Google,無疑是互聯網時代最閃亮的明星。截止到今天為止,Google美國主站在Alexa排名已經連續3年第一,Alexa Top100中,各國的Google分站竟然霸占了超過20多個名額,不得不令人感嘆Google的強大。不論何時,不論何地,也不論你搜索多么冷門的詞匯,只要你的電腦連接互聯網,只要你輕輕點擊“google搜索”,那么這一切相關內容google都會在1秒鐘之內全部搞定,這甚至比你查詢“我的文檔”都要快捷。這也就是為什么Google創業12年,市值超過2000億美元的原因。
有人可能認為Google擁有幾臺“藍色基因”那樣的超級計算機來處理各種數據和搜索,事實是怎樣的呢?下面我們就將詳細解析神奇Google的神奇架構。
硬件:
截止到2010年,Google大約有100萬臺服務器,有超過500個計算機集群,處理不同地域的不同任務。可惜服務器的詳細配置和最新集群的具體情況,在多個文獻庫里面都查詢不到,我個人理解,這可能屬于商業機密。大概也是因為機密的緣故,強大的Google計算機集群并沒有遞交Top500計算機的申請,多年來我們在Top500中都看不到Google的影子。(進入Top500需要提交并且公開自己計算機系統的詳細配置)不過根據文獻資料,可以肯定的是,這45萬臺服務器都不是什么昂貴的服務器,而是非常普通的PC級別服務器,其中的服務器硬盤在兩年前還普遍是IDE接口、并且采用PC級主板而非昂貴的服務器專用主板。Google的集群也全部是自己搭建的,沒有采用Myricom 的 Myrinet或者Giganet 的 cLAN等先進昂貴的集群連接技術,Google各個數據中心和服務器間不同的耦合程度都隨需而定自行連接。
那么google的存儲呢?Google存儲著海量的資訊,近千億個網頁、數百億張圖片。早在2004年,Google的存儲容量就已經達到了5PB。可能很多讀者一開始都認為Google采用了諸如EMC Symmetrix系列磁盤陣列來保存大量的資訊,但是Google的實際做法又一次讓我們大跌眼鏡——Google沒有使用任何磁盤陣列,哪怕是低端的磁盤陣列也沒用。Google的方法是將集群中的每一臺PC級服務器,配備兩個普通IDE硬盤來存儲。不過Google倒也不是都是什么設備都落后,至少這些硬盤的轉速都很高,而且每臺服務器的內存也還算比較大。最大的電腦DIY消費者是誰?恐怕Google又登上了這個DIY寶座。Google的絕大部分服務器甚至也不是采購什么大品牌,而是購買各種廉價零件而后自行裝配的。有趣的是,Google非常不滿意現存的各種PC電源的功耗,甚至還自行設計了Google專用服務器電源。
很快,我們就有了疑問。這樣的一個以PC級別服務器搭建起來的系統,怎么能承受巨大的工作負載呢?怎么能保證高可用性呢?的確,這些低端的服務器經常出現故障——硬盤壞道、系統宕機這類的事故其實每天都在45萬臺服務器中發生。而Google的方法是設立鏡像站。以Google主站為例,2003年就在美國硅谷和弗吉尼亞設立了多個鏡像站。這些鏡像站其實不是傳統的鏡像站。真正的鏡像站是雙機熱備,當一臺服務器宕機時,另一臺服務器接管相關任務。而Google的鏡像站其實真正的職責是DNS負載均衡,所以有的Google鏡像站本身還有自己的鏡像站。這里舉例說明Google鏡像站的作用:一個訪問,DNS正常解析到A處,但當A處負載過大時,DNS服務就將域名解析到B處,這樣既達到了冗余,也縮減了投資。由于不是雙機熱備,某一時間,鏡像站的內容可能略有不同,不過對于精確度要求不那么高的普通檢索而言,并不是問題。
平臺:GFS/MapReduce/ BigTable/Linux
