Pytorch的backward()函數(shù)
假若有多個loss函數(shù),如何進(jìn)行反向傳播和更新呢?
x = torch.tensor(2.0, requires_grad=True)
y = x**2
z = x
# 反向傳播
y.backward()
x.grad
tensor(4.)
z.backward()
x.grad
tensor(5.) ## 累加
補(bǔ)充:Pytorch中torch.autograd ---backward函數(shù)的使用方法詳細(xì)解析,具體例子分析
backward函數(shù)
官方定義:
torch.autograd.backward(tensors, grad_tensors=None, retain_graph=None, create_graph=False, grad_variables=None)
Computes the sum of gradients of given tensors w.r.t. graph leaves.The graph is differentiated using the chain rule. If any of tensors are non-scalar (i.e. their data has more than one element) and require gradient, the function additionally requires specifying grad_tensors. It should be a sequence of matching length, that contains gradient of the differentiated function w.r.t. corresponding tensors (None is an acceptable value for all tensors that don't need gradient tensors). This function accumulates gradients in the leaves - you might need to zero them before calling it.
翻譯和解釋:
參數(shù)tensors如果是標(biāo)量,函數(shù)backward計算參數(shù)tensors對于給定圖葉子節(jié)點(diǎn)的梯度( graph leaves,即為設(shè)置requires_grad=True的變量)。
參數(shù)tensors如果不是標(biāo)量,需要另外指定參數(shù)grad_tensors,參數(shù)grad_tensors必須和參數(shù)tensors的長度相同。在這一種情況下,backward實(shí)際上實(shí)現(xiàn)的是代價函數(shù)(loss = torch.sum(tensors*grad_tensors); 注:torch中向量*向量實(shí)際上是點(diǎn)積,因此tensors和grad_tensors的維度必須一致 )關(guān)于葉子節(jié)點(diǎn)的梯度計算,而不是參數(shù)tensors對于給定圖葉子節(jié)點(diǎn)的梯度。如果指定參數(shù)grad_tensors=torch.ones((size(tensors))),顯而易見,代價函數(shù)關(guān)于葉子節(jié)點(diǎn)的梯度,也就等于參數(shù)tensors對于給定圖葉子節(jié)點(diǎn)的梯度。
每次backward之前,需要注意葉子梯度節(jié)點(diǎn)是否清零,如果沒有清零,第二次backward會累計上一次的梯度。
下面給出具體的例子:
import torch
x=torch.randn((3),dtype=torch.float32,requires_grad=True)
y = torch.randn((3),dtype=torch.float32,requires_grad=True)
z = torch.randn((3),dtype=torch.float32,requires_grad=True)
t = x + y
loss = t.dot(z) #求向量的內(nèi)積
在調(diào)用 backward 之前,可以先手動求一下導(dǎo)數(shù),應(yīng)該是:
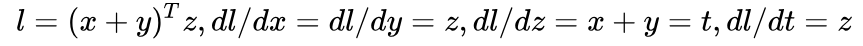
用代碼實(shí)現(xiàn)求導(dǎo):
loss.backward(retain_graph=True)
print(z,x.grad,y.grad) #預(yù)期打印出的結(jié)果都一樣
print(t,z.grad) #預(yù)期打印出的結(jié)果都一樣
print(t.grad) #在這個例子中,x,y,z就是葉子節(jié)點(diǎn),而t不是,t的導(dǎo)數(shù)在backward的過程中求出來回傳之后就會被釋放,因而預(yù)期結(jié)果是None
結(jié)果和預(yù)期一致:
tensor([-2.6752, 0.2306, -0.8356], requires_grad=True) tensor([-2.6752, 0.2306, -0.8356]) tensor([-2.6752, 0.2306, -0.8356])
tensor([-1.1916, -0.0156, 0.8952], grad_fn=AddBackward0>) tensor([-1.1916, -0.0156, 0.8952]) None
敲重點(diǎn):
注意到前面函數(shù)的解釋中,在參數(shù)tensors不是標(biāo)量的情況下,tensor.backward(grad_tensors)實(shí)現(xiàn)的是代價函數(shù)(torch.sum(tensors*grad_tensors))關(guān)于葉子節(jié)點(diǎn)的導(dǎo)數(shù)。
在上面例子中,loss = t.dot(z),因此用t.backward(z),實(shí)現(xiàn)的就是loss對于所有葉子結(jié)點(diǎn)的求導(dǎo),實(shí)際運(yùn)算結(jié)果和預(yù)期吻合。
t.backward(z,retain_graph=True)
print(z,x.grad,y.grad)
print(t,z.grad)
運(yùn)行結(jié)果如下:
tensor([-0.7830, 1.4468, 1.2440], requires_grad=True) tensor([-0.7830, 1.4468, 1.2440]) tensor([-0.7830, 1.4468, 1.2440])
tensor([-0.7145, -0.7598, 2.0756], grad_fn=AddBackward0>) None
上面的結(jié)果中,出現(xiàn)了一個問題,雖然loss關(guān)于x和y的導(dǎo)數(shù)正確,但是z不再是葉子節(jié)點(diǎn)了。
問題1:
當(dāng)使用t.backward(z,retain_graph=True)的時候, print(z.grad)結(jié)果是None,這意味著z不再是葉子節(jié)點(diǎn),這是為什么呢?
