基本上只要是做后臺開發(fā),都會接觸到分頁這個需求或者功能吧。基本上大家都是會用MySQL的LIMIT來處理,而且我現(xiàn)在負責(zé)的項目也是這樣寫的。但是一旦數(shù)據(jù)量起來了,其實LIMIT的效率會極其的低,這一篇文章就來講一下LIMIT子句優(yōu)化的。
很多業(yè)務(wù)場景都需要用到分頁這個功能,基本上都是用LIMIT來實現(xiàn)。
建表并且插入200萬條數(shù)據(jù):
# 新建一張t5表
CREATE TABLE `t5` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL,
`text` varchar(100) NOT NULL,
PRIMARY KEY (`id`),
KEY `ix_name` (`name`),
KEY `ix_test` (`text`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# 創(chuàng)建存儲過程插入200萬數(shù)據(jù)
CREATE PROCEDURE t5_insert_200w()
BEGIN
DECLARE i INT;
SET i=1000000;
WHILE i=3000000 DO
INSERT INTO t5(`name`,text) VALUES('god-jiang666',concat('text', i));
SET i=i+1;
END WHILE;
END;
# 調(diào)用存儲過程插入200萬數(shù)據(jù)
call t5_insert_200w();
在翻頁比較少的情況下,LIMIT是不會出現(xiàn)任何性能上的問題的。
但是如果用戶需要查到最后面的頁數(shù)呢?
通常情況下,我們要保證所有的頁面可以正常跳轉(zhuǎn),因為不會使用order by xxx desc這樣的倒序SQL來查詢后面的頁數(shù),而是采用正序順序來做分頁查詢:
select * from t5 order by text limit 100000, 10;

采用這種SQL查詢分頁的話,從200萬數(shù)據(jù)中取出這10行數(shù)據(jù)的代價是非常大的,需要先排序查出前1000010條記錄,然后拋棄前面1000000條。我的macbook pro跑出來花了5.578秒。
接下來我們來看一下,上面這條SQL語句的執(zhí)行計劃:
explain select * from t5 order by text limit 1000000, 10;
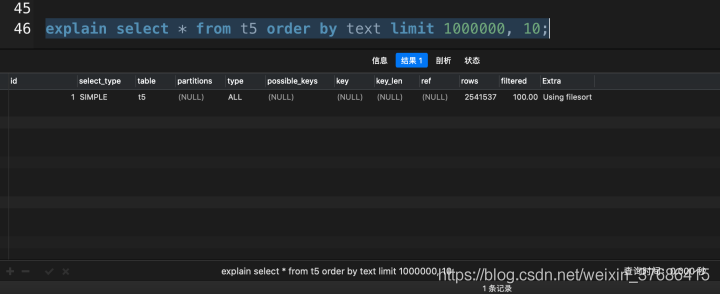
從執(zhí)行計劃可以看出,在大分頁的情況下,MySQL沒有走索引掃描,即使text字段我已經(jīng)加上了索引。
這是為什么呢?