GFS/MapReduce/ BigTable/這三個平臺,是Google最引以為傲的平臺,全部架構在Linux之上。
首先我們來看一看GFS(Google File System)Google文件系統。我們知道,一般的數據中心檢索時候需要用到數據庫系統。但是Google的情況很特殊——Google擁有全球上百億個Web文檔,如果用常規數據庫系統檢索,那么檢索速度就可想而知了。因此,當Crawlers采集到許多新的Web后,Google將很多的Web都匯集到一個文件里進行存儲管理,而且Google將Web文件壓縮成Chunk塊,進一步減少占用空間(64MB一個chunk)。最后,Google只檢索壓縮后的部分。而GFS(Google File System)正是在這樣的檢索技術上構建的文件系統,GFS包括了GFS Master服務器和Chunk服務器。如下圖所示,系統的流程從GFS客戶端開始:GFS客戶端以chunk偏移量制作目錄索引并且發送請求——GFS Master收到請求通過chunk映射表映射反饋客戶端——客戶端有了chunk handle和chunk 位置,并將文件名和chunk的目錄索引緩存,向chunk服務器發送請求——chunk服務器回復請求傳輸chunk數據。
如果讀者您讀著有點迷糊,這很正常,因為只有少數搜索引擎企業才采用這樣的技術。簡單來說是這樣:Google運用GFS大大簡化了檢索的難度。
除了GFS,MapReduce對Google也是功不可沒。Google擁有不少于45萬臺服務器,看起來每臺服務器的職能都非常明確,但是其中卻有重要的協同問題有待解決:如何并發計算,如何分布數據,如何處理失敗,如何負載均衡?我們可以預見,無數的代碼將被用在協同問題上,而且很可能效率低下。這時候,MapReduce就派上用場了。MapReduce是Google開發的C++編程工具,用于大規模數據集的并行運算。MapReduce主要功能是提供了一個簡單強大的接口,可以將計算自動的并發和分布執行。這樣一來,就可以通過普通PC的集群,實現高性能。MapReduce主要從兩方面提升了系統:首先是失效的計算機問題。如果某一臺計算機失效了,或者是I/O出現了問題——這在Google以廉價服務器組建的集群中極為常見,MapReduce的解決方法是用多個計算機同時計算一個任務,一旦一臺計算機有了結果,其它計算機就停止該任務,而進入下一任務。另外,在MapReduce之間傳輸的數據都是經過壓縮的,節省了很多帶寬資源。至于BigTable,這是一個用來處理大數據量的系統,適合處理半結構化的數據。
Google心經:
Google總是嘗試用最少的錢,做最多的事情。不要小看那些便宜、不牢靠的PC級服務器,一臺服務器也許確實不牢靠,但是45萬臺的有機集成卻成為了全球最完善、最穩定的系統之一。在采購服務器方面,Google也從未一次性大量購買,都是有了需求再選購。另一個能夠體現Google精打細算的方面是Google盡量壓縮所有能夠壓縮的文件。
包括軟件和硬件,Google的設計構想都很前衛,Google嘗試過許多還在實驗室里的萌芽技術,如上文所說,很多都取得了巨大成功。Google早先的目標是0.5秒鐘做出搜索結果,但實際上目前的平均時間已經縮減到了0.25秒。而且,Google從來沒有停止研究的腳步,現在還在測試OpenSoalris,觀察OpenSoalris是否能夠替代Linux。
Google的行為非常踏實。不參加Top500評選,文獻里也鮮有相關資料。可見Google不吹噓、也沒有過度宣傳,只是勤勤懇懇的更新程序、優化集群。今天,google收錄了絕大多數人類語言的網頁,并且在多數國家都建立了Google分站,收錄的網頁也是與日俱增,全球影響力更是不言而喻。
