(a, ok) // false false
// int 的零值是0
var m map[int]int
a, ok := m[1]
fmt.Println(a, ok) // 0 false
func main() {
var agemap[string]int
if age== nil {
fmt.Println("map is nil.")
age= make(map[string]int)
}
}
清空map:對于一個有一定數據的集合 exp,清空的辦法就是再次初始化: exp = make(map[string]int),如果后期不再使用該map,則可以直接:exp= nil 即可,但是如果還需要重復使用,則必須進行make初始化,否則無法為nil的map添加任何內容。
屬性:與切片一樣,map 是引用類型。當一個 map 賦值給一個新的變量,它們都指向同一個內部數據結構。因此改變其中一個也會反映到另一個。作為形參或返回參數的時候,傳遞的是地址的拷貝,擴容時也不會改變這個地址。
func main() {
exp := map[string]int{
"steve": 20,
"jamie": 80,
}
fmt.Println("Ori exp", age)
newexp:= exp
newexp["steve"] = 18
fmt.Println("exp changed", exp)
}
//Ori age map[steve:20 jamie:80]
//age changed map[steve:18 jamie:80]
遍歷map:map本身是無序的,在遍歷的時候并不會按照你傳入的順序,進行傳出。
//正常遍歷:
for k, v := range exp {
fmt.Println(k, v)
}
//有序遍歷
import "sort"
var keys []string
// 把key單獨抽取出來,放在數組中
for k, _ := range exp {
keys = append(keys, k)
}
// 進行數組的排序
sort.Strings(keys)
// 遍歷數組就是有序的了
for _, k := range keys {
fmt.Println(k, m[k])
}
2.map的結構
Go中的map在可以在 $GOROOT/src/runtime/map.go找到它的實現。哈希表的數據結構中一些關鍵的域如下所示:
type hmap struct {
count int //元素個數
flags uint8
B uint8 //擴容常量
noverflow uint16 //溢出 bucket 個數
hash0 uint32 //hash 種子
buckets unsafe.Pointer //bucket 數組指針
oldbuckets unsafe.Pointer //擴容時舊的buckets 數組指針
nevacuate uintptr //擴容搬遷進度
extra *mapextra //記錄溢出相關
}
type bmap struct {
tophash [bucketCnt]uint8
// Followed by bucketCnt keys
//and then bucketan Cnt values
// Followed by overflow pointer.
}
說明:每個map的底層都是hmap結構體,它是由若干個描述hmap結構體的元素、數組指針、extra等組成,buckets數組指針指向由若干個bucket組成的數組,其每個bucket里存放的是key-value數據(通常是8個)和overflow字段(指向下一個bmap),每個key插入時會根據hash算法歸到同一個bucket中,當一個bucket中的元素超過8個的時候,hmap會使用extra中的overflow來擴展存儲key。
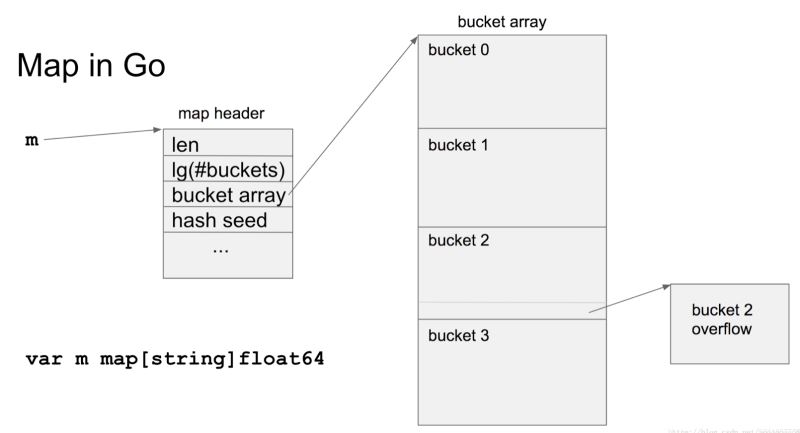
圖中len 就是當前map的元素個數,也就是len()返回的值。也是結構體中hmap.count的值。bucket array是指數組指針,指向bucket數組。hash seed 哈希種子。overflow指向下一個bucket。
map的底層主要是由三個結構構成:
hmap --- map的最外層的數據結構,包括了map的各種基礎信息、如大小、bucket,一個大的結構體。 mapextra --- 記錄map的額外信息,hmap結構體里的extra指針指向的結構,例如overflow bucket。 bmap --- 代表bucket,每一個bucket最多放8個kv,最后由一個overflow字段指向下一個bmap,注意key、value、overflow字段都不顯示定義,而是通過maptype計算偏移獲取的。
mapextra的結構如下
// mapextra holds fields that are not present on all maps.
