目錄
- pyspark 操作hive表
- 1> saveAsTable寫入
- 2> insertInto寫入
- 3>saveAsTextFile寫入直接操作文件
pyspark 操作hive表
pyspark 操作hive表,hive分區(qū)表動態(tài)寫入;最近發(fā)現(xiàn)spark動態(tài)寫入hive分區(qū),和saveAsTable存表方式相比,文件壓縮比大約 4:1。針對該問題整理了 spark 操作hive表的幾種方式。
1> saveAsTable寫入
saveAsTable(self, name, format=None, mode=None, partitionBy=None, **options)
示例:
df.write.saveAsTable("表名",mode='overwrite')
注意:
1、表不存在則創(chuàng)建表,表存在全覆蓋寫入;
2、表存在,數(shù)據(jù)字段有變化,先刪除后重新創(chuàng)建表;
3、當正在存表時報錯或者終止程序會導致表丟失;
4、數(shù)據(jù)默認采用parquet壓縮,文件名稱 part-00000-5efbfc08-66fe-4fd1-bebb-944b34689e70.gz.parquet
數(shù)據(jù)文件在hdfs上顯示:
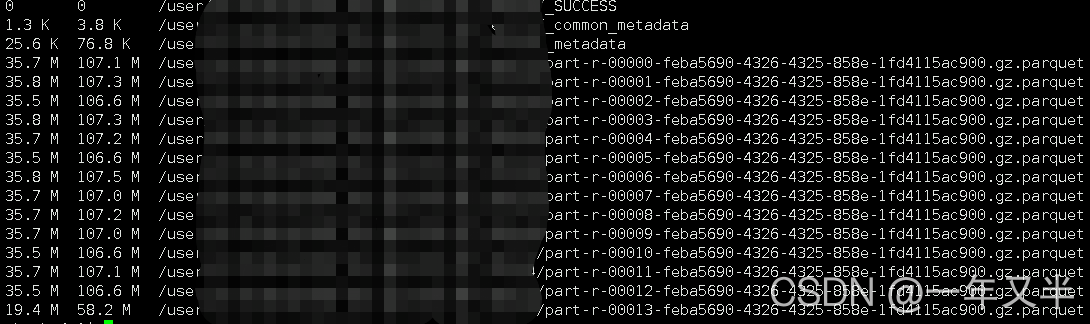
2> insertInto寫入
insertInto(self, tableName, overwrite=False):
示例:
# append 寫入
df.repartition(1).write.partitionBy('dt').insertInto("表名")
# overwrite 寫入
df.repartition(1).write.partitionBy('dt').insertInto("表名",overwrite=True)
# 動態(tài)分區(qū)使用該方法
注意:
1、df.write.mode("overwrite").partitionBy("dt").insertInto("表名") 不會覆蓋數(shù)據(jù)
2、需要表必須存在且當前DF的schema與目標表的schema必須一致
3、插入的文件不會壓縮;文件以part-00....結尾。文件較大
數(shù)據(jù)文件在hdfs上顯示:

2.1> 問題說明
兩種方式存儲數(shù)據(jù)量一樣的數(shù)據(jù),磁盤文件占比卻相差很大,.gz.parquet 文件 相比 part-00000文件要小很多。想用spark操作分區(qū)表,又想讓文件壓縮,百度了一些方式,都沒有解決。
從stackoverflow中有一個類似的問題 Spark compression when writing to external Hive table 。用里面的方法并沒有解決。
最終從hive表數(shù)據(jù)文件壓縮角度思考,問題得到解決。
hive 建表指定壓縮格式
下面是hive parquet的幾種壓縮方式
-- 使用snappy
CREATE TABLE if not exists ods.table_test(
id string,
open_time string
)
COMMENT '測試'
PARTITIONED BY (`dt` string COMMENT '按天分區(qū)')
row format delimited fields terminated by '\001'
STORED AS PARQUET
TBLPROPERTIES ('parquet.compression'='SNAPPY');
-- 使用gzip
CREATE TABLE if not exists ods.table_test(
id string,
open_time string
)
COMMENT '測試'
PARTITIONED BY (`dt` string COMMENT '按天分區(qū)')
row format delimited fields terminated by '\001'
STORED AS PARQUET
TBLPROPERTIES ('parquet.compression'='GZIP');
-- 使用uncompressed
CREATE TABLE if not exists ods.table_test(
id string,
open_time string
)
COMMENT '測試'
PARTITIONED BY (`dt` string COMMENT '按天分區(qū)')
row format delimited fields terminated by '\001'
STORED AS PARQUET
TBLPROPERTIES ('parquet.compression'='UNCOMPRESSED');
-- 使用默認
CREATE TABLE if not exists ods.table_test(
id string,
open_time string
)
COMMENT '測試'
PARTITIONED BY (`dt` string COMMENT '按天分區(qū)')
row format delimited fields terminated by '\001'
STORED AS PARQUET;
-- 設置參數(shù) set parquet.compression=SNAPPY;
2.2> 解決辦法
建表時指定TBLPROPERTIES,采用gzip 壓縮
示例:
drop table if exists ods.table_test
CREATE TABLE if not exists ods.table_test(
id string,
open_time string
)
COMMENT '測試'
PARTITIONED BY (`dt` string COMMENT '按天分區(qū)')
row format delimited fields terminated by '\001'
STORED AS PARQUET
TBLPROPERTIES ('parquet.compression'='GZIP');
執(zhí)行效果
數(shù)據(jù)文件在hdfs上顯示:

可以看到文件大小占比已經(jīng)和 *.gz.parquet 文件格式一樣了
3>saveAsTextFile寫入直接操作文件
saveAsTextFile(self, path, compressionCodecClass=None)
該方式通過rdd 以文件形式直接將數(shù)據(jù)存儲在hdfs上。
示例:
rdd.saveAsTextFile('hdfs://表全路徑')
文件操作更多方式見官方文檔
到此這篇關于pyspark操作hive分區(qū)表及.gz.parquet和part-00000文件壓縮問題的文章就介紹到這了,更多相關pyspark hive分區(qū)表parquet內容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- 在python中使用pyspark讀寫Hive數(shù)據(jù)操作
- Pyspark讀取parquet數(shù)據(jù)過程解析
- pyspark對Mysql數(shù)據(jù)庫進行讀寫的實現(xiàn)
- pyspark給dataframe增加新的一列的實現(xiàn)示例
- Linux下遠程連接Jupyter+pyspark部署教程
- PyCharm+PySpark遠程調試的環(huán)境配置的方法