向Google的架構學習,向Google的成就致敬。
Google是伸縮性的王者。Google一直的目標就是構建高性能高伸縮性的基礎組織來支持它們的產品。
平臺
Linux
大量語言:Python,Java,C++
狀態
在2006年大約有450,000臺廉價服務器,這個數量到2010年增加到了1,000,000臺。
在2005年Google索引了80億Web頁面,現在沒有人知道具體數目,近千億并不斷增長中。
目前在Google有超過500個GFS集群。一個集群可以有1000或者甚至5000臺機器。成千上萬的機器從運行著5000000000000000字節存儲的GFS集群獲取數據,集群總的讀寫吞吐量可以達到每秒40兆字節
目前在Google有6000個MapReduce程序,而且每個月都寫成百個新程序
BigTable伸縮存儲幾十億的URL,幾百千千兆的衛星圖片和幾億用戶的參數選擇
堆棧
Google形象化它們的基礎組織為三層架構:
1,產品:搜索,廣告,email,地圖,視頻,聊天,博客
2,分布式系統基礎組織:GFS,MapReduce和BigTable
3,計算平臺:一群不同的數據中心里的機器
4,確保公司里的人們部署起來開銷很小
5,花費更多的錢在避免丟失日志數據的硬件上,其他類型的數據則花費較少
可信賴的存儲機制GFS(Google File System)
1,可信賴的伸縮性存儲是任何程序的核心需求。GFS就是Google的核心存儲平臺
2,Google File System – 大型分布式結構化日志文件系統,Google在里面扔了大量的數據
3,為什么構建GFS而不是利用已有的東西?因為可以自己控制一切并且這個平臺與別的不一樣,Google需要:
-跨數據中心的高可靠性
-成千上萬的網絡節點的伸縮性
-大讀寫帶寬的需求
-支持大塊的數據,可能為上千兆字節
-高效的跨節點操作分發來減少瓶頸
4,系統有Master和Chunk服務器
-Master服務器在不同的數據文件里保持元數據。數據以64MB為單位存儲在文件系統中。客戶端與Master服務器交流來在文件上做元數據操作并且找到包含用戶需要數據的那些Chunk服務器
-Chunk服務器在硬盤上存儲實際數據。每個Chunk服務器跨越3個不同的Chunk服務器備份以創建冗余來避免服務器崩潰。一旦被Master服務器指明,客戶端程序就會直接從Chunk服務器讀取文件
6,一個上線的新程序可以使用已有的GFS集群或者可以制作自己的GFS集群
7,關鍵點在于有足夠的基礎組織來讓人們對自己的程序有所選擇,GFS可以調整來適應個別程序的需求
使用MapReduce來處理數據
1,現在你已經有了一個很好的存儲系統,你該怎樣處理如此多的數據呢?比如你有許多TB的數據存儲在1000臺機器上。數據庫不能伸縮或者伸縮到這種級別花費極大,這就是MapReduce出現的原因
2,MapReduce是一個處理和生成大量數據集的編程模型和相關實現。用戶指定一個map方法來處理一個鍵/值對來生成一個中間的鍵/值對,還有一個reduce方法來合并所有關聯到同樣的中間鍵的中間值。許多真實世界的任務都可以使用這種模型來表現。以這種風格來寫的程序會自動并行的在一個大量機器的集群里運行。運行時系統照顧輸入數據劃分、程序在機器集之間執行的調度、機器失敗處理和必需的內部機器交流等細節。這允許程序員沒有多少并行和分布式系統的經驗就可以很容易使用一個大型分布式系統資源
3,為什么使用MapReduce?