type mapextra struct {
// If both key and value do not contain pointers and are inline, then we mark bucket
// type as containing no pointers. This avoids scanning such maps.
// However, bmap.overflow is a pointer. In order to keep overflow buckets
// alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow.
// overflow and oldoverflow are only used if key and value do not contain pointers.
// overflow contains overflow buckets for hmap.buckets.
// oldoverflow contains overflow buckets for hmap.oldbuckets.
// The indirection allows to store a pointer to the slice in hiter.
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow holds a pointer to a free overflow bucket.
nextOverflow *bmap
}
其中hmap.extra.nextOverflow指向的是預分配的overflow bucket,預分配的用完了那么值就變成nil。
bmap的詳細結構如下
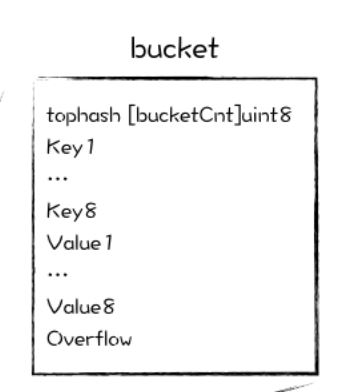
在map中出現哈希沖突時,首先以bmap為最小粒度掛載,一個bmap累積8個kv之后,就會申請一個新的bmap(overflow bucket)掛在這個bmap的后面形成鏈表,優先用預分配的overflow bucket,如果預分配的用完了,那么就malloc一個掛上去。這樣減少對象數量,減輕管理內存的負擔,利于gc。注意golang的map不會shrink,內存只會越用越多,overflow bucket中的key全刪了也不會釋放。 bmap中所有key存在一塊,所有value存在一塊,這樣做方便內存對齊。當key大于128字節時,bucket的key字段存儲的會是指針,指向key的實際內容;value也是一樣。
hash值的高8位存儲在bucket中的tophash字段。每個桶最多放8個kv對,所以tophash類型是數組[8]uint8。把高八位存儲起來,這樣不用完整比較key就能過濾掉不符合的key,加快查詢速度。實際上當hash值的高八位小于常量minTopHash時,會加上minTopHash,區間[0, minTophash)的值用于特殊標記。查找key時,計算hash值,用hash值的高八位在tophash中查找,有tophash相等的,再去比較key值是否相同。
type typeAlg struct {
// function for hashing objects of this type
// (ptr to object, seed) -> hash
hash func(unsafe.Pointer, uintptr) uintptr
// function for comparing objects of this type
// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
// tophash calculates the tophash value for hash.
