import os
import time
import json
import random
import csv
import re
import jieba
import requests
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# 詞云形狀圖片
WC_MASK_IMG = 'jdicon.jpg'
# 評論數據保存文件
COMMENT_FILE_PATH = 'jd_comment.txt'
# 詞云字體
WC_FONT_PATH = '/Library/Fonts/Songti.ttc'
def spider_comment(page=0, key=0):
"""
爬取京東指定頁的評價數據
:param page: 爬取第幾,默認值為0
"""
url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv4646productId=' + key + '' \
'score=0sortType=5page=%spageSize=10isShadowSku=0fold=1' % page
kv = {'user-agent': 'Mozilla/5.0', 'Referer': 'https://item.jd.com/'+ key + '.html'}#原本key不輸入值,默認為《三體》
try:
r = requests.get(url, headers=kv)
r.raise_for_status()
except:
print('爬取失敗')
# 截取json數據字符串
r_json_str = r.text[26:-2]
# 字符串轉json對象
r_json_obj = json.loads(r_json_str)
# 獲取評價列表數據
r_json_comments = r_json_obj['comments']
# 遍歷評論對象列表
for r_json_comment in r_json_comments:
# 以追加模式換行寫入每條評價
with open(COMMENT_FILE_PATH, 'a+') as file:
file.write(r_json_comment['content'] + '\n')
# 打印評論對象中的評論內容
print(r_json_comment['content'])
def batch_spider_comment():
"""
批量爬取某東評價
"""
# 寫入數據前先清空之前的數據
if os.path.exists(COMMENT_FILE_PATH):
os.remove(COMMENT_FILE_PATH)
key = input("Please enter the address:")
key = re.sub("\D","",key)
#通過range來設定爬取的頁面數
for i in range(10):
spider_comment(i,key)
# 模擬用戶瀏覽,設置一個爬蟲間隔,防止ip被封
time.sleep(random.random() * 5)
def cut_word():
"""
對數據分詞
:return: 分詞后的數據
"""
with open(COMMENT_FILE_PATH) as file:
comment_txt = file.read()
wordlist = jieba.cut(comment_txt, cut_all=False)#精確模式
wl = " ".join(wordlist)
print(wl)
return wl
def create_word_cloud():
"""44144127306
生成詞云
:return:
"""
# 設置詞云形狀圖片
wc_mask = np.array(Image.open(WC_MASK_IMG))
# 設置詞云的一些配置,如:字體,背景色,詞云形狀,大小
wc = WordCloud(background_color="white", max_words=2000, mask=wc_mask, scale=4,
max_font_size=50, random_state=42, font_path=WC_FONT_PATH)
# 生成詞云
wc.generate(cut_word())
# 在只設置mask的情況下,你將會得到一個擁有圖片形狀的詞云
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.figure()
plt.show()
wc.to_file("jd_ciyun.jpg")
def txt_change_to_csv():
with open('jd_comment.csv', 'w+', encoding="utf8", newline='')as c:
writer_csv = csv.writer(c, dialect="excel")
with open("jd_comment.txt", 'r', encoding='utf8')as f:
# print(f.readlines())
for line in f.readlines():
# 去掉str左右端的空格并以空格分割成list
line_list = line.strip('\n').split(',')
print(line_list)
writer_csv.writerow(line_list)
if __name__ == '__main__':
# 爬取數據
batch_spider_comment()
#轉換數據
txt_change_to_csv()
# 生成詞云
create_word_cloud()
# -*-coding:utf-8-*-
def train():
from snownlp import sentiment
print("開始訓練數據集...")
sentiment.train('negative.txt', 'positive.txt')#自己準備數據集
sentiment.save('sentiment.marshal')#保存訓練模型
#python2保存的是sentiment.marshal;python3保存的是sentiment.marshal.3
"訓練完成后,將訓練完的模型,替換sentiment中的模型"
def main():
train() # 訓練正負向商品評論數據集
print("數據集訓練完成!")
