目錄
- 1.預備知識
- 2.抓取CSDN數據接口
- 2.1 查看CSDN搜索引擎主頁
- 2.2測試CSDN搜索引擎的功能
- 2.3查看更多相關文章的信息
- 2.4抓取ajax異步請求數據
- 2.5 分析url地址
- 3. 使用scrapy爬取CSDN數據接口
- 3.1 start_requests
- 3.2使用parse函數提取數據
- 3.3保存成CSV文件
- 3.4 運行結果
- 4. 效果展示
1.預備知識
python語言,scrapy爬蟲基礎,json模塊,flask后端
2.抓取CSDN數據接口
使用谷歌抓包工具抓取CSDN搜索引擎的接口
2.1 查看CSDN搜索引擎主頁
查看CSDN搜索引擎主頁https://so.csdn.net/,截圖如下:
2.2測試CSDN搜索引擎的功能
測試CSDN搜索引擎的功能,嘗試輸入參數之后,查看返回的文章信息列表,測試如下:

經過測試發現,CSDN搜索引擎的主要功能是,搜索所有跟python有關的文章,然后根據文章熱度,點贊量,留言數進行一個綜合排序,展示給用戶排序后的文章結果。這樣來說,我們的主要任務就是利用抓包抓取到前后端傳輸數據的接口,通過接口,來實現整個搜索引擎的效果。
2.3查看更多相關文章的信息
讓我們把前端滑輪移到最后,發現并沒有頁數的標簽,而是通過自動加載數據來呈現,效果如下:
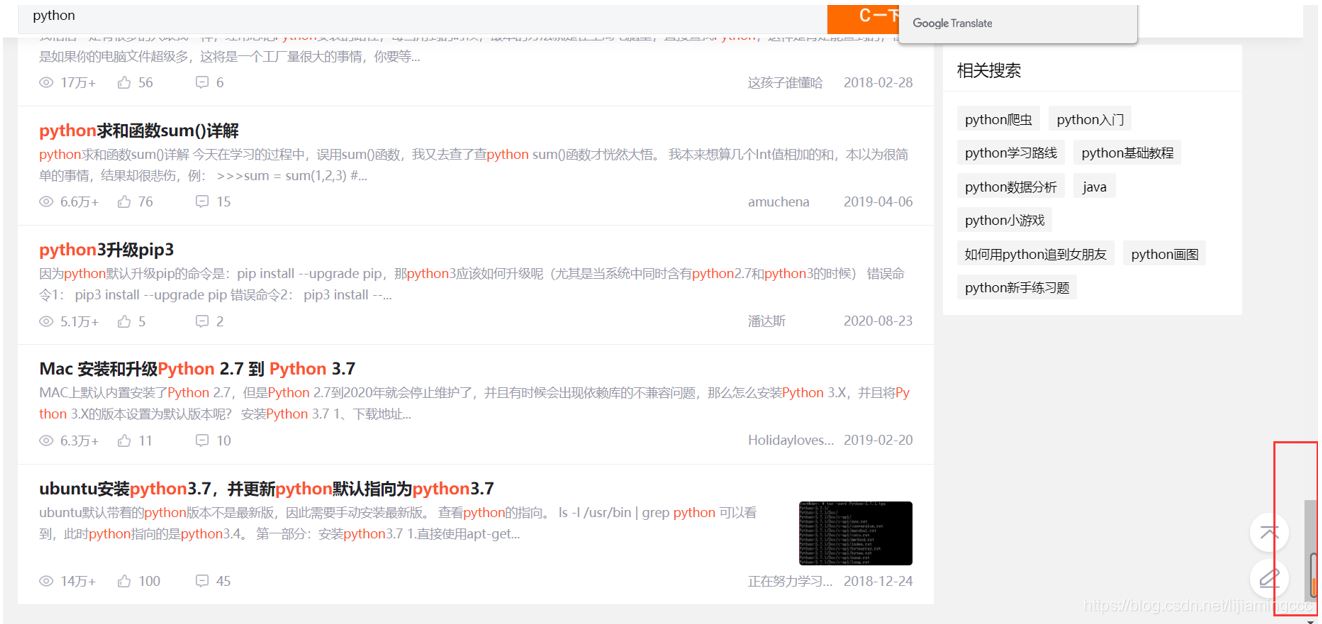
