目錄
- 一、實(shí)現(xiàn)登錄賬號(hào)
- 二、實(shí)現(xiàn)ts碎片視頻下載,并轉(zhuǎn)換為mp4格式
- 三、總結(jié)
目標(biāo):爬取自己賬號(hào)中購買的課程視頻。
一、實(shí)現(xiàn)登錄賬號(hào)
這里采用的是手動(dòng)輸入驗(yàn)證碼的方式,有能力的盆友也可以通過圖像識(shí)別的方式自動(dòng)填寫驗(yàn)證碼。登錄后,采用session保持登錄。
1.獲取驗(yàn)證碼地址
第一步:首先查看驗(yàn)證碼對(duì)應(yīng)的代碼,可以從圖中看到驗(yàn)證碼圖片的地址是:https://per.enetedu.com/Common/CreateImage?tmep_seq=1613623257608
顏色標(biāo)紅的部分tmep_seq=1613623257608,是為了解決瀏覽器緩存問題加的時(shí)間戳,因此真正的驗(yàn)證碼圖片地址是:https://per.enetedu.com/Common/CreateImage

第二步:找出登錄時(shí)提交的表單內(nèi)容和POST地址。
(1) 不填寫用戶名密碼和驗(yàn)證碼,直接點(diǎn)擊登錄,使用Chrome瀏覽器的Network檢查,找到POST地址:https://per.enetedu.com/AdminIndex/LoginDo
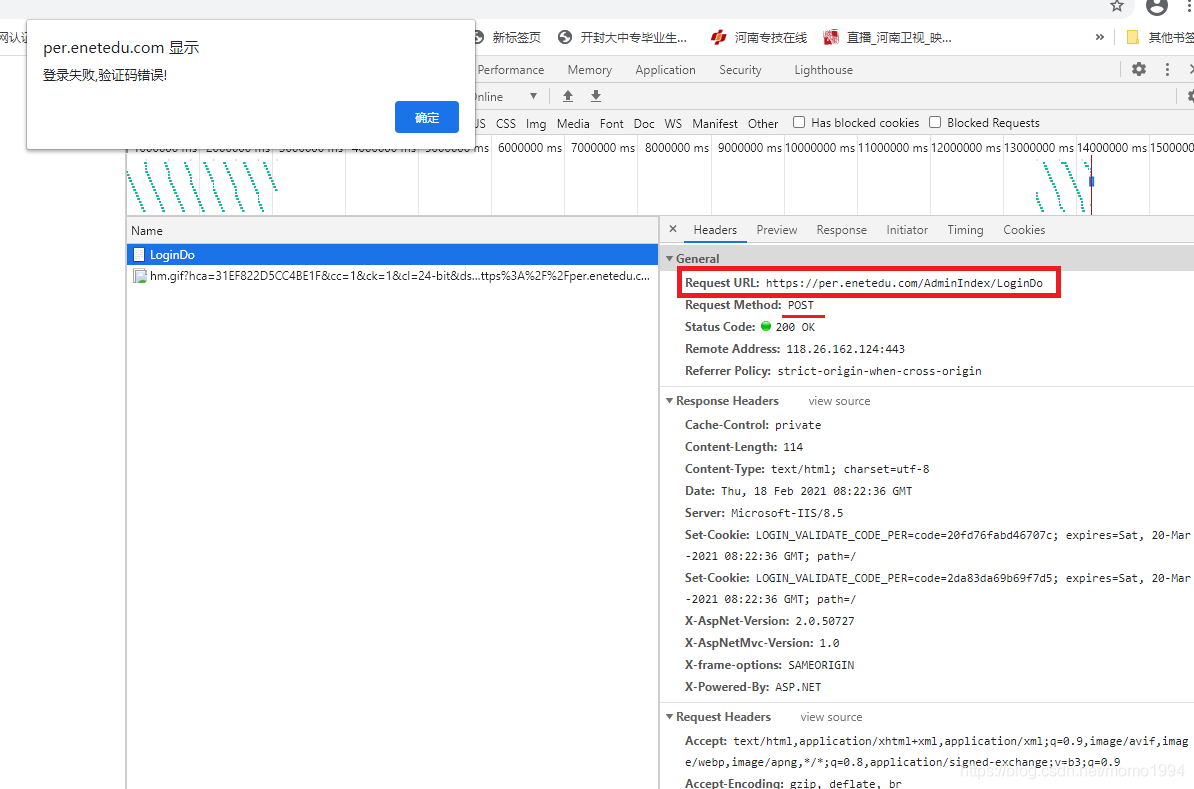
(2) 繼續(xù)向下看,找到提交的表單 Form Data。

因此帶有驗(yàn)證碼的登錄代碼如下:
import requests
from PIL import Image
#用戶名-密碼-驗(yàn)證碼方式,登錄
CaptchaUrl = "https://per.enetedu.com/Common/CreateImage" #獲取驗(yàn)證碼地址
PostUrl = "https://per.enetedu.com/AdminIndex/LoginDo" #post登錄信息地址
client = requests.Session()
username = '替換為自己的用戶名'
password = '替換為自己的密碼'
qr_code = client.get(CaptchaUrl)
open('login.jpg', 'wb').write(qr_code.content) #將驗(yàn)證碼圖片保存至本地
img = Image.open('login.jpg')