func tophash(hash uintptr) uint8 {
top := uint8(hash >> (sys.PtrSize*8 - 8))
if top minTopHash {
top += minTopHash
}
return top
}
golang為每個類型定義了類型描述器_type,并實現了hashable類型的_type.alg.hash和_type.alg.equal,以支持map的范型,定義了這類key用什么hash函數、bucket的大小、怎么比較之類的,通過這個變量來實現范型。
3.map的基本操作
3.1map的創建
//makemap為make(map [k] v,hint)實現Go map創建。
//如果編譯器已確定映射或第一個存儲桶,可以在堆棧上創建,hmap或bucket可以為非nil。
//如果h!= nil,則可以直接在h中創建map。
//如果h.buckets!= nil,則指向的存儲桶可以用作第一個存儲桶。
func makemap(t *maptype, hint int, h *hmap) *hmap {
if hint 0 || hint > int(maxSliceCap(t.bucket.size)) {
hint = 0
}
// 初始化Hmap
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
// 查找將保存請求的元素數的size參數
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
// 分配初始哈希表
// if B == 0, 稍后會延遲分配buckets字段(在mapassign中)
//如果提示很大,則將內存清零可能需要一段時間。
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
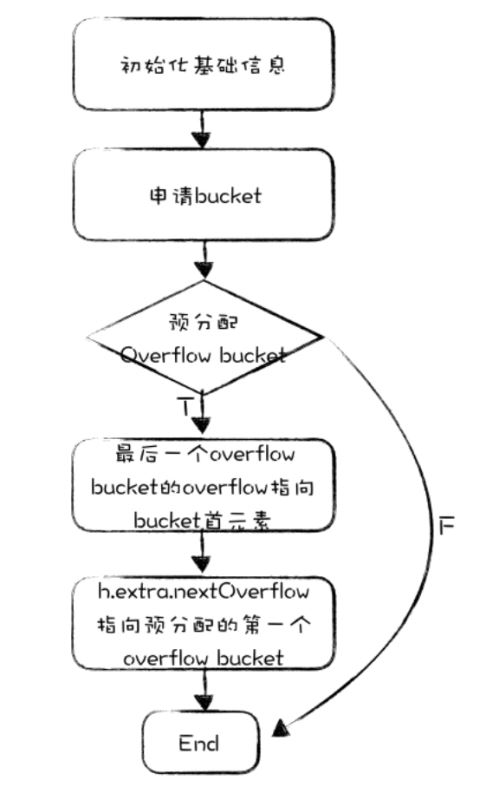
hint是一個啟發值,啟發初建map時創建多少個bucket,如果hint是0那么就先不分配bucket,lazy分配。大概流程就是初始化hmap結構體、設置一下hash seed、bucket數量、實際申請bucket、申請mapextra結構體之類的。 申請buckets的過程:
// makeBucketArray初始化地圖存儲區的后備數組。
// 1 b是要分配的最小存儲桶數。
// dirtyalloc之前應該為nil或bucket數組
//由makeBucketArray使用相同的t和b參數分配。
//如果dirtyalloc為零,則將分配一個新的支持數組,dirtyalloc將被清除并作為后備數組重用。
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {
base := bucketShift(b)
nbuckets := base
// 對于小b,溢出桶不太可能出現。
// 避免計算的開銷。
if b >= 4 {
//加上估計的溢出桶數
//插入元素的中位數
//與此值b一起使用。
nbuckets += bucketShift(b - 4)
sz := t.bucket.size * nbuckets
up := roundupsize(sz)
if up != sz {
nbuckets = up / t.bucket.size
}
}
if dirtyalloc == nil {
buckets = newarray(t.bucket, int(nbuckets))
} else {
// dirtyalloc先前是由上面的newarray(t.bucket,int(nbuckets)),但不能為空。
buckets = dirtyalloc
size := t.bucket.size * nbuckets
if t.bucket.kindkindNoPointers == 0 {
memclrHasPointers(buckets, size)
} else {
memclrNoHeapPointers(buckets, size)
}
}
if base != nbuckets {
//我們預先分配了一些溢出桶。
//為了將跟蹤這些溢出桶的開銷降至最低,我們使用的約定是,如果預分配的溢出存儲桶發生了溢出指針為零,則通過碰撞指針還有更多可用空間。
//對于最后一個溢出存儲區,我們需要一個安全的非nil指針;只是用bucket。
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.bucketsize)))
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize)))