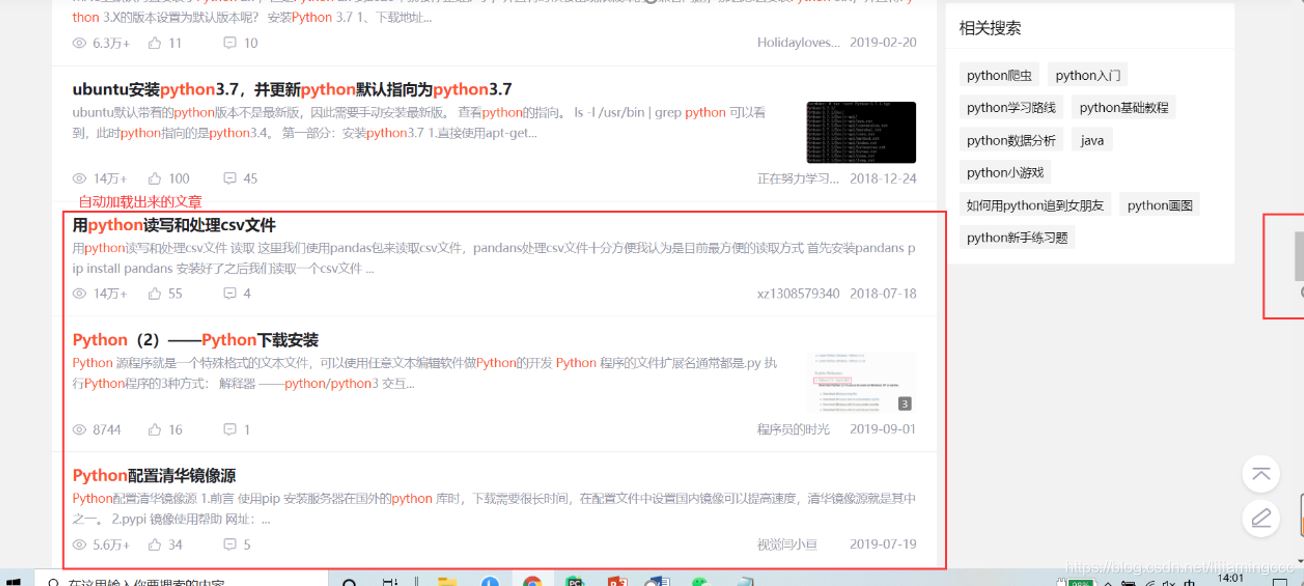
在不刷新整個頁面的基礎上加載新的數據,這很容易讓我們聯想到ajax異步請求。
異步請求通常就是利用ajax技術,能在不更新整個頁面的前提下維護數據。這使得Web應用程序更為迅捷地回應用戶動作,并避免了在網絡上發送那些沒有改變的信息。
接下來我們嘗試利用谷歌瀏覽器抓取異步請求的信息。
2.4抓取ajax異步請求數據
使用谷歌瀏覽器抓取ajax異步請求數據
為了避免干擾因素,我們在抓包前需要點擊clear按鈕,清空當前的抓包記錄
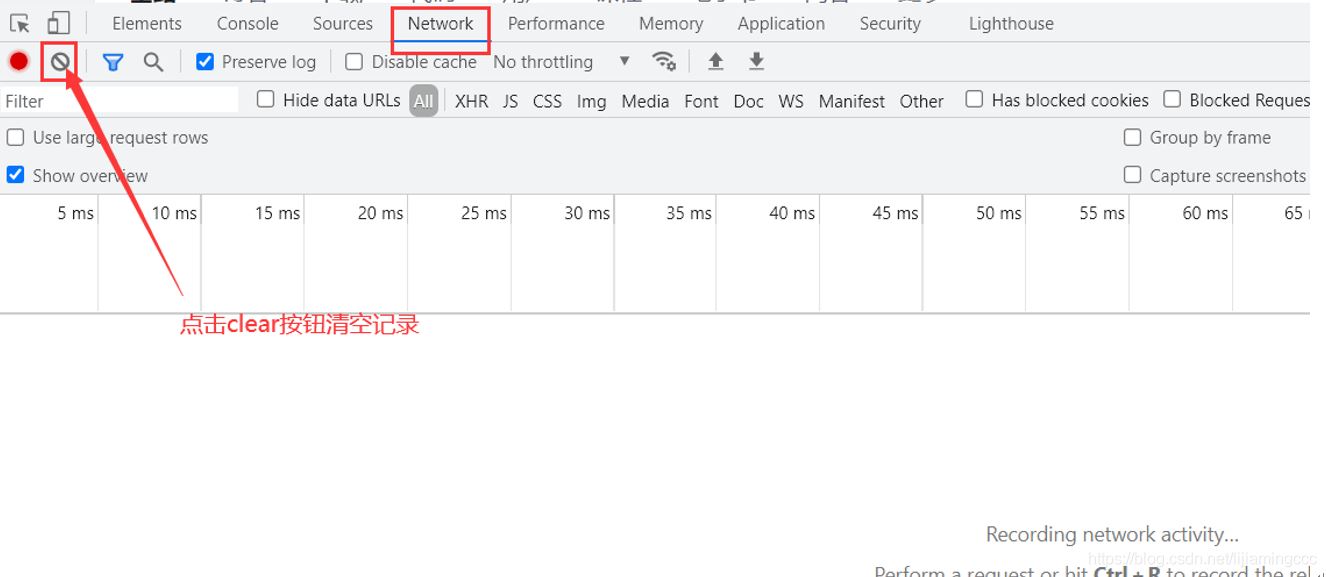
將滑塊移動到最后,使前端頁面自動加載數據,分析數據加載時抓取到的數據包信息。通過多次分析驗證,發現結果有一個get請求攜帶著大量的刷新時的數據。如下圖所示:
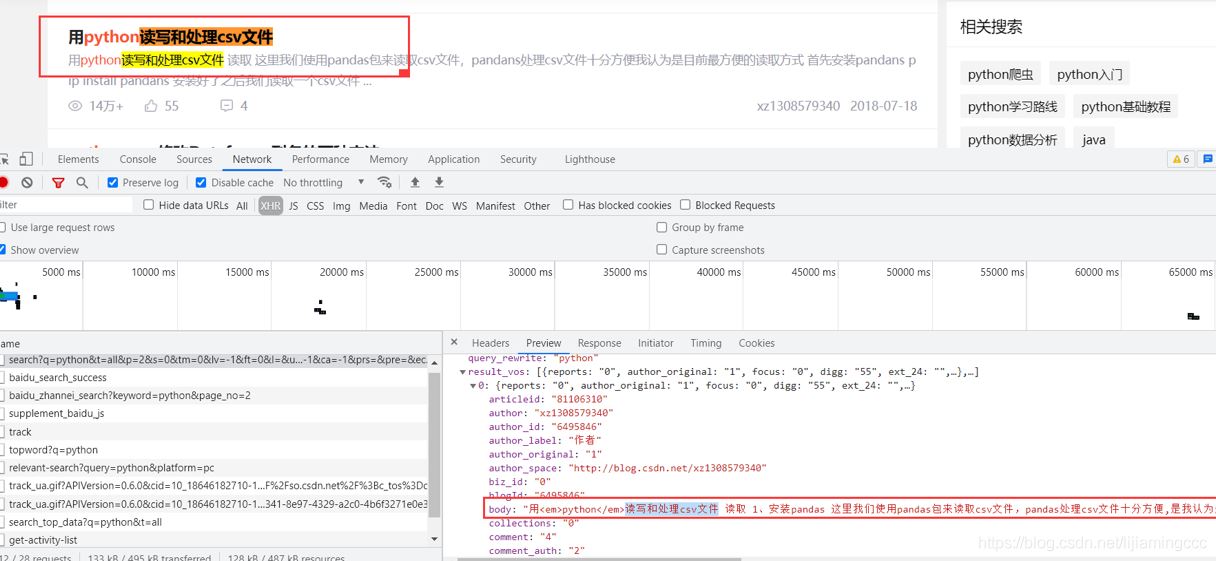
是JSON格式的數據,這里簡單介紹一下JSON格式的數據。
JSON 是前后端傳輸數據最常見的用法之一,是從 web 服務器上讀取 JSON 數據(作為文件或作為 HttpRequest),將 JSON 數據轉換為 JavaScript 對象,然后在網頁中使用該數據。
通過分析,我們可以發現數據是存放在result_vos列表下的各個字典中的,我們可以使用循環,然后通過dict[“xxx”]的方式來提取數據。
2.5 分析url地址