img.show() #打開圖片
code = input("請(qǐng)輸入驗(yàn)證碼: \n") #輸入驗(yàn)證碼
postData = { #構(gòu)造POST表單
'email': username,
'pwd': password,
'validateCode': code,
'x': '22',
'y': '19'
}
result = client.post(PostUrl,postData) #向PostUrl提交表單
二、實(shí)現(xiàn)ts碎片視頻下載,并轉(zhuǎn)換為mp4格式
1.分析視頻下載地址
登錄成功后,檢查視頻播放div對(duì)應(yīng)的代碼,企圖找到視頻地址直接保存至本地。結(jié)果,如下圖所示,整個(gè)視頻是被分割成一段一段的.ts文件,分段加載到頁面中播放。GET每段視頻的地址為右側(cè)紅框圈起來的部分。
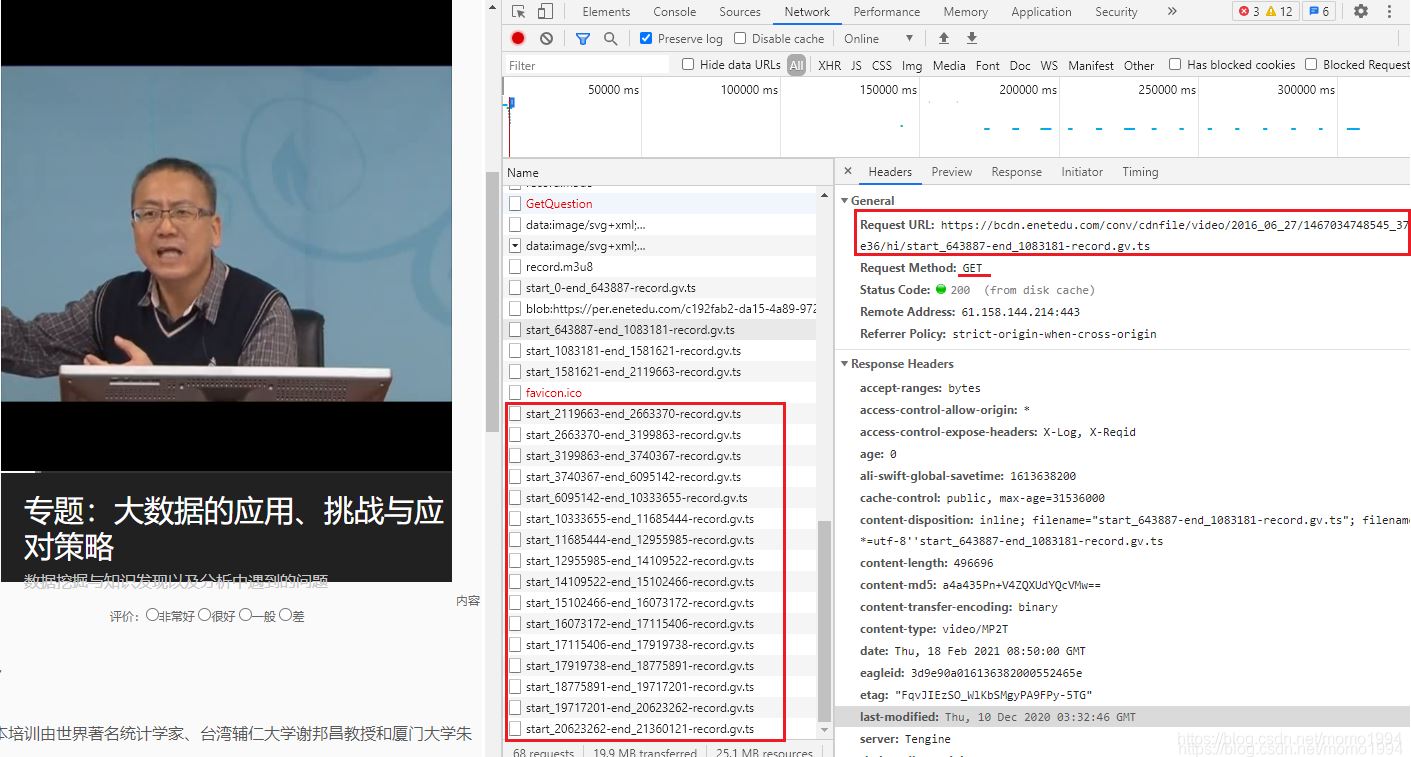
百度后才知道,整個(gè)視頻如何分段是由一個(gè)m3u8文件來決定的。m3u8文件中的內(nèi)容如下所示,記錄了每段視頻start和end的編號(hào)。
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-ALLOW-CACHE:YES
#EXT-X-TARGETDURATION:10
#EXTINF:10.000000,
start_0-end_765064-record.gv.ts
#EXTINF:10.000000,
start_765064-end_1769567-record.gv.ts
#EXTINF:10.000000,
start_1769567-end_2600798-record.gv.ts
#EXTINF:10.000000,
start_2600798-end_3593502-record.gv.ts
#EXTINF:10.000000,
start_3593502-end_4500784-record.gv.ts
#EXTINF:10.000000,
start_4500784-end_5399861-record.gv.ts
#EXTINF:10.000000,
start_5399861-end_6288622-record.gv.ts
#EXTINF:10.000000,
start_6288622-end_7044459-record.gv.ts
#EXTINF:10.000000,