-跨越大量機器分割任務的好方式
-處理機器失敗
-可以與不同類型的程序工作,例如搜索和廣告。幾乎任何程序都有map和reduce類型的操作。你可以預先計算有用的數據、查詢字數統計、對TB的數據排序等等
4,MapReduce系統有三種不同類型的服務器
-Master服務器分配用戶任務到Map和Reduce服務器。它也跟蹤任務的狀態
-Map服務器接收用戶輸入并在其基礎上處理map操作。結果寫入中間文件
-Reduce服務器接收Map服務器產生的中間文件并在其基礎上處理reduce操作
5,例如,你想在所有Web頁面里的字數。你將存儲在GFS里的所有頁面拋入MapReduce。這將在成千上萬臺機器上同時進行并且所有的調整、工作調度、失敗處理和數據傳輸將自動完成
-步驟類似于:GFS -> Map -> Shuffle -> Reduction -> Store Results back into GFS
-在MapReduce里一個map操作將一些數據映射到另一個中,產生一個鍵值對,在我們的例子里就是字和字數
-Shuffling操作聚集鍵類型
-Reduction操作計算所有鍵值對的綜合并產生最終的結果
6,Google索引操作管道有大約20個不同的map和reduction。
7,程序可以非常小,如20到50行代碼
8,一個問題是掉隊者。掉隊者是一個比其他程序慢的計算,它阻塞了其他程序。掉隊者可能因為緩慢的IO或者臨時的CPU不能使用而發生。解決方案是運行多個同樣的計算并且當一個完成后殺死所有其他的
9,數據在Map和Reduce服務器之間傳輸時被壓縮了。這可以節省帶寬和I/O。
在BigTable里存儲結構化數據
1,BigTable是一個大伸縮性、錯誤容忍、自管理的系統,它包含千千兆的內存和1000000000000000的存儲。它可以每秒鐘處理百萬的讀寫
2,BigTable是一個構建于GFS之上的分布式哈希機制。它不是關系型數據庫。它不支持join或者SQL類型查詢
3,它提供查詢機制來通過鍵訪問結構化數據。GFS存儲存儲不透明的數據而許多程序需求有結構化數據
4,商業數據庫不能達到這種級別的伸縮性并且不能在成千上萬臺機器上工作
5,通過控制它們自己的低級存儲系統Google得到更多的控制權來改進它們的系統。例如,如果它們想讓跨數據中心的操作更簡單這個特性,它們可以內建它
6,系統運行時機器可以自由的增刪而整個系統保持工作
7,每個數據條目存儲在一個格子里,它可以通過一個行key和列key或者時間戳來訪問
8,每一行存儲在一個或多個tablet中。一個tablet是一個64KB塊的數據序列并且格式為SSTable
9,BigTable有三種類型的服務器:
-Master服務器分配tablet服務器,它跟蹤tablet在哪里并且如果需要則重新分配任務
-Tablet服務器為tablet處理讀寫請求。當tablet超過大小限制(通常是100MB-200MB)時它們拆開tablet。當一個Tablet服務器失敗時,則100個Tablet服務器各自挑選一個新的tablet然后系統恢復。
-Lock服務器形成一個分布式鎖服務。像打開一個tablet來寫、Master調整和訪問控制檢查等都需要互斥
10,一個locality組可以用來在物理上將相關的數據存儲在一起來得到更好的locality選擇
11,tablet盡可能的緩存在RAM里
硬件
1,當你有很多機器時你怎樣組織它們來使得使用和花費有效?
2,使用非常廉價的硬件
3,A 1,000-fold computer power increase can be had for a 33 times lower cost if you you use a failure-prone infrastructure rather than an infrastructure built on highly reliable components. You must build reliability on top of unreliability for this strategy to work.
4,Linux,in-house rack design,PC主板,低端存儲
5,Price per wattage on performance basis isn’t getting better. Have huge power and cooling issues
6,使用一些collocation和Google自己的數據中心
其他
1,迅速更改而不是等待QA
2,庫是構建程序的卓越方式
3,一些程序作為服務提供
4,一個基礎組織處理程序的版本,這樣它們可以發布而不用害怕會破壞什么東西
Google將來的方向
1,支持地理位置分布的集群
2,為所有數據創建一個單獨的全局名字空間。當前的數據由集群分離
3,更多和更好的自動化數據遷移和計算
4,解決當使用網絡劃分來做廣闊區域的備份時的一致性問題(例如保持服務即使一個集群離線維護或由于一些損耗問題)
學到的東西
1,基礎組織是有競爭性的優勢。特別是對Google而言。Google可以很快很廉價的推出新服務,并且伸縮性其他人很難達到。許多公司采取完全不同的方式。許多公司認為基礎組織開銷太大。Google認為自己是一個系統工程公司,這是一個新的看待軟件構建的方式
2,跨越多個數據中心仍然是一個未解決的問題。大部分網站都是一個或者最多兩個數據中心。我們不得不承認怎樣在一些數據中心之間完整的分布網站是很需要技巧的
3,如果你自己沒有時間從零開始重新構建所有這些基礎組織你可以看看Hadoop。Hadoop是這里很多同樣的主意的一個開源實現
4,平臺的一個優點是初級開發人員可以在平臺的基礎上快速并且放心的創建健全的程序。如果每個項目都需要發明同樣的分布式基礎組織的輪子,那么你將陷入困境因為知道怎樣完成這項工作的人相對較少
5,協同工作不一直是擲骰子。通過讓系統中的所有部分一起工作則一個部分的改進將幫助所有的部分。改進文件系統則每個人從中受益而且是透明的。如果每個項目使用不同的文件系統則在整個堆棧中享受不到持續增加的改進
6,構建自管理系統讓你沒必要讓系統關機。這允許你更容易在服務器之間平衡資源、動態添加更大的容量、讓機器離線和優雅的處理升級
7,創建可進化的基礎組織,并行的執行消耗時間的操作并采取較好的方案
8,不要忽略學院。學院有許多沒有轉變為產品的好主意。Most of what Google has done has prior art, just not prior large scale deployment.
