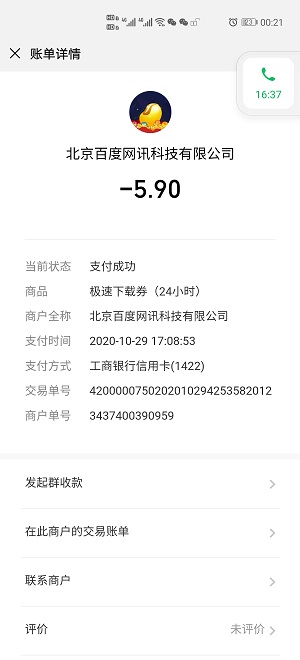
有一定數量類似如下截圖所示的賬單,利用 Python 批量識別電子賬單數據,并將數據保存到Excel。
百度智能云接口
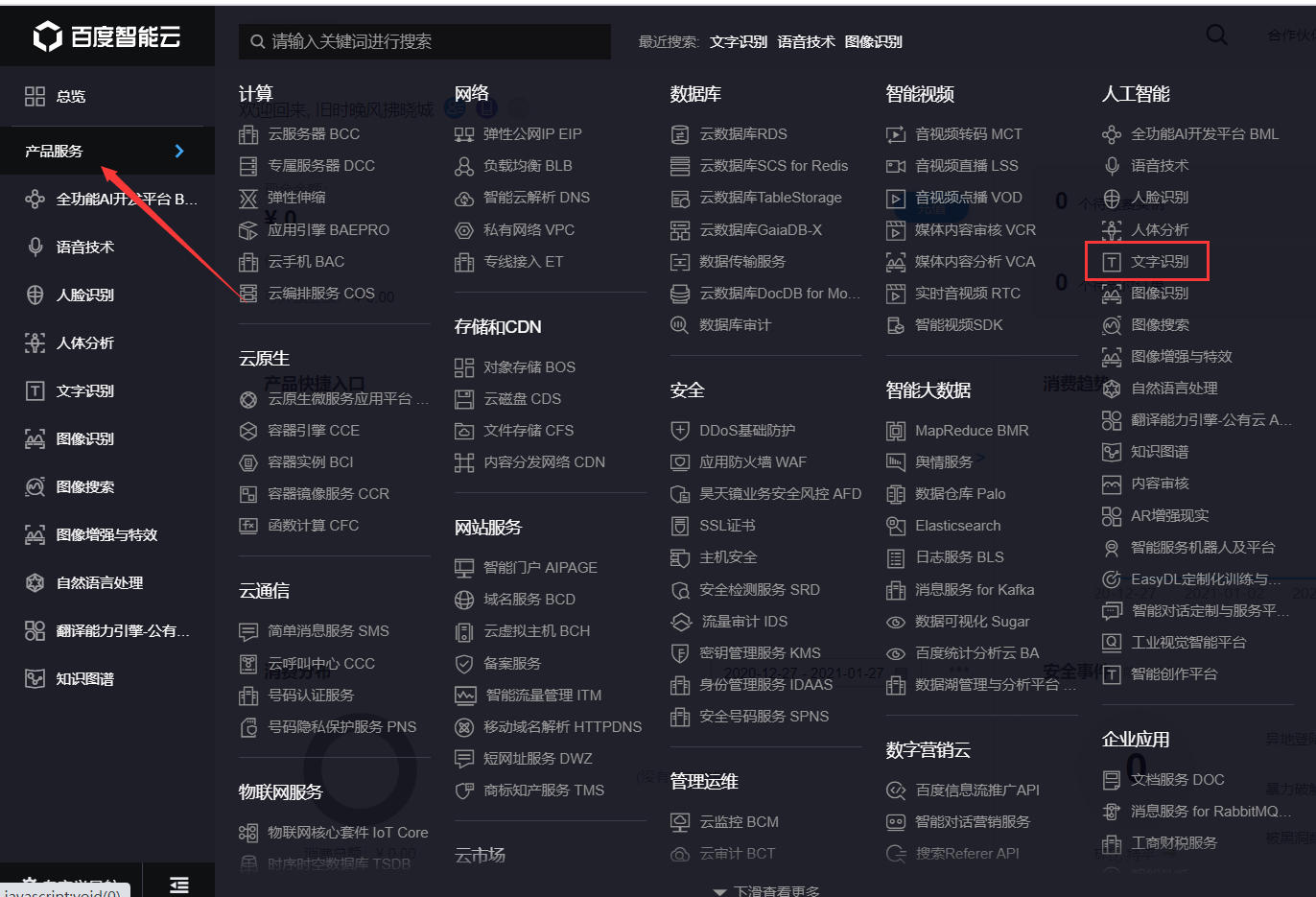
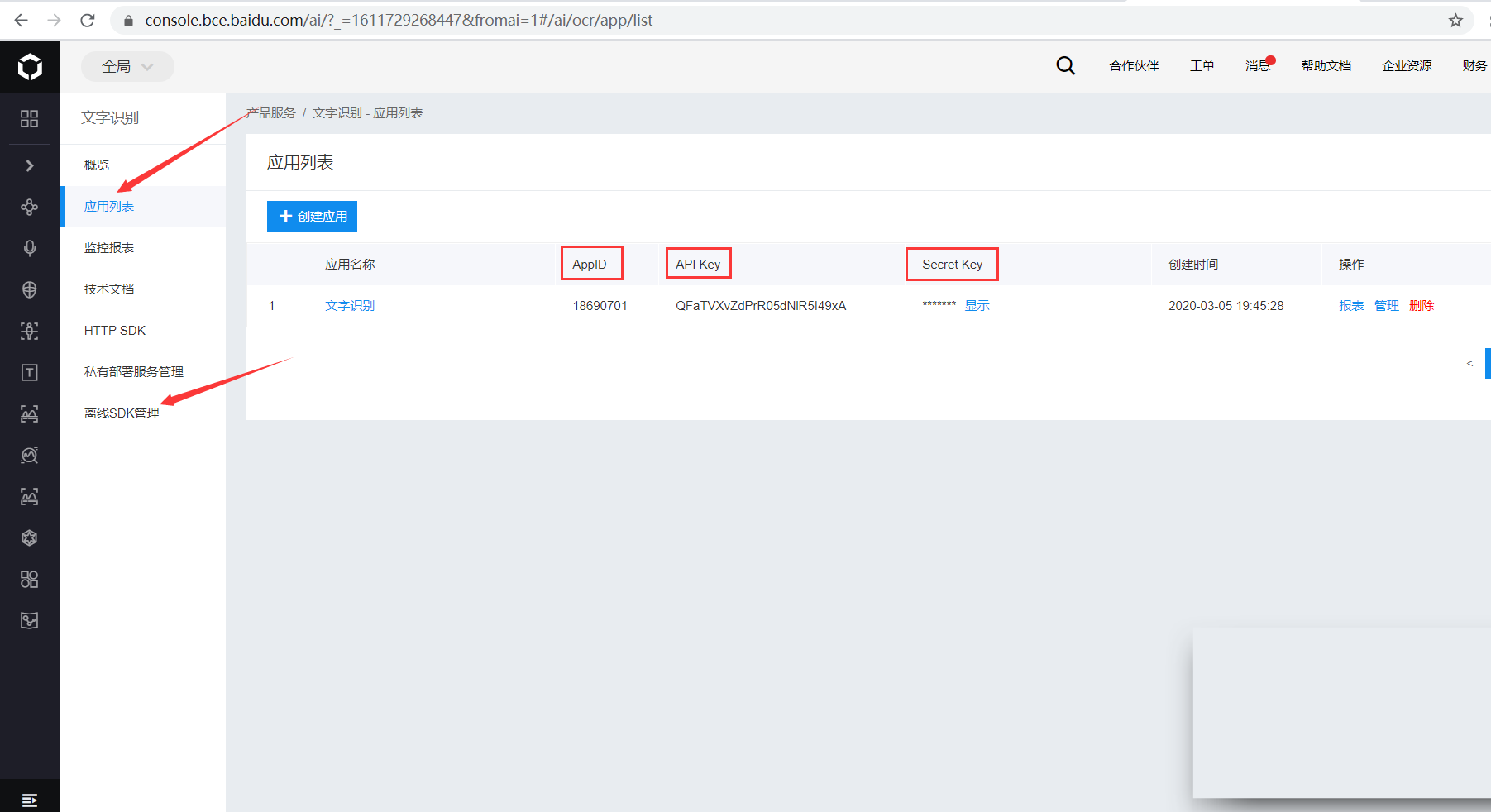
打開https://cloud.baidu.com/,如未注冊請先注冊,然后登錄點擊管理控制臺,點擊左側產品服務→人工智能→文字識別,點擊創建應用,輸入應用名稱如Baidu_OCR,選擇用途如學習辦公,最后進行簡單應用描述,即可點擊立即創建。會出現應用列表,包括AppID、API Key、Secret Key等信息,這些稍后會用到。
首先需要安裝百度的接口,命令行輸入如下:
pip install baidu-aip -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
查看 Python 的 SDK 文檔:
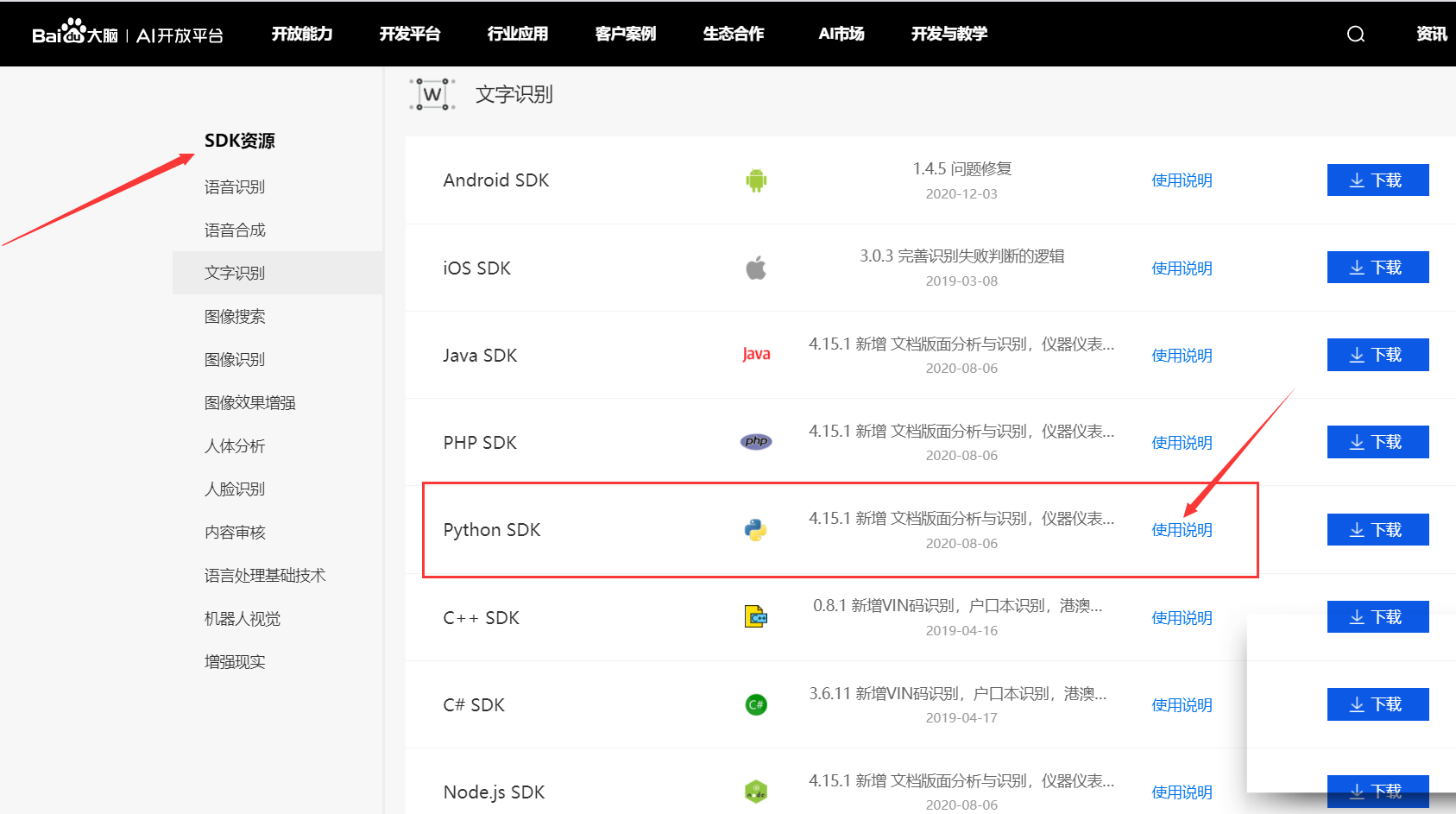
AipOcr是 OCR 的 Python SDK 客戶端,為使用 OCR 的開發人員提供了一系列的交互方法。參考如下代碼新建一個AipOcr:
from aip import AipOcr """ 你的 APPID AK SK """ APP_ID = '你的 App ID' API_KEY = '你的 Api Key' SECRET_KEY = '你的 Secret Key' client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
用戶向服務請求識別某張圖中的所有文字
""" 讀取圖片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('example.jpg')
""" 調用通用文字識別, 圖片參數為本地圖片 """
client.basicGeneral(image)
""" 調用通用文字識別(高精度版) 圖片參數為本地圖片 """
client.basicAccurate(image)
識別出如下圖片中的文字,示例如下:

from aip import AipOcr
# """ 改成你的 百度云服務的 ID AK SK """
APP_ID = '18690701'
API_KEY = 'QFaTVXvZdPrR05dNlR5I49xA'
SECRET_KEY = '*******************************'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('example.jpg')
# 調用通用文字識別, 圖片參數為本地圖片
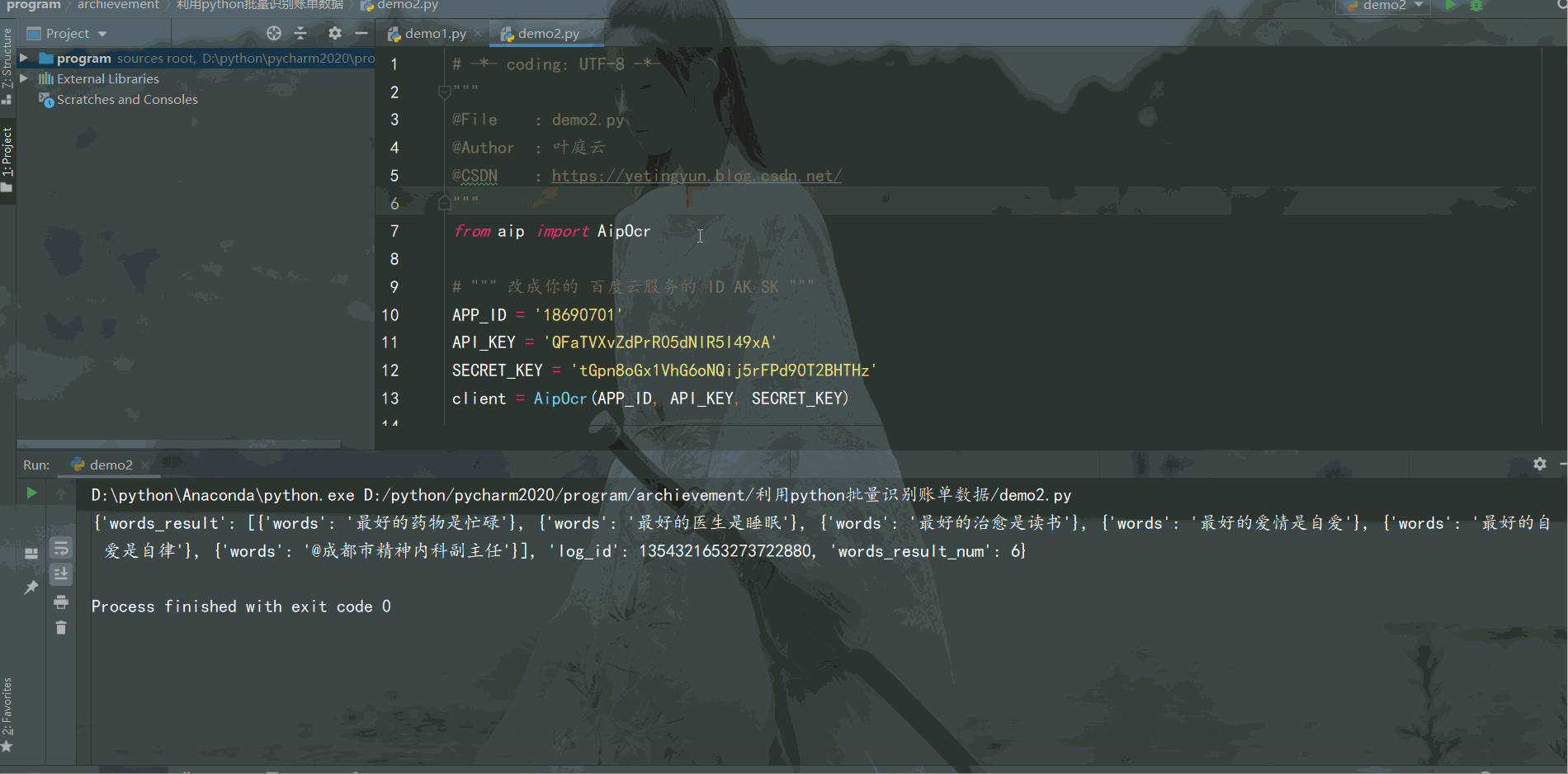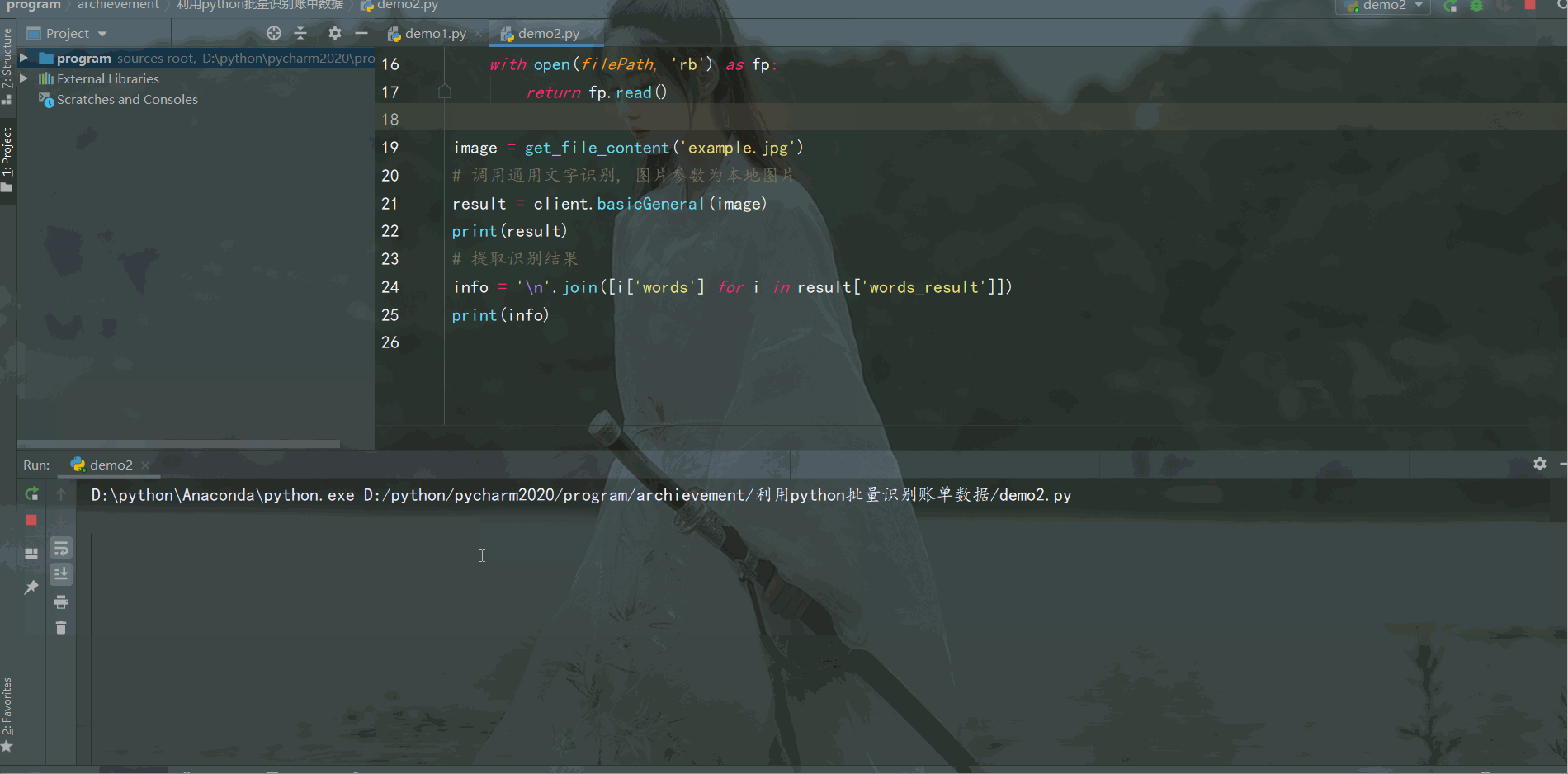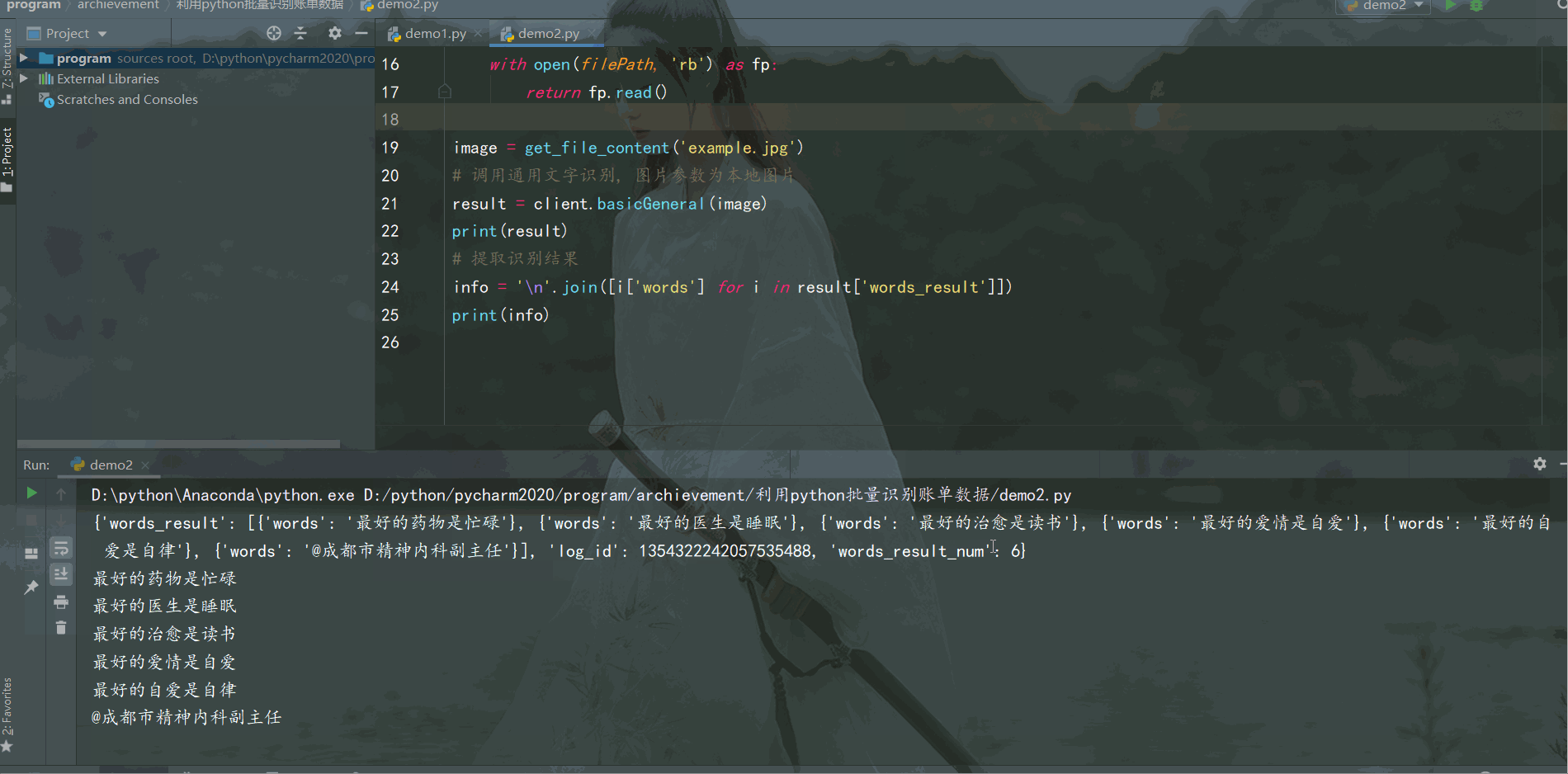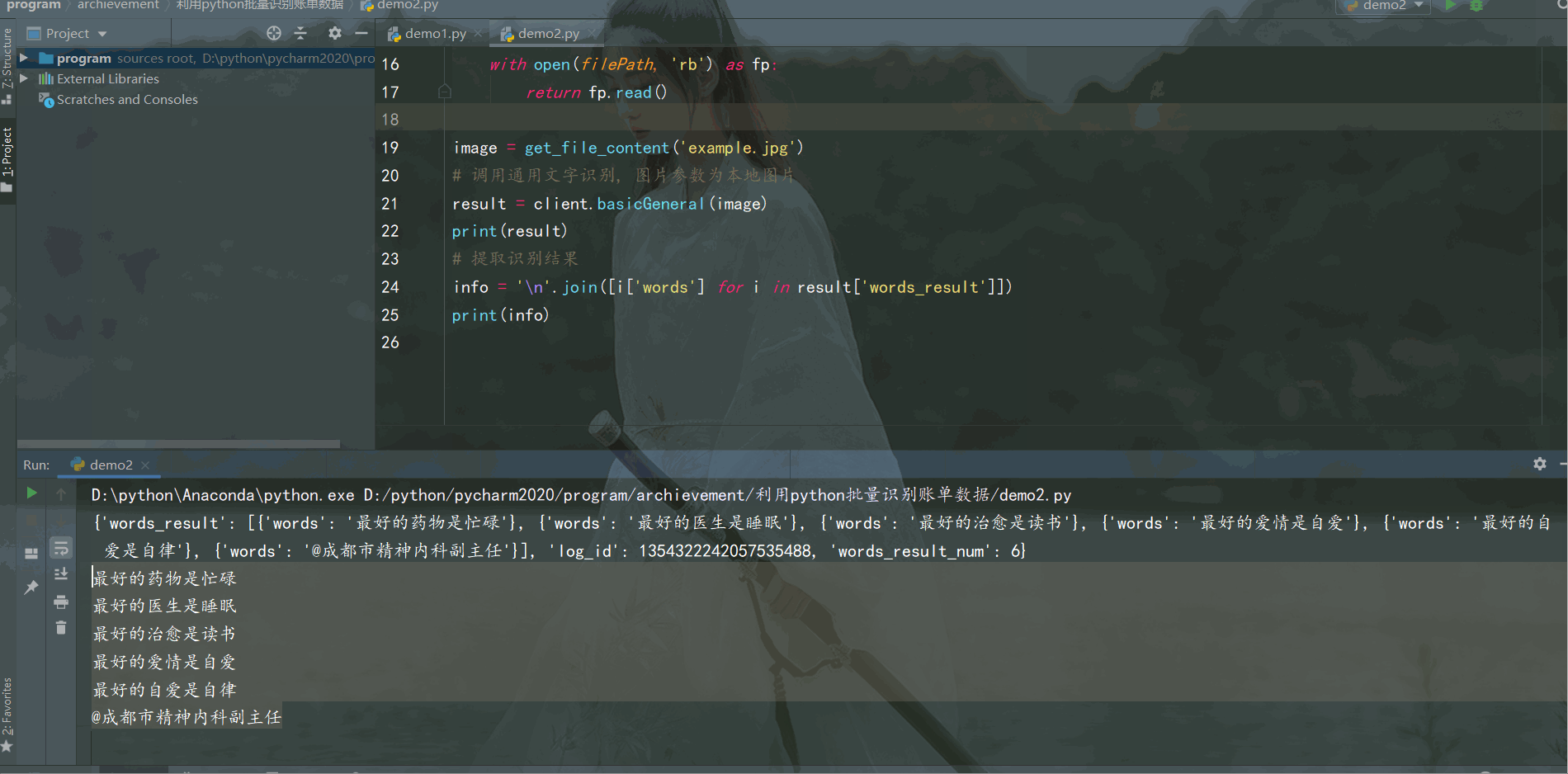