start_7044459-end_7878487-record.gv.ts
#EXTINF:10.000000,
start_7878487-end_8811793-record.gv.ts
#EXTINF:10.000000,
因此,下載視頻的關(guān)鍵是獲取m3u8文件,通過這個(gè)視頻的m3u8文件來分段下載視頻。
我是人工找出m3u8的下載地址,暫時(shí)還沒研究出來怎么通過視頻地址自動(dòng)解析出m3u8地址。找的方法很簡單,還是在Chrome的Network控制臺(tái)找。打開Network控制臺(tái),刷新頁面,就可以找到如圖所示的m3u8文件。查看m3u8文件的相關(guān)信息,可以看到紅框圈起來的地址就是這個(gè)視頻的m3u8下載地址。
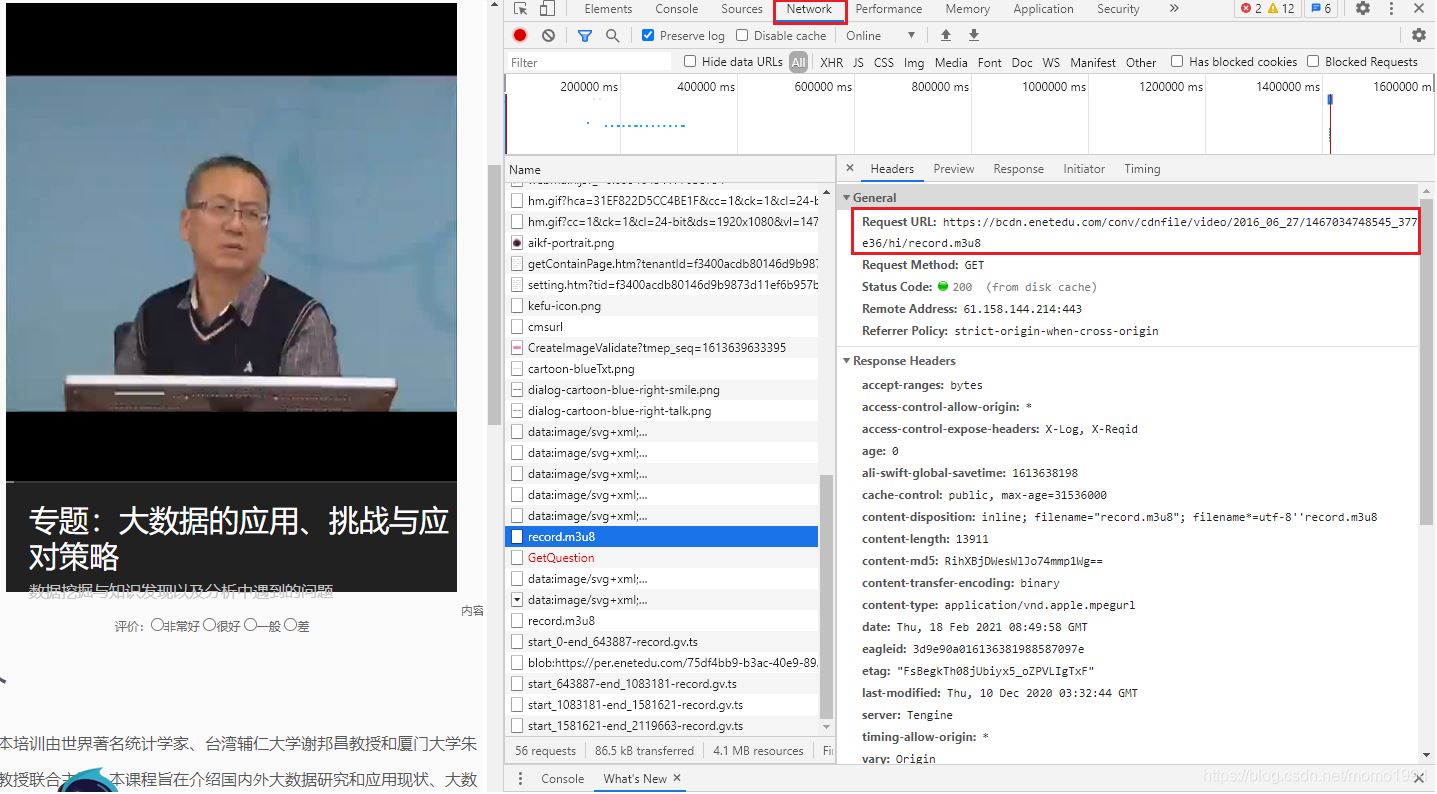
對(duì)比兩個(gè)地址,可以發(fā)現(xiàn)文件名前的地址相同,視頻下載地址即為"標(biāo)紅地址"+"m3u8文件中列出的視頻段文件名":
https://bcdn.enetedu.com/conv/cdnfile/video/2016_06_27/1467034852884_f5821b/hi/record.m3u8
https://bcdn.enetedu.com/conv/cdnfile/video/2016_06_27/1467034852884_f5821b/hi/start_643887-end_1083181-record.gv.ts
因此可以將這部分地址設(shè)為:urlroot = https://bcdn.enetedu.com/conv/cdnfile/video/2016_06_27/1467034852884_f5821b/hi
為了方便下載其他視頻時(shí)動(dòng)態(tài)修改,改為動(dòng)態(tài)截取:
url = input("請(qǐng)輸入m3u8文件地址:")
urlRoot=self.url[0:url.rindex('/')]
2.批量下載ts視頻片段
這一步使用上一步拼接的地址循環(huán)下載ts視頻即可。下載時(shí),使用登錄時(shí)創(chuàng)建的session下載。
session是會(huì)話的意思,它可以讓服務(wù)器“認(rèn)得”客戶端。簡單理解就是,把每一個(gè)客戶端和服務(wù)器的互動(dòng)當(dāng)作一個(gè)“會(huì)話”。既然在同一個(gè)“會(huì)話”里,服務(wù)器自然就能知道這個(gè)客戶端是否登錄過。代碼如下:
client = requests.Session()
client.post(PostUrl,postData) #登錄
resp = client.get(download_path) #下載
碎片拼接的方法:下載完第一個(gè)ts片段后,直接在該文件后面繼續(xù)寫第二個(gè)ts片段,以此類推。而不是新建一個(gè)文件寫入。與驗(yàn)證碼登錄結(jié)合起來,完整代碼如下:
import requests
from PIL import Image
import sys
import m3u8
import time
import os
#用戶名-密碼-驗(yàn)證碼方式,登錄
CaptchaUrl = "https://per.enetedu.com/Common/CreateImage" #獲取驗(yàn)證碼地址
PostUrl = "https://per.enetedu.com/AdminIndex/LoginDo" #post登錄信息地址
client = requests.Session()
username = '526257482@qq.com'
password = 'dashuju_9514'
qr_code = client.get(CaptchaUrl)
open('login.jpg', 'wb').write(qr_code.content) #將驗(yàn)證碼圖片保存至本地
img = Image.open('login.jpg')
img.show() #打開圖片
code = input("請(qǐng)輸入驗(yàn)證碼: \n") #輸入驗(yàn)證碼
postData = { #構(gòu)造POST表單
'email': username,
'pwd': password,
'validateCode': code,
'x': '56',
'y': '19'
}
result = client.post(PostUrl,postData) #向PostUrl提交表單
#循環(huán)下載ts視頻
class VideoCrawler():
def __init__(self,url):
super(VideoCrawler, self).__init__()
self.url=url
self.final_path=r"D:\Download\Film"
#下載并解析m3u8文件
def get_url_from_m3u8(self,readAdr):
