scrapy框架概述:Scrapy,Python開(kāi)發(fā)的一個(gè)快速,高層次的屏幕抓取和web抓取框架,用于抓取web站點(diǎn)并從頁(yè)面中提取結(jié)構(gòu)化的數(shù)據(jù)。Scrapy用途廣泛,可以用于數(shù)據(jù)挖掘、監(jiān)測(cè)和自動(dòng)化測(cè)試。
創(chuàng)建項(xiàng)目
由于pycharm不能直接創(chuàng)建scrapy項(xiàng)目,必須通過(guò)命令行創(chuàng)建,所以相關(guān)操作在pycharm的終端進(jìn)行:
1、安裝scrapy模塊:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy
2、創(chuàng)建一個(gè)scrapy項(xiàng)目:scrapy startproject test_scrapy
4、生成一個(gè)爬蟲(chóng):scrapy genspider itcast "itcast.cn”
5、提取數(shù)據(jù):完善spider,使用xpath等方法
6、保存數(shù)據(jù):pipeline中保存數(shù)據(jù)
常用的命令
創(chuàng)建項(xiàng)目:scrapy startproject xxx
進(jìn)入項(xiàng)目:cd xxx #進(jìn)入某個(gè)文件夾下
創(chuàng)建爬蟲(chóng):scrapy genspider xxx(爬蟲(chóng)名) xxx.com (爬取域)
生成文件:scrapy crawl xxx -o xxx.json (生成某種類型的文件)
運(yùn)行爬蟲(chóng):scrapy crawl XXX
列出所有爬蟲(chóng):scrapy list
獲得配置信息:scrapy settings [options]
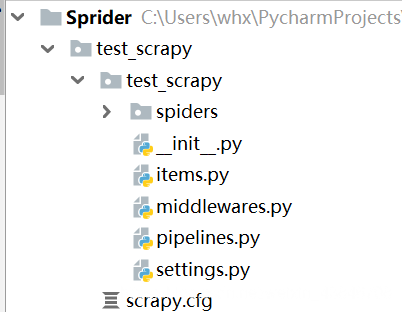
Scrapy項(xiàng)目下文件
scrapy.cfg: 項(xiàng)目的配置文件
test_scrapy/: 該項(xiàng)目的python模塊。在此放入代碼(核心)
test_scrapy/items.py: 項(xiàng)目中的item文件.(這是創(chuàng)建容器的地方,爬取的信息分別放到不同容器里)
test_scrapy/pipelines.py: 項(xiàng)目中的pipelines文件.
test_scrapy/settings.py: 項(xiàng)目的設(shè)置文件.(我用到的設(shè)置一下基礎(chǔ)參數(shù),比如加個(gè)文件頭,設(shè)置一個(gè)編碼)
test_scrapy/spiders/: 放置spider代碼的目錄. (放爬蟲(chóng)的地方)
scrapy框架的整體執(zhí)行流程
1.spider的yeild將request發(fā)送給engine
2.engine對(duì)request不做任何處理發(fā)送給scheduler
3.scheduler,生成request交給engine
4.engine拿到request,通過(guò)middleware發(fā)送給downloader
5.downloader在\獲取到response之后,又經(jīng)過(guò)middleware發(fā)送給engine
6.engine獲取到response之后,返回給spider,spider的parse()方法對(duì)獲取到的response進(jìn)行處理,解析出items或者requests
7.將解析出來(lái)的items或者requests發(fā)送給engine
8.engine獲取到items或者requests,將items發(fā)送給ItemPipeline,將requests發(fā)送給scheduler(ps,只有調(diào)度器中不存在request時(shí),程序才停止,及時(shí)請(qǐng)求失敗scrapy也會(huì)重新進(jìn)行請(qǐng)求)
關(guān)于yeild函數(shù)介紹
簡(jiǎn)單地講,yield 的作用就是把一個(gè)函數(shù)變成一個(gè) generator(生成器),帶有 yield 的函數(shù)不再是一個(gè)普通函數(shù),Python 解釋器會(huì)將其視為一個(gè) generator,帶有yeild的函數(shù)遇到y(tǒng)eild的時(shí)候就返回一個(gè)迭代值,下次迭代時(shí), 代碼從 yield 的下一條語(yǔ)句繼續(xù)執(zhí)行,而函數(shù)的本地變量看起來(lái)和上次中斷執(zhí)行前是完全一樣的,于是函數(shù)繼續(xù)執(zhí)行, 直到再次遇到 yield。
通俗的講就是:在一個(gè)函數(shù)中,程序執(zhí)行到y(tǒng)ield語(yǔ)句的時(shí)候,程序暫停,返回yield后面表達(dá)式的值,在下一次調(diào)用的時(shí)候,從yield語(yǔ)句暫停的地方繼續(xù)執(zhí)行,如此循環(huán),直到函數(shù)執(zhí)行完。
到此這篇關(guān)于python3 scrapy框架的執(zhí)行流程的文章就介紹到這了,更多相關(guān)python3 scrapy框架內(nèi)容請(qǐng)搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python3 Scrapy爬蟲(chóng)框架ip代理配置的方法
- Python3環(huán)境安裝Scrapy爬蟲(chóng)框架過(guò)程及常見(jiàn)錯(cuò)誤
- Python3爬蟲(chóng)爬取英雄聯(lián)盟高清桌面壁紙功能示例【基于Scrapy框架】
- Centos7 Python3下安裝scrapy的詳細(xì)步驟
- python3使用scrapy生成csv文件代碼示例
- Python3安裝Scrapy的方法步驟
- CentOS下安裝python3.5+scrapy的方法步驟
- windows10系統(tǒng)中安裝python3.x+scrapy教程