result = client.basicGeneral(image)
print(result)
# 提取識別結果
info = '\n'.join([i['words'] for i in result['words_result']])
print(info)
結果如下:
獲取所有待識別的電子賬單圖像
from pathlib import Path
# 換成你放圖片的路徑
p = Path(r'D:\test\test_img')
# 得到所有文件夾下 .jpg 圖片
file = p.glob('**/*.jpg')
for img_file in file:
print(type(img_file)) # class 'pathlib.WindowsPath'> 轉成str
img_file = str(img_file)
print(img_file)
為了增加識別準確率,將賬單上要提取的數據區域分割出來,再調用Baidu aip識別。
from pathlib import Path
import cv2 as cv
from aip import AipOcr
from time import sleep
APP_ID = '18690701'
API_KEY = 'QFaTVXvZdPrR05dNlR5I49xA'
SECRET_KEY = '**********************************'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
""" 讀取圖片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
def identity(num):
result_list = []
for i in range(num):
image = get_file_content('img{}.jpg'.format(i))
""" 調用通用文字識別, 圖片參數為本地圖片 """
result = client.basicGeneral(image)
print(result)
sleep(2)
# 識別結果
info = ''.join([i['words'] for i in result['words_result']])
result_list.append(info)
print(result_list)
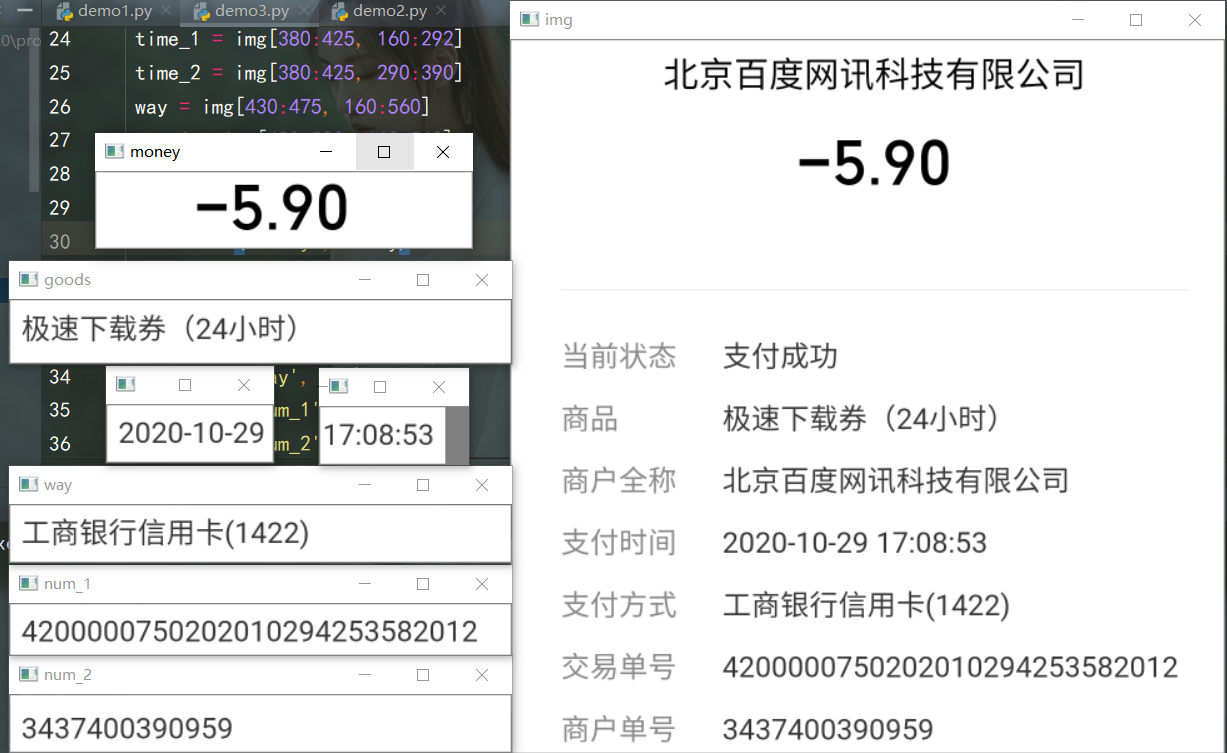
src = cv.imread(r'D:\test\test_img\001.jpg')
src = cv.resize(src, None, fx=0.5, fy=0.5)
# print(src.shape)
img = src[280:850, 10:580] # 截取圖片 高 寬
money = img[70:130, 150:450] # 支出 收入金額