print("正在解析真實(shí)下載地址...")
with open('temp.m3u8','wb') as file:
file.write(requests.get(readAdr).content)
m3u8Obj=m3u8.load('temp.m3u8')
print("解析完成")
return m3u8Obj.segments
def run(self):
print("Start!")
start_time=time.time()
realAdr = self.url #m3u8下載地址
urlList=self.get_url_from_m3u8(realAdr) #解析m3u8文件,獲取下載地址
urlRoot=self.url[0:self.url.rindex('/')]
i=1
outputfile=open(os.path.join(self.final_path,'%s.ts'%self.fileName),'wb')#初始創(chuàng)建一個(gè)ts文件,之后每次循環(huán)將ts片段的文件流寫入此文件中從而不需要在去合并ts文件
for url in urlList:
try:
download_path = "%s/%s" % (urlRoot, url.uri) #拼接地址
resp = client.get(download_path) #使用拼接地址去爬取數(shù)據(jù)
progess = i/len(urlList)#記錄當(dāng)前的爬取進(jìn)度
outputfile.write(resp.content) #將爬取到ts片段的文件流寫入剛開始創(chuàng)建的ts文件中
sys.stdout.write('\r正在下載:{},進(jìn)度:{:.2%}'.format(self.fileName,progess))#通過百分比顯示下載進(jìn)度
sys.stdout.flush()#通過此方法將上一行代碼刷新,控制臺(tái)只保留一行
except Exception as e:
print("\n出現(xiàn)錯(cuò)誤:%s",e.args)
continue#出現(xiàn)錯(cuò)誤跳出當(dāng)前循環(huán),繼續(xù)下次循環(huán)
i+=1
outputfile.close()
print("下載完成!總共耗時(shí)%d s"%(time.time()-start_time))
print("開始轉(zhuǎn)換視頻格式!")