另外一個嘗試,loss = t.dot(z)=z.dot(t),但是如果用z.backward(t)替換t.backward(z,retain_graph=True),結(jié)果卻不同。
z.backward(t)
print(z,x.grad,y.grad)
print(t,z.grad)
運(yùn)行結(jié)果:
tensor([-1.0716, -1.3643, -0.0016], requires_grad=True) None None
tensor([-0.7324, 0.9763, -0.4036], grad_fn=AddBackward0>) tensor([-0.7324, 0.9763, -0.4036])
問題2:
上面的結(jié)果中可以看到,使用z.backward(t),x和y都不再是葉子節(jié)點(diǎn)了,z仍然是葉子節(jié)點(diǎn),且得到的loss相對于z的導(dǎo)數(shù)正確。
上述仿真出現(xiàn)的兩個問題,我還不能解釋,希望和大家交流。
問題1:
當(dāng)使用t.backward(z,retain_graph=True)的時候, print(z.grad)結(jié)果是None,這意味著z不再是葉子節(jié)點(diǎn),這是為什么呢?
問題2:
上面的結(jié)果中可以看到,使用z.backward(t),x和y都不再是葉子節(jié)點(diǎn)了,z仍然是葉子節(jié)點(diǎn),且得到的loss相對于z的導(dǎo)數(shù)正確。
另外強(qiáng)調(diào)一下,每次backward之前,需要注意葉子梯度節(jié)點(diǎn)是否清零,如果沒有清零,第二次backward會累計上一次的梯度。
簡單的代碼可以看出:
#測試1,:對比上兩次單獨(dú)執(zhí)行backward,此處連續(xù)執(zhí)行兩次backward
t.backward(z,retain_graph=True)
print(z,x.grad,y.grad)
print(t,z.grad)
z.backward(t)
print(z,x.grad,y.grad)
print(t,z.grad)
# 結(jié)果x.grad,y.grad本應(yīng)該是None,因?yàn)楸A袅说谝淮蝏ackward的結(jié)果而打印出上一次梯度的結(jié)果
tensor([-0.5590, -1.4094, -1.5367], requires_grad=True) tensor([-0.5590, -1.4094, -1.5367]) tensor([-0.5590, -1.4094, -1.5367])tensor([-1.7914, 0.8761, -0.3462], grad_fn=AddBackward0>) Nonetensor([-0.5590, -1.4094, -1.5367], requires_grad=True) tensor([-0.5590, -1.4094, -1.5367]) tensor([-0.5590, -1.4094, -1.5367])tensor([-1.7914, 0.8761, -0.3462], grad_fn=AddBackward0>) tensor([-1.7914, 0.8761, -0.3462])
#測試2,:連續(xù)執(zhí)行兩次backward,并且清零,可以驗(yàn)證第二次backward沒有計算x和y的梯度
t.backward(z,retain_graph=True)
print(z,x.grad,y.grad)
print(t,z.grad)
x.grad.data.zero_()
y.grad.data.zero_()
z.backward(t)
print(z,x.grad,y.grad)
print(t,z.grad)
tensor([ 0.8671, 0.6503, -1.6643], requires_grad=True) tensor([ 0.8671, 0.6503, -1.6643]) tensor([ 0.8671, 0.6503, -1.6643])tensor([1.6231e+00, 1.3842e+00, 4.6492e-06], grad_fn=AddBackward0>) Nonetensor([ 0.8671, 0.6503, -1.6643], requires_grad=True) tensor([0., 0., 0.]) tensor([0., 0., 0.])tensor([1.6231e+00, 1.3842e+00, 4.6492e-06], grad_fn=AddBackward0>) tensor([1.6231e+00, 1.3842e+00, 4.6492e-06])
以上為個人經(jīng)驗(yàn),希望能給大家一個參考,也希望大家多多支持腳本之家。
您可能感興趣的文章:- PyTorch梯度裁剪避免訓(xùn)練loss nan的操作
- Pytorch BCELoss和BCEWithLogitsLoss的使用
- Pytorch訓(xùn)練網(wǎng)絡(luò)過程中l(wèi)oss突然變?yōu)?的解決方案
- pytorch MSELoss計算平均的實(shí)現(xiàn)方法
- pytorch loss反向傳播出錯的解決方案
- Pytorch損失函數(shù)nn.NLLLoss2d()用法說明
- pytorch使用tensorboardX進(jìn)行l(wèi)oss可視化實(shí)例