回到MySQL索引(二)如何設(shè)計索引中有提及到,MySQL數(shù)據(jù)庫的查詢優(yōu)化器是采用了基于代價的,而查詢代價的估算是基于CPU代價和IO代價。
如果MySQL在查詢代價估算中,認為全表掃描方式比走索引掃描的方式效率更高的話,就會放棄索引,直接全表掃描。
這就是為什么在大分頁的SQL查詢中,明明給該字段加了索引,但是MySQL卻走了全表掃描的原因。
然后我們繼續(xù)用上面的查詢SQL來驗證我的猜想:
explain select * from t5 order by text limit 7774, 10;

explain select * from t5 order by text limit 7775, 10;
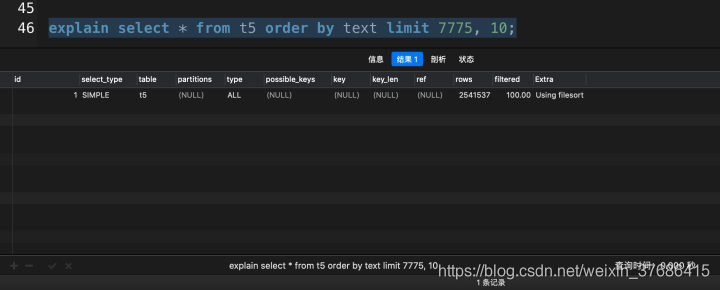
以上的實驗均在我的mbp上運行的,在7774這個臨界點上,MySQL分別采用了索引掃描和全表掃描的查詢優(yōu)化方式。
所以可以認為MySQL會根據(jù)它自己的代價查詢優(yōu)化器來判斷是否使用索引。
由于MySQL的查詢優(yōu)化器的算法核心是我們無法人工干預(yù)的,所以我們的優(yōu)化思路就要著手于如何讓分頁維持在最佳的的分頁臨界點。
如果一條SQL語句,通過索引可以直接獲取查詢的結(jié)果,不再需要回表查詢,就稱這個索引為覆蓋索引。
在MySQL數(shù)據(jù)庫中使用explain關(guān)鍵字查看執(zhí)行計劃,如果extra這一列顯示Using index,就表示這條SQL語句使用了覆蓋索引。
讓我們來對比一下使用了覆蓋索引,性能會提升多少吧。
# 沒有使用覆蓋索引 select * from t5 order by text limit 1000000, 10;
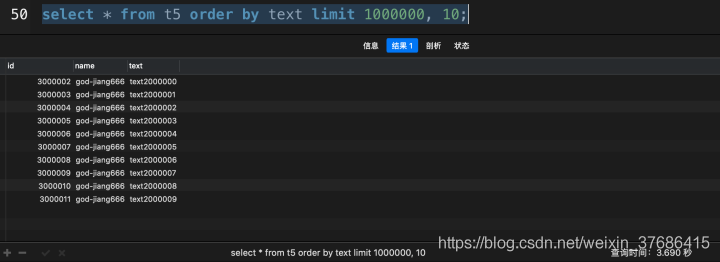
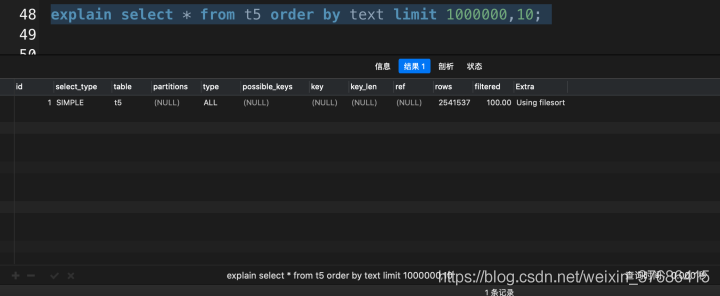
這次查詢花了3.690秒,讓我們看一下使用了覆蓋索引優(yōu)化會提升多少性能吧。
# 使用了覆蓋索引 select id, `text` from t5 order by text limit 1000000, 10;
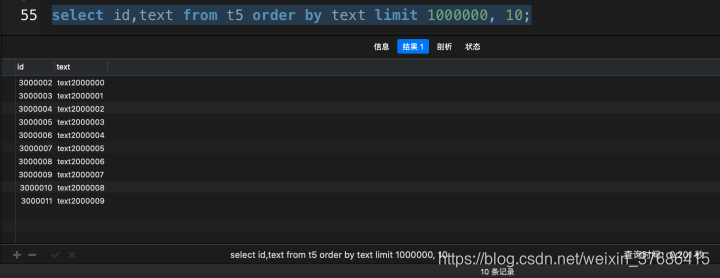
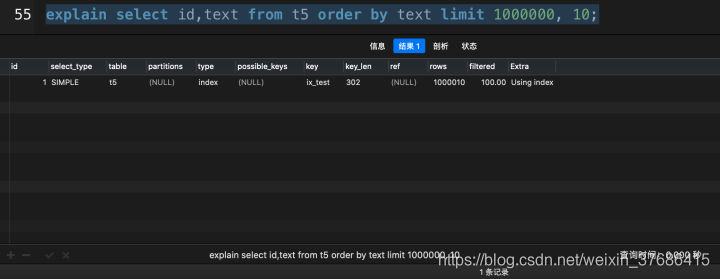
從上面的對比中,超大分頁查詢中,使用了覆蓋索引之后,花了0.201秒,而沒有使用覆蓋索引花了3.690秒,提高了18倍多,這在實際開發(fā)中,就是一個大的性能優(yōu)化了。(該數(shù)據(jù)在我的mbp上運行得出)