我們發現這個GET請求攜帶了大量的未知參數,通過經驗分析,以及英語首字母,我們可以猜測P是page(頁),Q是query(查詢)的意思,其他xxx=-1應該是默認值,我們暫時按照這個猜測進行刪減參數。
測試結果截圖:
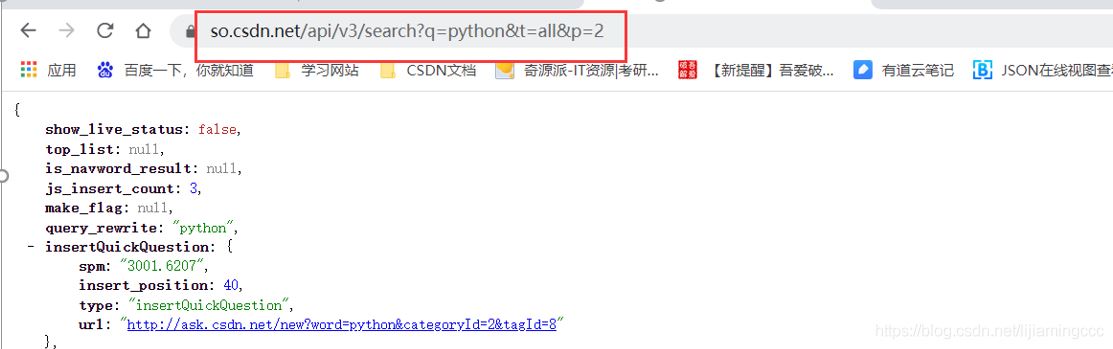
通過測試,發現猜測正確,只保留了q、t、p三個參數,依然可以訪問到傳輸的數據內容(事實上,這里t參數也可以刪除,同學們可以自行測試)
這樣,這條url對應的重要參數都分析出來了,鏈接如下:
https://so.csdn.net/api/v3/search?q=pythont=allp=2
跟我們猜測的一樣,q是代表查詢,p是代表page,這樣我們已經獲取到CSDN引擎的核心API,我們可以通過這條API來實現搜索引擎的功能。
至此,抓包分析過程結束。
3. 使用scrapy爬取CSDN數據接口
3.1 start_requests
使用start_requests函數進行構造20頁的url列表。
這里start_requests方法必須返回一個可迭代對象(iterable)。該對象包含了spider用于抓取的第一個Request。
當spider開始抓取并且未指定start_urls時,該方法將會被調用。該方法僅僅會被scrapy調用一次,因此可以將其實現為url生成器。
使用scrapy.Request可以發送一個GET請求,傳送到指定的函數進行處理。