9,考慮壓縮。當你有許多CPU而IO有限時壓縮是一個好的選擇。
Google主要以GFS、MapReduce、BigTable這三大平臺來支撐其龐大的業務系統,我稱他們為Google三劍客,網上也有說是Google的三架馬車。
一、GFS(Google File System)
這是Google獨特的一個面向大規模數據密集型應用的、可伸縮的分布式文件系統,由于這個文件系統是通過軟件調度來實現的,所以Google可以把GFS部署在很多廉價的PC機上,來達到用昂貴服務器一樣的效果。
下面是一張Google GFS的架構圖:
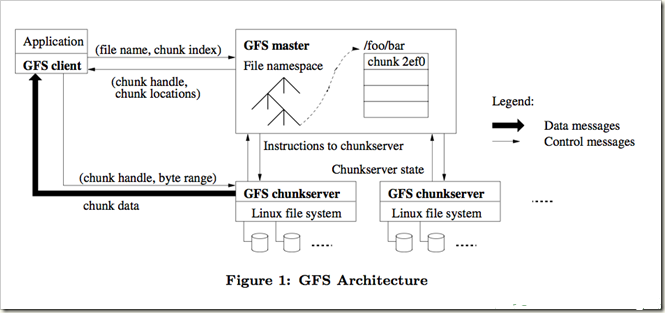
從上圖我們可看到Google的GFS主要由一個master和很多chunkserver組成,master主要是負責維護系統中的名字空間、訪問控制信息、從文件到塊的映射以及塊的當前位置等元素據,并通過心跳信號與chunkserver通信,搜集并保存chunkserver的狀態信息。chunkserver主要是用來存儲數據塊,google把每個數據塊的大小設計成64M,至于為什么這么大后面會提到,每個chunk是由master分配的chunk-handle來標識的,為了提高系統的可靠性,每個chunk會被復制3個副本放到不同的chunkserver中。
當然這樣的單master設計也會帶來單點故障問題和性能瓶頸問題,Google是通過減少client與master的交互來解決的,client均是直接與chunkserver通信,master僅僅提供查詢數據塊所在的chunkserver以及詳細位置。下面是在GFS上查詢的一般流程:
1、client使用固定的塊大小將應用程序指定的文件名和字節偏移轉換成文件的一個塊索引(chunk index)。
2、給master發送一個包含文件名和塊索引的請求。
3、master回應對應的chunk handle和副本的位置(多個副本)。
4、client以文件名和塊索引為鍵緩存這些信息。(handle和副本的位置)。
5、Client 向其中一個副本發送一個請求,很可能是最近的一個副本。請求指定了chunk handle(chunkserver以chunk handle標識chunk)和塊內的一個字節區間。
6、除非緩存的信息不再有效(cache for a limited time)或文件被重新打開,否則以后對同一個塊的讀操作不再需要client和master間的交互。
不過我還是有疑問,google可以通過減少client與master通信來解決性能瓶頸問題,但單點問題呢,一臺master掛掉豈不是完蛋了,總感覺不太放心,可能是我了解不夠透徹,不知道哪位朋友能解釋一下,謝謝:)
二、MapReduce,Google的分布式并行計算系統
