目錄
- 1.集成算法
- 1.1袋裝算法
- 1.1.1袋裝決策樹
- 1.1.2隨機(jī)森林
- 1.1.3極端隨機(jī)樹
- 1.2提升算法
- 1.2.1AdaBoost
- 1.2.2隨機(jī)梯度提升
- 1.3投票算法
- 2.算法調(diào)參
- 2.1網(wǎng)絡(luò)搜索優(yōu)化參數(shù)
- 2.2隨機(jī)搜索優(yōu)化參數(shù)
- 總結(jié)
有時(shí)提升一個(gè)模型的準(zhǔn)確度很困難。你會(huì)嘗試所有曾學(xué)習(xí)過的策略和算法,但模型正確率并沒有改善。這時(shí)你會(huì)覺得無助和困頓,這也正是90%的數(shù)據(jù)科學(xué)家開始放棄的時(shí)候。不過,這才是考驗(yàn)真正本領(lǐng)的時(shí)候!這也是普通的數(shù)據(jù)科學(xué)家和大師級(jí)數(shù)據(jù)科學(xué)家的差距所在。
1.集成算法
三個(gè)臭皮匠,頂個(gè)諸葛亮。群體的智慧是很強(qiáng)大的。那么,在機(jī)器學(xué)習(xí)中能否同樣采用此策略呢?答案是肯定的,就是集成算法——將多個(gè)不同算法從集成起來,使結(jié)果更優(yōu)。
1.1袋裝算法
袋裝算法是一種提高分類準(zhǔn)確率的算法。通過給定組合投票的方式獲得最優(yōu)解。比如你生病了,去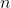 個(gè)醫(yī)院看了個(gè)醫(yī)生,每個(gè)醫(yī)生都給你開了藥方,最后哪個(gè)藥方的出現(xiàn)次數(shù)多,就說明這個(gè)藥方可能是最優(yōu)解。
個(gè)醫(yī)院看了個(gè)醫(yī)生,每個(gè)醫(yī)生都給你開了藥方,最后哪個(gè)藥方的出現(xiàn)次數(shù)多,就說明這個(gè)藥方可能是最優(yōu)解。
1.1.1袋裝決策樹
袋裝算法在數(shù)據(jù)具有很大方差時(shí)非常有效,最常見的例子就是決策樹的袋裝算法。
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
array = data.values
X = array[:,0:8]
Y = array[:,8]
num_folds = 10
seed = 7
kfold = KFold(n_splits=num_folds,shuffle=True,random_state=seed)
#袋裝決策樹
cart = DecisionTreeClassifier()
num_tree = 100
model = BaggingClassifier(base_estimator=cart,n_estimators=num_tree,random_state=seed)
result = cross_val_score(model, X, Y, cv=kfold)
print(result.mean())
0.7578263841421736
1.1.2隨機(jī)森林
隨機(jī)森林是由很多決策樹構(gòu)成的,不同決策樹之間沒有關(guān)聯(lián)。
當(dāng)我們進(jìn)行分類任務(wù)時(shí),新的輸入樣本進(jìn)入,就讓森林中的每一棵決策樹分別進(jìn)行判斷和分類,每個(gè)決策樹會(huì)得到一個(gè)自己的分類結(jié)果,決策樹的分類結(jié)果中哪一個(gè)分類最多,那么隨機(jī)森林就會(huì)把這個(gè)結(jié)果當(dāng)做最終的結(jié)果。
from sklearn.ensemble import RandomForestClassifier
#隨機(jī)森林
num_tree = 100
max_features = 3
model = RandomForestClassifier(n_estimators=num_tree,random_state=seed,max_features=max_features)
result = cross_val_score(model, X, Y, cv=kfold)
print(result.mean())
0.759107997265892
1.1.3極端隨機(jī)樹
極端隨機(jī)數(shù)與隨機(jī)森林十分相似,都是由許多決策樹構(gòu)成的,但它與隨機(jī)森林由兩個(gè)主要區(qū)別:
- 隨機(jī)森林應(yīng)用的是Bagging模型,而極端隨機(jī)樹是使用所有的訓(xùn)練樣本得到每棵決策樹,也就是每棵決策樹應(yīng)用的是全部訓(xùn)練樣本。
- 隨機(jī)森林是在一個(gè)隨機(jī)子集內(nèi)得到最優(yōu)分叉特征屬性,而極端隨機(jī)樹是完全隨機(jī)地選擇分叉特征屬性,從而實(shí)現(xiàn)對(duì)決策樹進(jìn)行分叉。
from sklearn.ensemble import ExtraTreesClassifier
#極端隨機(jī)樹
num_tree = 100
max_features = 3
model = ExtraTreesClassifier(n_estimators=num_tree,random_state=seed,max_features=max_features)
result = cross_val_score(model, X, Y, cv=kfold)
print(result.mean())
0.7630211893369789
1.2提升算法
提升算法也稱為boosting算法,它是將弱學(xué)習(xí)算法提升為強(qiáng)學(xué)習(xí)算法的一類算法,可用來提升弱分類器的準(zhǔn)確度。
1.2.1AdaBoost
AdaBoost是一種迭代算法,其核心思想是針對(duì)同一個(gè)訓(xùn)練集訓(xùn)練不同的分類器(弱分類器),然后把這些弱分類器集合起來,構(gòu)成一個(gè)更強(qiáng)的最終分類器(強(qiáng)分類器)。
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import AdaBoostClassifier
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
array = data.values
X = array[:,0:8]
Y = array[:,8]
num_folds = 10
seed = 7
kfold = KFold(n_splits=num_folds,shuffle=True,random_state=seed)
#AdaBost
num_tree = 100
model = AdaBoostClassifier(n_estimators=num_tree,random_state=seed)
result = cross_val_score(model, X, Y, cv=kfold)
print(result.mean())
0.7578605604921395
1.2.2隨機(jī)梯度提升
隨機(jī)梯度提升法(GBM)的基本思想是:要找到某個(gè)函數(shù)的最大值,最好的辦法就是沿著該函數(shù)的梯度方向探尋。梯度算子總是指向函數(shù)增長值最快的方向。