goods = img[280:330, 160:560] # 商品
time_1 = img[380:425, 160:292] # 支付時間 年月日
time_2 = img[380:425, 160:390] # 支付時間 完整
way = img[430:475, 160:560] # 支付方式
num_1 = img[480:520, 160:560] # 交易單號
num_2 = img[525:570, 160:560] # 商戶單號
img_list = [money, goods, time_1, time_2, way, num_1, num_2]
for index_, item in enumerate(img_list):
cv.imwrite(f'img{index_}.jpg', item)
identity(len(img_list))
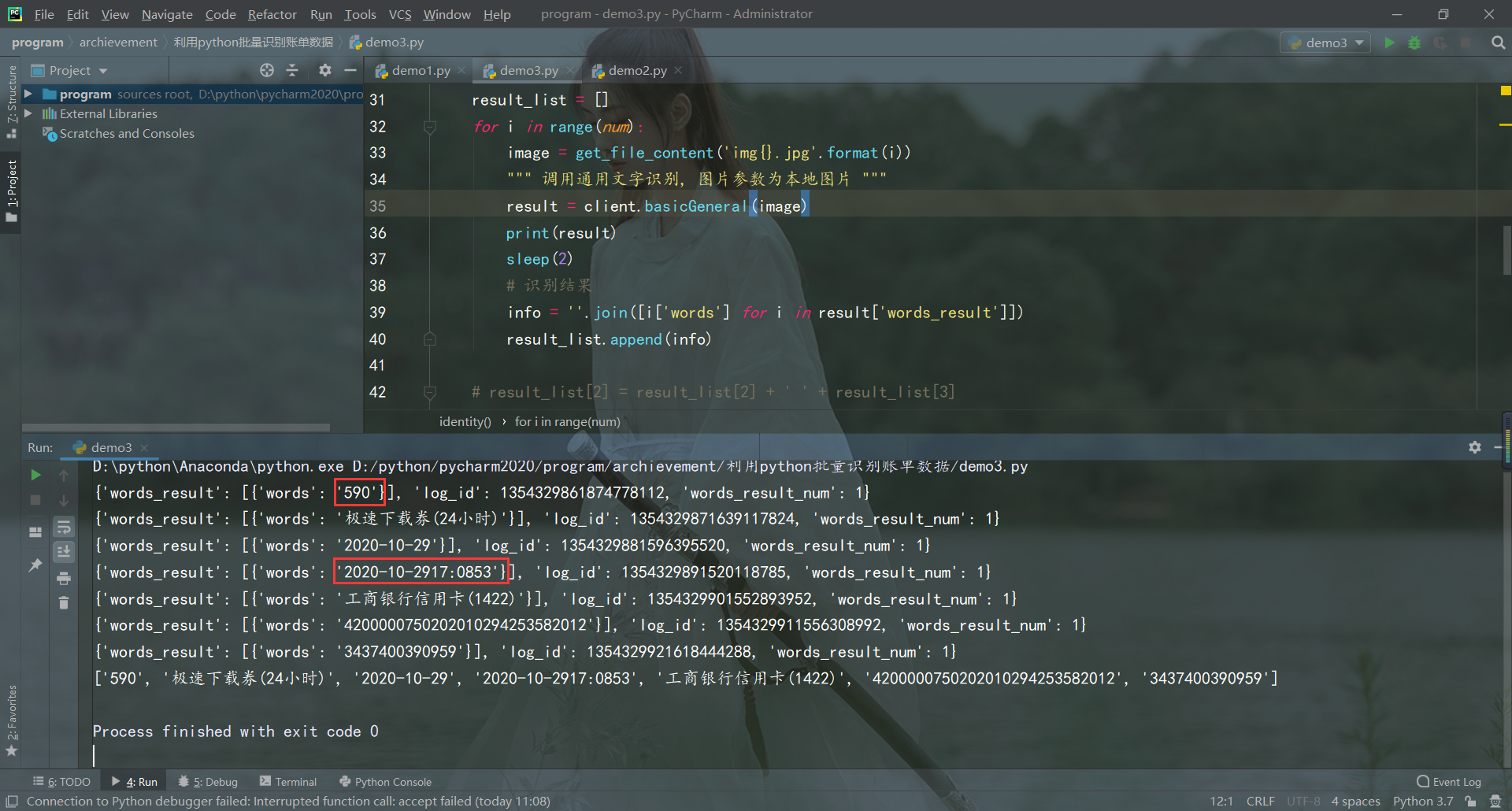
發現調用 client.basicGeneral(image),通用文字識別,-5.90識別成590,而圖像里支付時間年月日 時分秒之間間隔小,識別出來都在一起了,需要把支付時間的年月日 時分秒分別分割出來識別,調用 client.basicAccurate(image),通用文字識別(高精度版)。
完整實現如下:
"""
@File :test_01.py
@Author :葉庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