last.setoverflow(t, (*bmap)(buckets))
}
return buckets, nextOverflow
}
默認創建2b個bucket,如果b大于等于4,那么就預先額外創建一些overflow bucket。除了最后一個overflow bucket,其余overflow bucket的overflow指針都是nil,最后一個overflow bucket的overflow指針指向bucket數組第一個元素,作為哨兵,說明到了到結尾了。
3.2 查詢操作
// mapaccess1返回指向h [key]的指針。從不返回nil,而是 如果值類型為零,它將返回對零對象的引用,該鍵不在map中。
//注意:返回的指針可能會使整個map保持活動狀態,因此請不要堅持很長時間。
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if raceenabled h != nil { //raceenabled是否啟用數據競爭檢測。
callerpc := getcallerpc()
pc := funcPC(mapaccess1)
racereadpc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled h != nil {
msanread(key, t.key.size)
}
if h == nil || h.count == 0 {
return unsafe.Pointer(zeroVal[0])
}
// 并發訪問檢查
if h.flagshashWriting != 0 {
throw("concurrent map read and map write")
}
// 計算key的hash值
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0)) // alg.hash
// hash值對m取余數得到對應的bucket
m := uintptr(1)h.B - 1
b := (*bmap)(add(h.buckets, (hashm)*uintptr(t.bucketsize)))
// 如果老的bucket還沒有遷移,則在老的bucket里面找
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
m >>= 1
}
oldb := (*bmap)(add(c, (hashm)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
// 計算tophash,取高8位
top := uint8(hash >> (sys.PtrSize*8 - 8))
for {
for i := uintptr(0); i bucketCnt; i++ {
// 檢查top值,如高8位不一樣就找下一個
if b.tophash[i] != top {
continue
}
// 取key的地址
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if alg.equal(key, k) { // alg.equal
// 取value得地址
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
}
}
// 如果當前bucket沒有找到,則找bucket鏈的下一個bucket
b = b.overflow(t)
if b == nil {
// 返回零值
return unsafe.Pointer(zeroVal[0])
}
}
}
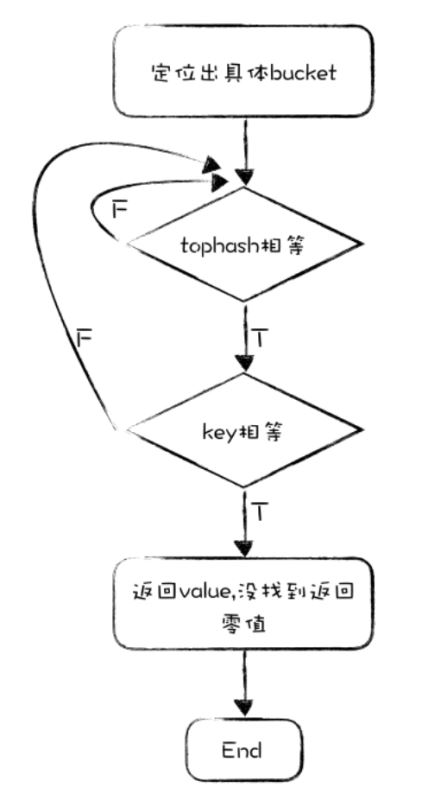
先定位出bucket,如果正在擴容,并且這個bucket還沒搬到新的hash表中,那么就從老的hash表中查找。
在bucket中進行順序查找,使用高八位進行快速過濾,高八位相等,再比較key是否相等,找到就返回value。如果當前bucket找不到,就往下找overflow bucket,都沒有就返回零值。
訪問的時候,并不進行擴容的數據搬遷。并且并發有寫操作時拋異常。
注意,t.bucketsize并不是bmap的size,而是bmap加上存儲key、value、overflow指針,所以查找bucket的時候時候用的不是bmap的szie。
3.3 更新/插入過程
// 與mapaccess類似,但是如果map中不存在密鑰,則為該密鑰分配一個插槽
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
//設置hashWriting調用alg.hash,因為alg.hash可能出現緊急情況后,在這種情況下,我們實際上并沒有進行寫操作.