from sklearn.ensemble import GradientBoostingClassifier
#隨機(jī) 梯度提升
num_tree = 100
model = GradientBoostingClassifier(n_estimators=num_tree,random_state=seed)
result = cross_val_score(model, X, Y, cv=kfold)
print(result.mean())
0.7591934381408066
1.3投票算法
投票算法(Voting)是一個(gè)非常簡單的多個(gè)機(jī)器學(xué)習(xí)算法的集成算法。投票算法是通過創(chuàng)建兩個(gè)或多個(gè)算法模型,利用投票算法將這些算法包裝起來,計(jì)算各個(gè)子模型的平均預(yù)測情況。
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import VotingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
array = data.values
X = array[:,0:8]
Y = array[:,8]
num_folds = 10
seed = 7
kfold = KFold(n_splits=num_folds,shuffle=True,random_state=seed)
#投票算法
models=[]
model_logistic = LogisticRegression(max_iter=3000)
model_cart = DecisionTreeClassifier()
model_svc = SVC()
models.append(('logistic',model_logistic))
models.append(('cart',model_cart))
models.append(('svc',model_svc))
ensemble_model = VotingClassifier(estimators=models)
result = cross_val_score(ensemble_model, X, Y, cv=kfold)
print(result.mean())
0.7721804511278196
2.算法調(diào)參
機(jī)器學(xué)習(xí)的模型都是參數(shù)化的,可以通過調(diào)參來提高模型的準(zhǔn)確度。模型參數(shù)的調(diào)整應(yīng)該遵循偏差和方差協(xié)調(diào)的原則。
調(diào)整算法參數(shù)是機(jī)器學(xué)習(xí)解決問題的最后一個(gè)步驟,有時(shí)也被成為超參數(shù)優(yōu)化。學(xué)會(huì)調(diào)參是進(jìn)行機(jī)器學(xué)習(xí)項(xiàng)目的前提。參數(shù)可分為兩種:一種是影響模型在訓(xùn)練集上的準(zhǔn)確度或防止過擬合能力的參數(shù);另一種是不影響這兩者的參數(shù)。模型在樣本總體上的準(zhǔn)確度由其在訓(xùn)練集上的準(zhǔn)確度及其防止過擬合的能力共同決定,所以在調(diào)參時(shí)主要針對(duì)第一種參數(shù)進(jìn)行調(diào)整,最終達(dá)到的效果是:模型在訓(xùn)練集上的準(zhǔn)確度和防止過擬合能力的大和諧。
2.1網(wǎng)絡(luò)搜索優(yōu)化參數(shù)
網(wǎng)格搜索優(yōu)化參數(shù)是一種算法參數(shù)優(yōu)化的方法。它是通過遍歷已定義參數(shù)的列表,來評(píng)估算法的參數(shù),從而找到最優(yōu)參數(shù)。
from pandas import read_csv
from sklearn.linear_model import Ridge
from sklearn.model_selection import GridSearchCV
#導(dǎo)入數(shù)據(jù)
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
#將數(shù)據(jù)分為輸入數(shù)據(jù)和輸出結(jié)果
array = data.values
X = array[:,0:8]
Y = array[:,8]
#算法實(shí)例化
model = Ridge()
#設(shè)置要遍歷的參數(shù)
param_grid = {'alpha':[1,0.1,0.01,0.001,0]}
#通過網(wǎng)格搜索查詢最優(yōu)參數(shù)
grid = GridSearchCV(model, param_grid)
grid.fit(X,Y)
#搜索結(jié)果
print('max_score:%.3f'% grid.best_score_)
print('best_para:%.3f'% grid.best_estimator_.alpha)
max_score:0.276
best_para:1.000
2.2隨機(jī)搜索優(yōu)化參數(shù)
隨機(jī)搜索優(yōu)化參數(shù)是另一種對(duì)算法參數(shù)優(yōu)化的方法。隨機(jī)搜索優(yōu)化參數(shù)通過固定次數(shù)的迭代,采用隨機(jī)采樣分布的方式搜索合適的參數(shù)。
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform
#隨即搜索優(yōu)化參數(shù)
grid = RandomizedSearchCV(model, param_grid,100,random_state=7)
grid.fit(X,Y)
#搜索結(jié)果
print('max_score:%.3f'% grid.best_score_)
print('best_para:%.3f'% grid.best_estimator_.alpha)
max_score:0.276
best_para:1.000
總結(jié)
本文主要講解了如何優(yōu)化模型,包括集成算法和算法調(diào)參,這些都是在實(shí)際項(xiàng)目中非常有用的。
到此這篇關(guān)于Python機(jī)器學(xué)習(xí)入門(六)優(yōu)化模型的文章就介紹到這了,更多相關(guān)Python機(jī)器學(xué)習(xí)內(nèi)容請(qǐng)搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Python機(jī)器學(xué)習(xí)入門(一)序章
- Python機(jī)器學(xué)習(xí)入門(二)之Python數(shù)據(jù)理解
- Python機(jī)器學(xué)習(xí)入門(三)之Python數(shù)據(jù)準(zhǔn)備
- Python機(jī)器學(xué)習(xí)入門(四)之Python選擇模型
- Python機(jī)器學(xué)習(xí)入門(五)之Python算法審查
- python機(jī)器學(xué)習(xí)高數(shù)篇之函數(shù)極限與導(dǎo)數(shù)