詳細代碼操作如下:
# 重寫start_urls的方法
def start_requests(self):
# 這里是控制CSDN的文章類型
input_text = input('請輸入要爬取的CSDN類型:')
# 是控制爬取文章頁數
for i in range(1,31):
start_url = 'https://so.csdn.net/api/v3/search?q={}p={}'.format(input_text,i)
yield scrapy.Request(
url=start_url,
callback=self.parse
)
3.2使用parse函數提取數據
這里需要掌握幾個重要的方法應用
- response.text 請求返回的響應的字符串格式的數據
- json.loads() loads方法是將str轉化為dict格式數據
- json.dumps() dumps方法是將dict格式的數據轉化為str
具體代碼操作如下:
data_dict = json.loads(response.text)
使用循環遍歷json數據中的各個具體直播間數據的信息,新建一個item字典進行數據存儲,然后使用yield傳遞給引擎進行相應的處理
代碼操作如下:
def parse(self, response):
# response.request.headers
print(response.request.headers)
data_dict = json.loads(response.text)
for data in data_dict['result_vos']:
item = {}
# 標題
item['title'] = data['title'].replace('em>','').replace('/em>','')
# 作者
item['author_label'] = data['nickname']
# 瀏覽量
item['view'] = data['view']
# 點贊量
item['zan'] = data['digg']
# 地址鏈接
item['link_url'] = data['url']
3.3保存成CSV文件
import csv
定義csv文件需要的列標題
headers = ['title','author_label','view','zan','jianjie' ,'link_url']
每次調用pipline的時候,都會運行一遍
class Day02Pipeline:
def process_item(self, item, spider):
文件默認保存到當前目錄下的douyu.csv中
這里a是追加操作
with open('csdn.csv', 'a', encoding='utf-8', newline='') as fa:
保存headers規定的列名內容
writer = csv.DictWriter(fa, headers)