如果上面的GFS解決了Google的海量數據的存儲,那這個MapReduce則是解決了如何從這些海量數據中快速計算并獲取指定數據的問題。我們知道,Google的每一次搜索都在零點零幾秒,能在這么短時間里環游世界一周,這里MapReduce有很大的功勞。
Map即映射,Reduce即規約,由master服務器把map和reduce任務分發到各自worker服務器中運行計算,最后把結果規約合并后返回給用戶。這個過程可以由下圖來說明。
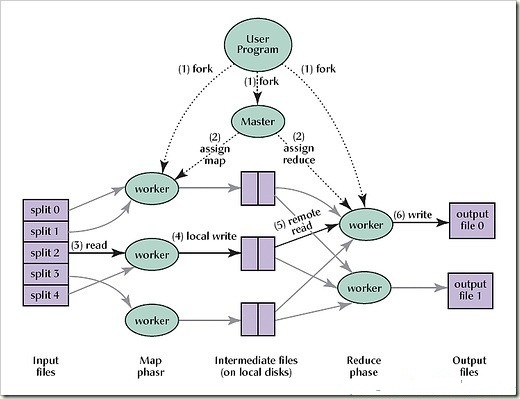
按照自己的理解,簡單對上圖加點說明:
1、首先把用戶請求的數據文件切割成多份,每一份(即每一個split)被拷貝在集群中不同機器上,然后由集群啟動程序中的多份拷貝。
2、master把map和reduce任務交給相對空閑的worker處理,并阻塞等待處理結果。
3、處理map任務的worker接到任務后,把以key/value形式的輸入數據傳遞給map函數進行處理,并將處理結果也以key/value的形式輸出,并保存在內存中。
4、上一步內存中的結果是要進行reduce的,于是這些map worker就把這些數據的位置返回給master,這樣master知道數據位置就可以繼續分配reduce任務,起到了連接map和reduce函數的作用。
5、reduce worker知道這些數據的位置后就去相應位置讀取這些數據,并對這些數據按key進行排序。將排序后的數據序列放入reduce函數中進行合并和規約,最后每個reduce任務輸出一個結果文件。
6、任務結束,master解除阻塞,喚醒用戶。
以上是個人的一些理解,有不對的地方請指出。
三、BigTable,分布式的結構化數據存儲系統?
BigTable是基于GFS和MapReduce之上的,那么google既然已經有了GFS,為何還要有BigTable呢(也是我原先的一個疑問)?后來想想這和已經有操作系統文件系統為何還要有SQL SERVER數據庫一樣的道理,GFS是更底層的文件系統,而BigTable建立在其上面,不僅可以存儲結構化的數據,而且可以更好的管理和做出負載均衡決策。
以下是BigTable的架構圖:
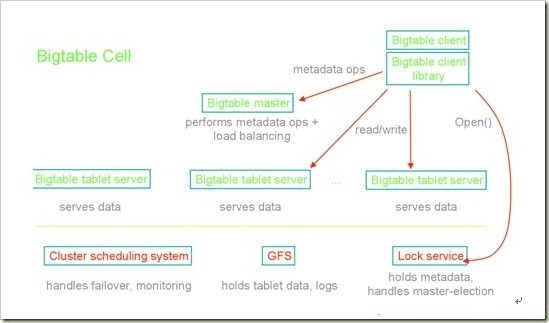
它完全是一個基于key/value的數據庫,和一般的關系型數據庫不同,google之所以采用BigTable,因為它在滿足需求的同時簡化了系統,比如去掉了事務、死鎖檢測等模塊,讓系統更高效。更重要的一點是在BigTable中數據是沒有格式的,它僅僅是一個個key/value的pairs,用戶可以自己去定義數據的格式,這也大大提高了BigTable的靈活性和擴展性。
四、總結
這篇隨筆主要是一些總結性的內容,Google架構遠遠不止這些。