from aip import AipOcr
from pathlib import Path
import cv2 as cv
from time import sleep
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet.append(['消費', '商品', '支付時間', '支付方式', '交易單號', '商品單號'])
# """ 改成你的 百度云服務的 ID AK SK """
APP_ID = '18690701'
API_KEY = 'QFaTVXvZdPrR05dNlR5I49xA'
SECRET_KEY = '*******************************'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
""" 讀取圖片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
def identity(num):
result_list = []
for i in range(num):
image = get_file_content('img{}.jpg'.format(i))
""" 調用通用文字識別, 圖片參數為本地圖片 """
result = client.basicAccurate(image)
print(result)
sleep(1)
# 識別結果
info = ''.join([i['words'] for i in result['words_result']])
result_list.append(info)
result_list[2] = result_list[2] + ' ' + result_list[3]
result_list.pop(3)
print(result_list)
sheet.append(result_list)
# 換成你放圖片的路徑
p = Path(r'D:\test\test_img')
# 得到所有文件夾下 .jpg 圖片
file = p.glob('**/*.jpg')
for img_file in file:
img_file = str(img_file)
src = cv.imread(r'{}'.format(img_file))
src = cv.resize(src, None, fx=0.5, fy=0.5)
# print(src.shape)
img = src[280:850, 10:580] # 截取圖片 高、寬范圍
money = img[70:130, 150:450] # 支出金額
goods = img[280:330, 160:560] # 商品
time_1 = img[380:425, 160:292] # 支付時間 年月日
time_2 = img[380:425, 290:390] # 支付時間 時分秒
way = img[430:475, 160:560] # 支付方式
num_1 = img[480:520, 160:560] # 交易單號
num_2 = img[525:570, 160:560] # 商戶單號
img_list = [money, goods, time_1, time_2, way, num_1, num_2]
for index_, item in enumerate(img_list):
cv.imwrite(f'img{index_}.jpg', item)
identity(len(img_list))
# cv.imshow('img', img)
# cv.imshow('goods', time_2)
# cv.waitKey(0)
wb.save(filename='識別賬單結果.xlsx')
結果如下:


識別結果還不錯,成功利用 Python 批量識別電子賬單數據,并將數據保存到Excel。
到此這篇關于利用Python批量識別電子賬單數據的文章就介紹到這了,更多相關Python識別電子賬單內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
標簽:海南 郴州 大慶 平頂山 烏蘭察布 哈爾濱 合肥 烏蘭察布
巨人網絡通訊聲明:本文標題《利用Python批量識別電子賬單數據的方法》,本文關鍵詞 利用,Python,批量,識別,電子,;如發現本文內容存在版權問題,煩請提供相關信息告之我們,我們將及時溝通與處理。本站內容系統采集于網絡,涉及言論、版權與本站無關。