h.flags |= hashWriting
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
bucket := hash bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))
top := tophash(hash)
var inserti *uint8
var insertk unsafe.Pointer
var val unsafe.Pointer
for {
for i := uintptr(0); i bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == empty inserti == nil {
inserti = b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey {
k = *((*unsafe.Pointer)(k))
}
if !alg.equal(key, k) {
continue
}
// 已經有一個 mapping for key. 更新它.
if t.needkeyupdate {
typedmemmove(t.key, k, key)
}
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
goto done
}
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
//// 如果已經達到了load factor的最大值,就繼續擴容。
//找不到鍵的映射。分配新單元格并添加條目。
//如果達到最大負載系數或溢出桶過多,并且我們還沒有處于成長的中間,就開始擴容。
if !h.growing() (overLoadFactor(h.count+1, h.B) ||
tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // //擴大表格會使所有內容無效, so try again
}
if inserti == nil {
// 當前所有存儲桶已滿,請分配一個新的存儲桶
newb := h.newoverflow(t, b)
inserti = newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
val = add(insertk, bucketCnt*uintptr(t.keysize))
}
// 在插入的位置,存儲鍵值
if t.indirectkey {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.indirectvalue {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(val) = vmem
}
typedmemmove(t.key, insertk, key)
*inserti = top
h.count++
done:
if h.flagshashWriting == 0 {
throw("concurrent map writes")
}
h.flags ^= hashWriting
if t.indirectvalue {
val = *((*unsafe.Pointer)(val))
}
return val
}
hash表如果正在擴容,并且這次要操作的bucket還沒搬到新hash表中,那么先進行搬遷(擴容細節下面細說)。
在buck中尋找key,同時記錄下第一個空位置,如果找不到,那么就在空位置中插入數據;如果找到了,那么就更新對應的value;
找不到key就看下需不需要擴容,需要擴容并且沒有正在擴容,那么就進行擴容,然后回到第一步。
找不到key,不需要擴容,但是沒有空slot,那么就分配一個overflow bucket掛在鏈表結尾,用新bucket的第一個slot放存放數據。
3.5 刪除的過程
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
...
// Set hashWriting after calling alg.hash, since alg.hash may panic,
// in which case we have not actually done a write (delete).
h.flags |= hashWriting
bucket := hash bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
top := tophash(hash)
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i bucketCnt; i++ {
if b.tophash[i] != top {
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
k2 := k
if t.indirectkey {
k2 = *((*unsafe.Pointer)(k2))
}
if !alg.equal(key, k2) {
continue
}
// 如果其中有指針,則僅清除鍵。
if t.indirectkey {
*(*unsafe.Pointer)(k) = nil
} else if t.key.kindkindNoPointers == 0 {
memclrHasPointers(k, t.key.size)
}
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
if t.indirectvalue {
*(*unsafe.Pointer)(v) = nil
} else if t.elem.kindkindNoPointers == 0 {
memclrHasPointers(v, t.elem.size)
} else {
memclrNoHeapPointers(v, t.elem.size)
}
// 若找到把對應的tophash里面的打上空的標記
b.tophash[i] = empty
h.count--
break search
}
}
if h.flagshashWriting == 0 {
throw("concurrent map writes")
}
h.flags ^= hashWriting
}
如果正在擴容,并且操作的bucket還沒搬遷完,那么搬遷bucket。
找出對應的key,如果key、value是包含指針的那么會清理指針指向的內存,否則不會回收內存。
3.6 map的擴容
通過上面的過程我們知道了,插入、刪除過程都會觸發擴容,判斷擴容的函數如下:
// overLoadFactor 判斷放置在1 B個存儲桶中的計數項目是否超過loadFactor。
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
//return 元素個數>8 count>bucket數量*6.5,其中loadFactorNum是常量13,loadFactorDen是常量2,所以是6.5,bucket數量不算overflow bucket.