因為實際開發(fā)中,用SELECT查詢一兩列操作是非常少的,因此上述的覆蓋索引的適用范圍就比較有限。
所以我們可以通過把分頁的SQL語句改寫成子查詢的方法獲得性能上的提升。
select * from t5 where id>=(select id from t5 order by text limit 1000000, 1) limit 10;
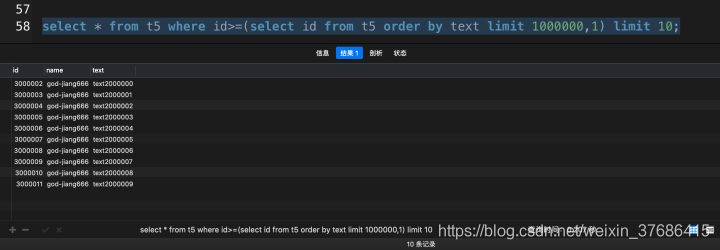
其實使用這種方法,提升的效率和上面使用了覆蓋索引基本一致。
但是這種優(yōu)化方法也有局限性:
和上述的子查詢做法類似,我們可以使用JOIN,先在索引列上完成分頁操作,然后再回表獲取所需要的列。
select a.* from t5 a inner join (select id from t5 order by text limit 1000000, 10) b on a.id=b.id;
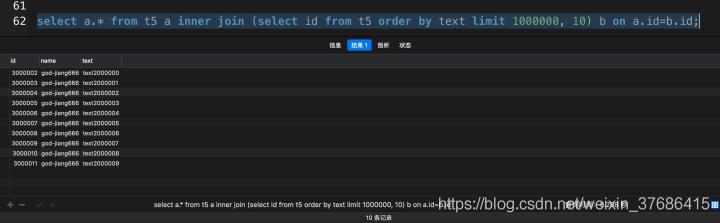
從實驗中可以得出,在采用JOIN改寫后,上面的兩個局限性都已經(jīng)解除了,而且SQL的執(zhí)行效率也沒有損失。
和上面使用的方法都不同,記錄上次結(jié)束位置優(yōu)化思路是使用某種變量記錄上一次數(shù)據(jù)的位置,下次分頁時直接從這個變量的位置開始掃描,從而避免MySQL掃描大量的數(shù)據(jù)再拋棄的操作。
select * from t5 where id>=1000000 limit 10;
根據(jù)以上實驗,不難得出,由于使用了主鍵索引做分頁操作,SQL的性能是最快的。
參考資料
到此這篇關(guān)于MySQL優(yōu)化教程之超大分頁查詢的文章就介紹到這了,更多相關(guān)MySQL超大分頁查詢內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家!
標簽:天津 惠州 沈陽 公主嶺 牡丹江 合肥 阿里 呼和浩特
巨人網(wǎng)絡(luò)通訊聲明:本文標題《MySQL優(yōu)化教程之超大分頁查詢》,本文關(guān)鍵詞 MySQL,優(yōu)化,教程,之,超大,;如發(fā)現(xiàn)本文內(nèi)容存在版權(quán)問題,煩請?zhí)峁┫嚓P(guān)信息告之我們,我們將及時溝通與處理。本站內(nèi)容系統(tǒng)采集于網(wǎng)絡(luò),涉及言論、版權(quán)與本站無關(guān)。