if __name__ == '__main__':
main()
from snownlp import sentiment
import pandas as pd
import snownlp
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
#from word_cloud import word_cloud_creation, word_cloud_implementation, word_cloud_settings
def read_csv():
'''讀取商品評論數據文件'''
comment_data = pd.read_csv('jd_comment.csv', encoding='utf-8',
sep='\n', index_col=None)
#返回評論作為參數
return comment_data
def clean_data(data):
'''數據清洗'''
df = data.dropna() # 消除缺失數據 NaN為缺失數據
df = pd.DataFrame(df.iloc[:, 0].unique()) # 數據去重
return df
# print('數據清洗后:', len(df))
def clean_repeat_word(raw_str, reverse=False):
'''去除評論中的重復使用的詞匯'''
if reverse:
raw_str = raw_str[::-1]
res_str = ''
for i in raw_str:
if i not in res_str:
res_str += i
if reverse:
res_str = res_str[::-1]
return res_str
def processed_data(filename):
'''清洗完畢的數據,并保存'''
df = clean_data(read_csv())#數據清洗
ser1 = df.iloc[:, 0].apply(clean_repeat_word)#去除重復詞匯
df2 = pd.DataFrame(ser1.apply(clean_repeat_word, reverse=True))
df2.to_csv(f'{filename}.csv', encoding='utf-8', index_label=None, index=None)
def train():
'''訓練正向和負向情感數據集,并保存訓練模型'''
sentiment.train('negative.txt', 'positive.txt')
sentiment.save('seg.marshal')#python2保存的是sentiment.marshal;python3保存的是sentiment.marshal.3
sentiment_list = []
res_list = []
def test(filename, to_filename):
'''商品評論-情感分析-測試'''
with open(f'{filename}.csv', 'r', encoding='utf-8') as fr:
for line in fr.readlines():
s = snownlp.SnowNLP(line)
#調用snownlp中情感評分s.sentiments
if s.sentiments > 0.6:
res = '喜歡'
res_list.append(1)
elif s.sentiments 0.4:
res = '不喜歡'
res_list.append(-1)
else:
res = '一般'
res_list.append(0)
sent_dict = {
'情感分析結果': s.sentiments,
'評價傾向': res,
'商品評論': line.replace('\n', '')
}
sentiment_list.append(sent_dict)
print(sent_dict)
df = pd.DataFrame(sentiment_list)
df.to_csv(f'{to_filename}.csv', index=None, encoding='utf-8',
index_label=None, mode='w')
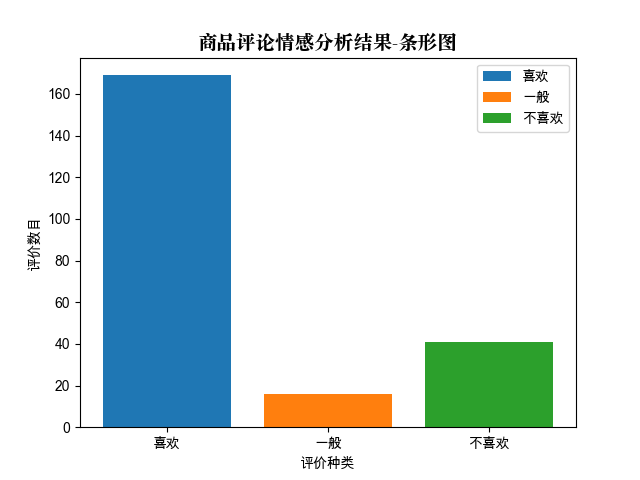
def data_virtualization():
'''分析結果可視化,以條形圖為測試樣例'''
font = FontProperties(fname='/System/Library/Fonts/Supplemental/Songti.ttc', size=14)
likes = len([i for i in res_list if i == 1])
common = len([i for i in res_list if i == 0])
unlikes = len([i for i in res_list if i == -1])
plt.bar([1], [likes], label='喜歡')#(坐標,評論長度,名稱)
plt.bar([2], [common], label='一般')
plt.bar([3], [unlikes], label='不喜歡')
x=[1,2,3]
label=['喜歡','一般','不喜歡']
plt.xticks(x, label)
plt.legend()#插入圖例
plt.xlabel('評價種類')
plt.ylabel('評價數目')
plt.title(u'商品評論情感分析結果-條形圖', FontProperties=font)
plt.savefig('fig.png')
plt.show()
'''
def word_cloud_show():
#將商品評論轉為高頻詞匯的詞云
wl = word_cloud_creation('jd_comment.csv')
wc = word_cloud_settings()
word_cloud_implementation(wl, wc)
'''
def main():
processed_data('processed_comment_data')#數據清洗
#train() # 訓練正負向商品評論數據集
test('jd_comment', 'result')
print('數據可視化中...')
data_virtualization() # 數據可視化
print('python程序運行結束。')
if __name__ == '__main__':
main()