}
// tooManyOverflowBuckets 判斷noverflow存儲桶對于1 B存儲桶的map是否過多。
// 請注意,大多數這些溢出桶必須稀疏使用。如果使用密集,則我們已經觸發了常規map擴容。
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
// 如果閾值太低,我們會做多余的工作。如果閾值太高,則增大和縮小的映射可能會保留大量未使用的內存。
//“太多”意味著(大約)溢出桶與常規桶一樣多。有關更多詳細信息,請參見incrnoverflow。
if B > 15 {
B = 15
}
// 譯器在這里看不到B 16;掩碼B生成較短的移位碼。
return noverflow >= uint16(1)(B15)
}
{
....
// 如果我們達到最大負載率或溢流桶過多,并且我們還沒有處于成長的中間,就開始成長。
if !h.growing() (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // 擴大表格會使所有內容失效,so try again
}
//if (不是正在擴容 (元素個數/bucket數超過某個值 || 太多overflow bucket)) {
進行擴容
//}
....
}
每次map進行更新或者新增的時候,會先通過以上函數判斷一下load factor。來決定是否擴容。如果需要擴容,那么第一步需要做的,就是對hash表進行擴容:
//僅對hash表進行擴容,這里不進行搬遷
func hashGrow(t *maptype, h *hmap) {
// 如果達到負載系數,則增大尺寸。否則,溢出bucket過多,因此,保持相同數量的存儲桶并橫向“增長”。
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags ^ (iterator | oldIterator)
if h.flagsiterator != 0 {
flags |= oldIterator
}
// 提交增長(atomic wrt gc)
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
if h.extra != nil h.extra.overflow != nil {
// 將當前的溢出bucket提升到老一代。
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
//哈希表數據的實際復制是增量完成的,通過growWork()和evacuate()。
}
如果之前為2^n ,那么下一次擴容是2^(n+1),每次擴容都是之前的兩倍。擴容后需要重新計算每一項在hash中的位置,新表為老的兩倍,此時前文的oldbacket用上了,用來存同時存在的兩個新舊map,等數據遷移完畢就可以釋放oldbacket了。擴容的函數hashGrow其實僅僅是進行一些空間分配,字段的初始化,實際的搬遷操作是在growWork函數中:
func growWork(t *maptype, h *hmap, bucket uintptr) {
//確保我們遷移了了對應的oldbucket,到我們將要使用的存儲桶。
evacuate(t, h, bucketh.oldbucketmask())
// 疏散一個舊桶以在生長上取得進展
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}
evacuate是進行具體搬遷某個bucket的函數,可以看出growWork會搬遷兩個bucket,一個是入參bucket;另一個是h.nevacuate。這個nevacuate是一個順序累加的值。可以想想如果每次僅僅搬遷進行寫操作(賦值/刪除)的bucket,那么有可能某些bucket就是一直沒有機會訪問到,那么擴容就一直沒法完成,總是在擴容中的狀態,因此會額外進行一次順序遷移,理論上,有N個old bucket,最多N次寫操作,那么必定會搬遷完。在advanceEvacuationMark中進行nevacuate的累加,遇到已經遷移的bucket會繼續累加,一次最多加1024。 優點:均攤擴容時間,一定程度上縮短了擴容時間(和gc的引用計數法類似,都是均攤)overLoadFactor函數中有一個常量6.5(loadFactorNum/loadFactorDen)來進行影響擴容時機。這個值的來源是測試取中的結果。
4.map的并發安全性
map的并發操作不是安全的。并發起兩個goroutine,分別對map進行數據的增加:
func main() {
test := map[int]int {1:1}
go func() {
i := 0
for i 10000 {
test[1]=1
i++
}
}()
go func() {
i := 0
for i 10000 {
test[1]=1
i++
}
}()
time.Sleep(2*time.Second)
fmt.Println(test)
