今天,跟大家分享一下我做小項目時想出來的文本字符處理的方法,希望能對大家有所幫助。
完整代碼:
strings = "我,是‘C|S;D|N!的:程【序】員#M,r.;P'a#n?_學?狂"#將字符串設置好
def String_Process(string):#定義一個字符處理函數,設置參數string,是有待處理的字符串。
print("python使我快樂!!")
print("未處理的字符串:",string)
varchar = '‘'“”:#,!【】,#|?|,;;?:"'#人為設定字符集合
ls = []#定義一個列表用于存儲拆散的字符
for s in string:
ls.append(s)#將字符串拆散存進列表中
for element in ls:
if element in varchar:#如果在字符集合內發現,則從列表中刪除
ls.remove(element)
String = ''#定義字符串
for l in ls:#將列表中拆散的元素組合回去。
String = String+l
print("處理后的字符串:",String)#得到處理結果
String_Process(string=strings)#調用函數,傳入實參給形參。
運行結果,如下圖:
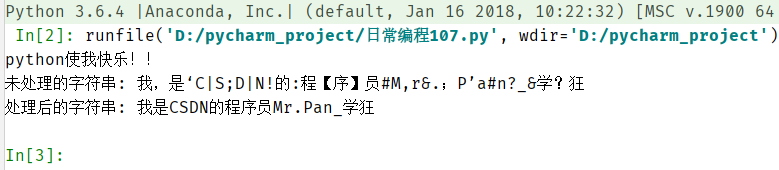
對于處理文本字符的思想在代碼中已經說明,關于代碼的解釋在注釋中也寫出了。我們把它通過函數進行封裝,當我們需要處理文本字符的時候,通過調用函數就可以實現文本字符處理了。當然,調用函數處理字符時需要得到string返回值以及注釋掉print,因為我們如果是在循環中調用,沒必要全部打印一遍,影響視覺對文本的分析。即修改代碼如下圖:
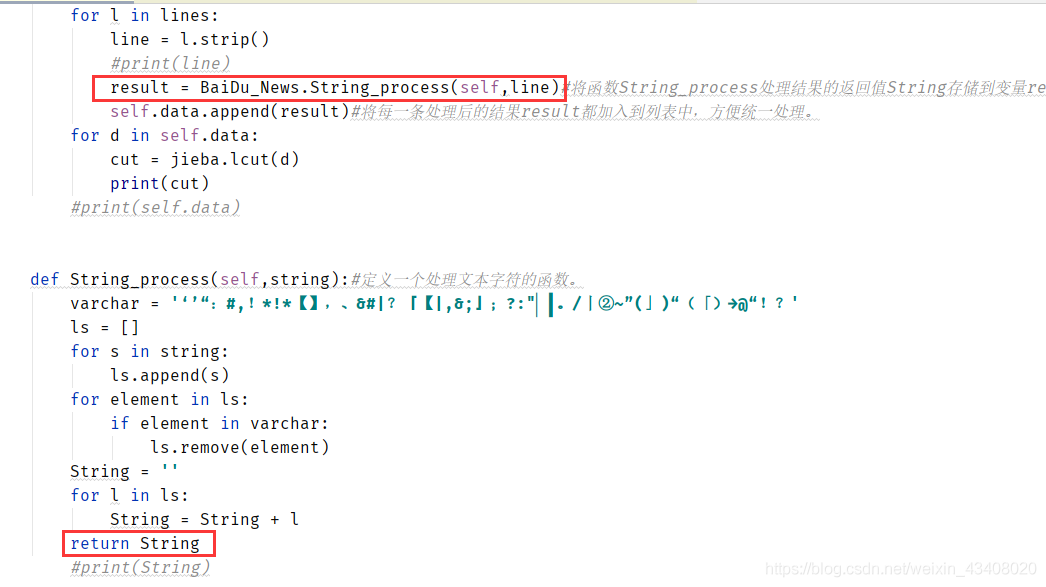
對于上面的文本處理代碼,我又做了一次更新,可以增加新的字符或者是字符串來更新字符集合,更加方便處理文本中的字符。
改進后的代碼,如下圖:
strings = "我,是‘C|S;D|N!的:程【序】員#M,r.;②P'「(a#n」?_學?狂..."#將字符串設置好
def Process(string):#定義一個字符處理函數,設置參數string,是有待處理的字符串。
print("python使我快樂!!")
print("未處理的字符串:",string)
varchar = '‘'“”:#,!【】,#|?|,;;?:"'#人為設定字符集合
var_ls = []
for var in varchar:
var_ls.append(var)
print("這是當前的字符集合:",var_ls)
while True:
want = str(input("是否需要增加新的字符/字符集合?(yes or no)"))
if want == 'yes':
add_varchar = str(input("請輸入需要增加的新字符/字符集合:"))
for var in add_varchar:
var_ls.append(var)
print("更新后的字符集合:",var_ls)
elif want == 'no':
break
else:
print("輸入有誤!!請重試!!")
continue
ls = []#定義一個列表用于存儲拆散的字符
for s in string:
ls.append(s)#將字符串拆散存進列表中
for element in ls[:]:
if element in var_ls:#如果在字符集合內發現,則從列表中刪除
ls.remove(element)
elif element not in var_ls:
continue
String = ''#定義字符串
for l in ls:#將列表中拆散的元素組合回去。
String = String+l
print("處理后的字符串:",String)#得到處理結果
Process(string=strings)#調用函數,傳入實參給形參。
代碼的解釋在注釋中寫了,大家如果對代碼不理解可以和我私信探討。
運行結果,如下圖:

總結
到此這篇關于python中文本字符處理的文章就介紹到這了,更多相關python文本字符處理內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python統計文本字符串里單詞出現頻率的方法
- Python實現簡單文本字符串處理的方法
- Python處理文本文件中控制字符的方法
- 使用Python提取文本中含有特定字符串的方法示例
- 解決Python對齊文本字符串問題
- Python cookbook(字符串與文本)針對任意多的分隔符拆分字符串操作示例
- Python cookbook(字符串與文本)在字符串的開頭或結尾處進行文本匹配操作
- Python字符串及文本模式方法詳解