success = os.system(r'copy /b D:\Download\Film\{0}.ts D:\Download\Film\{0}.mp4'.format(self.fileName)) #ts轉(zhuǎn)成mp4格式
if (not success):
print("格式轉(zhuǎn)換成功!")
os.remove(self.final_path+'\\'+self.fileName+".ts") #刪除ts和m3u8臨時(shí)文件
os.remove("temp.m3u8")
if __name__=='__main__':
m3u8_addr = input("輸入m3u8文件下載地址:\n")
crawler=VideoCrawler(m3u8_addr)
crawler.fileName = input("輸入文件名:\n")
crawler.run()
quitClick=input("請(qǐng)按Enter鍵確認(rèn)退出!")
三、總結(jié)
代碼可以實(shí)現(xiàn)分段加載視頻的爬取功能,其中還有很多細(xì)節(jié)待完善如:
- 驗(yàn)證碼可以通過圖像識(shí)別的方法自動(dòng)識(shí)別。
- 通過解析視頻地址獲取m3u8文件,非計(jì)算機(jī)專業(yè)人使用起來更加友好。
- 例子中的網(wǎng)站沒有對(duì)m3u8文件進(jìn)行加密,涉及到加密的m3u8還需要加一步解密的過程。
到此這篇關(guān)于Python爬蟲爬取ts碎片視頻+驗(yàn)證碼登錄功能的文章就介紹到這了,更多相關(guān)Python爬蟲爬取視頻內(nèi)容請(qǐng)搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- 用Python爬蟲破解滑動(dòng)驗(yàn)證碼的案例解析
- python網(wǎng)絡(luò)爬蟲實(shí)現(xiàn)發(fā)送短信驗(yàn)證碼的方法
- python爬蟲如何解決圖片驗(yàn)證碼
- Python爬蟲模擬登陸嗶哩嗶哩(bilibili)并突破點(diǎn)選驗(yàn)證碼功能
- Python3爬蟲里關(guān)于識(shí)別微博宮格驗(yàn)證碼的知識(shí)點(diǎn)詳解
- Python3爬蟲關(guān)于識(shí)別點(diǎn)觸點(diǎn)選驗(yàn)證碼的實(shí)例講解
- Python3爬蟲關(guān)于識(shí)別檢驗(yàn)滑動(dòng)驗(yàn)證碼的實(shí)例
- Python3爬蟲中識(shí)別圖形驗(yàn)證碼的實(shí)例講解
- Python3網(wǎng)絡(luò)爬蟲開發(fā)實(shí)戰(zhàn)之極驗(yàn)滑動(dòng)驗(yàn)證碼的識(shí)別
- python爬蟲解決驗(yàn)證碼的思路及示例
- Python爬蟲實(shí)現(xiàn)驗(yàn)證碼登錄代碼實(shí)例
- python爬蟲之驗(yàn)證碼篇3-滑動(dòng)驗(yàn)證碼識(shí)別技術(shù)
- python爬蟲之自動(dòng)登錄與驗(yàn)證碼識(shí)別
- Python爬蟲爬驗(yàn)證碼實(shí)現(xiàn)功能詳解
- Python爬蟲模擬登錄帶驗(yàn)證碼網(wǎng)站
- 爬蟲Python驗(yàn)證碼識(shí)別入門