}
//fatal error: concurrent map read and map write
并發讀寫map結構的數據引起了錯誤。
解決方案1:加鎖
func main() {
test := map[int]int {1:1}
var s sync.RWMutex
go func() {
i := 0
for i 10000 {
s.Lock()
test[1]=1
s.Unlock()
i++
}
}()
go func() {
i := 0
for i 10000 {
s.Lock()
test[1]=1
s.Unlock()
i++
}
}()
time.Sleep(2*time.Second)
fmt.Println(test)
}
特點:實現簡單粗暴,好理解。但是鎖的粒度為整個map,存在優化空間。適用場景:all。
解決方案2:sync.Map
func main() {
test := sync.Map{}
test.Store(1, 1)
go func() {
i := 0
for i 10000 {
test.Store(1, 1)
i++
}
}()
go func() {
i := 0
for i 10000 {
test.Store(1, 1)
i++
}
}()
time.Sleep(time.Second)
fmt.Println(test.Load(1))
}
sync.Map的原理:sync.Map里頭有兩個map一個是專門用于讀的read map,另一個是才是提供讀寫的dirty map;優先讀read map,若不存在則加鎖穿透讀dirty map,同時記錄一個未從read map讀到的計數,當計數到達一定值,就將read map用dirty map進行覆蓋。特點:官方出品,通過空間換時間的方式,讀寫分離;不適用于大量寫的場景,會導致read map讀不到數據而進一步加鎖讀取,同時dirty map也會一直晉升為read map,整體性能較差。適用場景:大量讀,少量寫。
解決方案3:分段鎖
這也是數據庫常用的方法,分段鎖每一個讀寫鎖保護一段區間。sync.Map其實也是相當于表級鎖,只不過多讀寫分了兩個map,本質還是一樣的。
優化方向:將鎖的粒度盡可能降低來提高運行速度。思路:對一個大map進行hash,其內部是n個小map,根據key來來hash確定在具體的那個小map中,這樣加鎖的粒度就變成1/n了。例如
5.map的GC內存回收
golang里的map是只增不減的一種數組結構,他只會在刪除的時候進行打標記說明該內存空間已經empty了,不會回收。
var intMap map[int]int
func main() {
printMemStats("初始化")
// 添加1w個map值
intMap = make(map[int]int, 10000)
for i := 0; i 10000; i++ {
intMap[i] = i
}
// 手動進行gc操作
runtime.GC()
// 再次查看數據
printMemStats("增加map數據后")
log.Println("刪除前數組長度:", len(intMap))
for i := 0; i 10000; i++ {
delete(intMap, i)
}
log.Println("刪除后數組長度:", len(intMap))
// 再次進行手動GC回收
runtime.GC()
printMemStats("刪除map數據后")
// 設置為nil進行回收
intMap = nil
runtime.GC()
printMemStats("設置為nil后")
}
func printMemStats(mag string) {
var m runtime.MemStats
runtime.ReadMemStats(m)
log.Printf("%v:分配的內存 = %vKB, GC的次數 = %v\n", mag, m.Alloc/1024, m.NumGC)
}
//初始化:分配的內存 = 65KB, GC的次數 = 0
//增加map數據后:分配的內存 = 381KB, GC的次數 = 1
//刪除前數組長度: 10000
//刪除后數組長度: 0
//刪除map數據后:分配的內存 = 381KB, GC的次數 = 2
//設置為nil后:分配的內存 = 68KB, GC的次數 = 3
可以看到delete是不會真正的把map釋放的,所以要回收map還是需要設為nil
總結
以上所述是小編給大家介紹的go中的map數據結構字典,希望對大家有所幫助,如果大家有任何疑問請給我留言,小編會及時回復大家的。在此也非常感謝大家對腳本之家網站的支持!如果你覺得本文對你有幫助,歡迎轉載,煩請注明出處,謝謝!
您可能感興趣的文章:- Golang中數據結構Queue的實現方法詳解
- 使用go實現常見的數據結構
- Go語言模型:string的底層數據結構與高效操作詳解
- 淺談用Go構建不可變的數據結構的方法
- golang數據結構之golang稀疏數組sparsearray詳解