writer.writerow(item)
print(item)
return item
3.4 運行結果
最后,我們來查看一下運行結果,以及保存好的csv文件
終端運行結果如下:
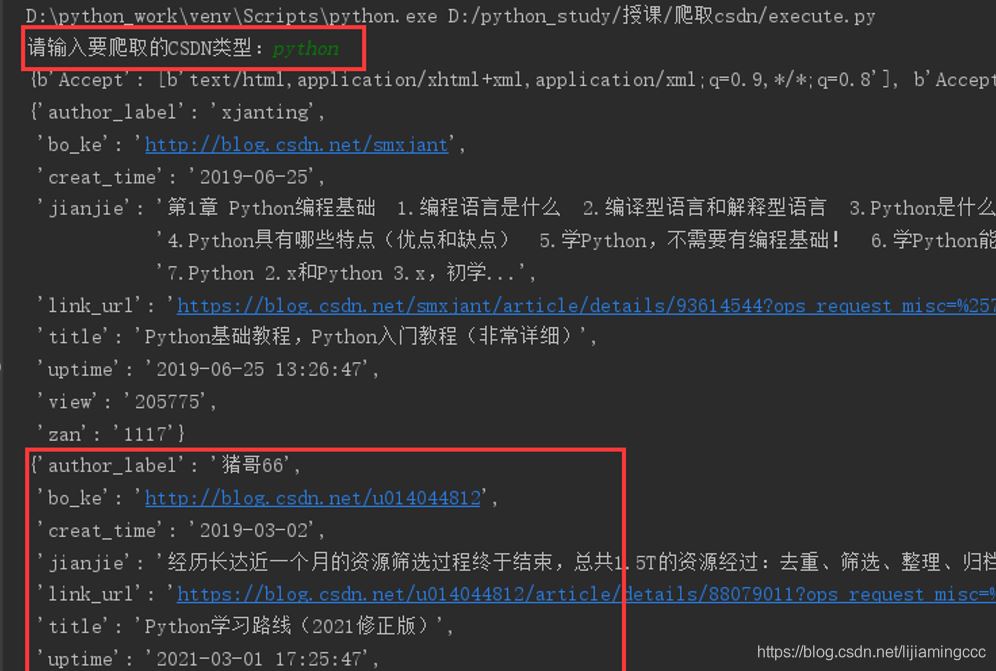

至此,爬蟲實驗結束。
4. 效果展示
4.1 flask后端展示
搭建過程略
(入門級搭建,沒有用企業級開發流程,后期可以考慮出flask的教程)
展示結構如下:
flask入門可自行百度
4.2 效果展示
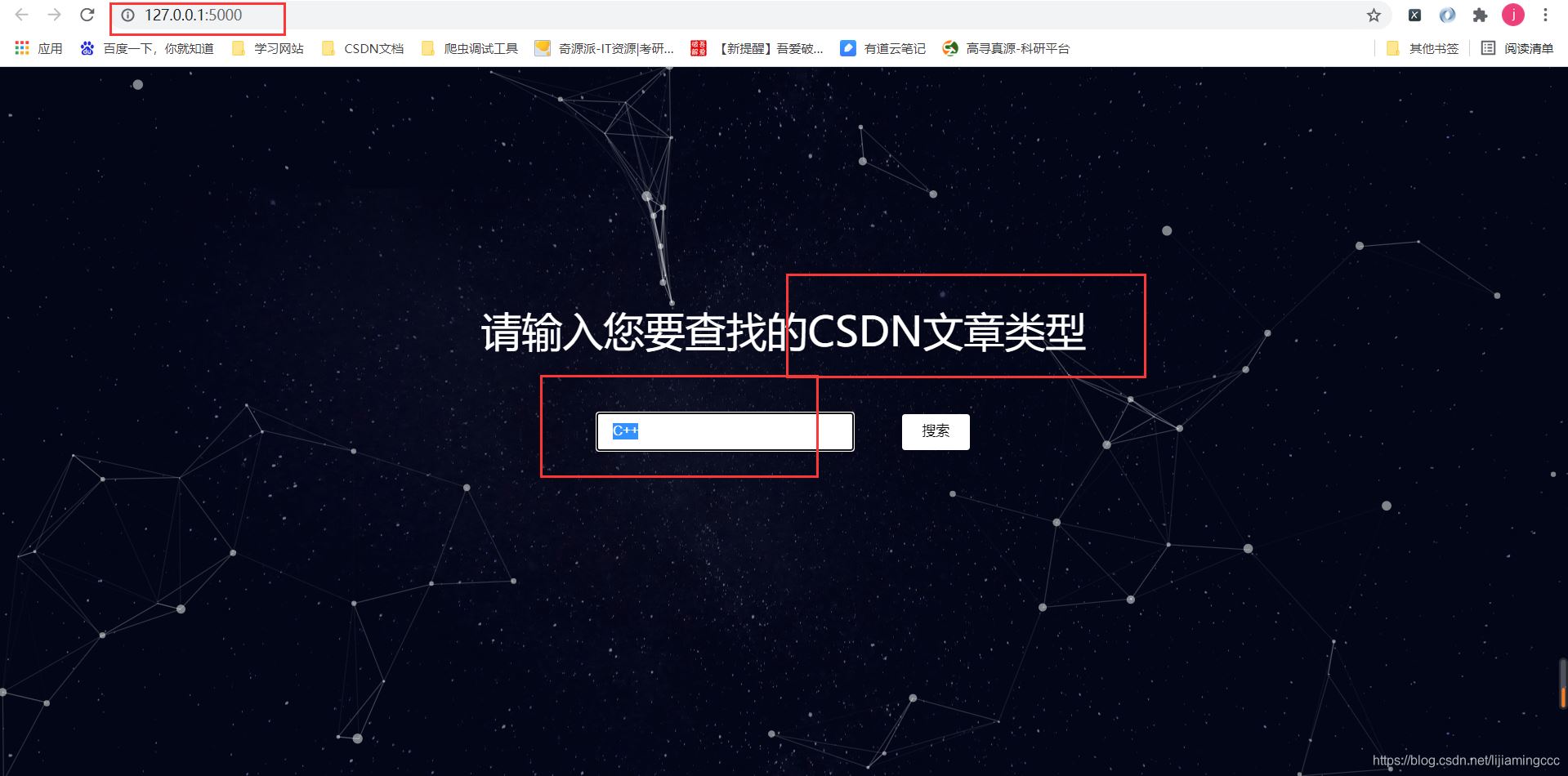
點擊搜索后:

左上角的搜索頁面是入口頁面。
好了,這樣簡易版的搜索引擎就搭建好了。更多相關scrapy+flask+html搜索引擎內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Mysql實現簡易版搜索引擎的示例代碼
- MySQL全文索引實現簡單版搜索引擎實例代碼
- 詳細介紹基于MySQL的搜索引擎MySQL-Fullltext
- python基于搜索引擎實現文章查重功能
- Python實戰之手寫一個搜索引擎
- Python大批量搜索引擎圖像爬蟲工具詳解
- 360搜索引擎自動收錄php改寫方案
- php記錄搜索引擎爬行記錄的實現代碼
- Python無損音樂搜索引擎實現代碼
- 基于 Mysql 實現一個簡易版搜索引擎
