性能優(yōu)化涉及面很廣。一般而言,性能優(yōu)化指降低響應(yīng)時(shí)間和提高系統(tǒng)吞吐量?jī)蓚€(gè)方面,但在流量高峰時(shí)候,性能問(wèn)題往往會(huì)表現(xiàn)為服務(wù)可用性下降,所以性能優(yōu)化也可以包括提高服務(wù)可用性。在某些情況下,降低響應(yīng)時(shí)間、提高系統(tǒng)吞吐量和提高服務(wù)可用性三者相互矛盾,不可兼得。例如:增加緩存可以降低平均響應(yīng)時(shí)間,但是處理線程數(shù)量會(huì)因?yàn)榫彺孢^(guò)大而有所限制,從而降低系統(tǒng)吞吐量;為了提高服務(wù)可用性,對(duì)異常請(qǐng)求重復(fù)調(diào)用是一個(gè)常用的做法,但是這會(huì)提高響應(yīng)時(shí)間并降低系統(tǒng)吞吐量。
對(duì)于很多像美團(tuán)這樣的公司,它們的系統(tǒng)會(huì)面臨如下三個(gè)挑戰(zhàn):1. 日益增長(zhǎng)的用戶(hù)數(shù)量,2. 日漸復(fù)雜的業(yè)務(wù),3. 急劇膨脹的數(shù)據(jù)。這些挑戰(zhàn)對(duì)于性能優(yōu)化而言表現(xiàn)為:在保持和降低系統(tǒng)TP95響應(yīng)時(shí)間(指的是將一段時(shí)間內(nèi)的請(qǐng)求響應(yīng)時(shí)間從低到高排序,高于95%請(qǐng)求響應(yīng)時(shí)間的下確界)的前提下,不斷提高系統(tǒng)吞吐量,提升流量高峰時(shí)期的服務(wù)可用性。這種場(chǎng)景下,三者的目標(biāo)和改進(jìn)方法取得了比較好的一致。本文主要目標(biāo)是為類(lèi)似的場(chǎng)景提供優(yōu)化方案,確保系統(tǒng)在流量高峰時(shí)期的快速響應(yīng)和高可用。
文章第一部分是介紹,包括采用模式方式講解的優(yōu)點(diǎn),文章所采用案例的說(shuō)明,以及后面部分用到的一些設(shè)計(jì)原則;第二部分介紹幾種典型的“性能惡化模式”,闡述導(dǎo)致系統(tǒng)性能惡化,服務(wù)可用性降低的典型場(chǎng)景以及形成惡化循環(huán)的過(guò)程;第三部分是文章重點(diǎn),闡述典型的“性能優(yōu)化模式”,這些模式或者可以使服務(wù)遠(yuǎn)離“惡化模式”,或者直接對(duì)服務(wù)性能進(jìn)行優(yōu)化;文章最后一部分進(jìn)行總結(jié),并對(duì)未來(lái)可能出現(xiàn)的新模式進(jìn)行展望。
介紹
模式講解方式
關(guān)于性能優(yōu)化的文章和圖書(shū)已有很多,但就我所知,還沒(méi)有采用模式的方式去講解的。本文借鑒《設(shè)計(jì)模式》("Design Patterns-Elements of Reusable Object-Oriented Software")對(duì)設(shè)計(jì)模式的闡述方式,首先為每一種性能優(yōu)化模式取一個(gè)貼切的名字,便于讀者快速理解和深刻記憶,接著講解該模式的動(dòng)機(jī)和原理,然后結(jié)合作者在美團(tuán)的具體工作案例進(jìn)行深度剖析,最后總結(jié)采用該模式的優(yōu)點(diǎn)以及需要付出的代價(jià)。簡(jiǎn)而言之,本文采用“命名-->原理和動(dòng)機(jī)-->具體案例-->缺點(diǎn)和優(yōu)點(diǎn)”的四階段方式進(jìn)行性能優(yōu)化模式講解。與其他方式相比,采用模式進(jìn)行講解有兩個(gè)方面的優(yōu)點(diǎn):一方面,讀者不僅僅能夠掌握優(yōu)化手段,而且能夠了解采用該手段進(jìn)行性能優(yōu)化的場(chǎng)景以及所需付出的代價(jià),這有利于讀者全面理解和靈活應(yīng)用;另一方面,模式解決的是特定應(yīng)用場(chǎng)景下的一類(lèi)問(wèn)題,所以應(yīng)用場(chǎng)景描述貫穿于模式講解之中。如此,即使讀者對(duì)原理不太了解,只要碰到的問(wèn)題符合某個(gè)特定模式的應(yīng)用場(chǎng)景(這往往比理解原理要簡(jiǎn)單),就可以采用對(duì)應(yīng)的手段進(jìn)行優(yōu)化,進(jìn)一步促進(jìn)讀者對(duì)模式的理解和掌握。
案例說(shuō)明
文章的所有案例都來(lái)自于美團(tuán)的真實(shí)項(xiàng)目。出于兩方面的考慮,作者做了一定的簡(jiǎn)化和抽象:一方面,系統(tǒng)可以?xún)?yōu)化的問(wèn)題眾多,而一個(gè)特定的模式只能解決幾類(lèi)問(wèn)題,所以在案例分析過(guò)程中會(huì)突出與模式相關(guān)的問(wèn)題;另一方面,任何一類(lèi)問(wèn)題都需要多維度數(shù)據(jù)去描述,而應(yīng)用性能優(yōu)化模式的前提是多維度數(shù)據(jù)的組合值超過(guò)了某個(gè)臨界點(diǎn),但是精確定義每個(gè)維度數(shù)值的臨界點(diǎn)是一件很難的事情,更別說(shuō)多維度數(shù)據(jù)組合之后臨界點(diǎn)。因此有必要對(duì)案例做一些簡(jiǎn)化,確保相關(guān)取值范圍得到滿足。基于以上以及其他原因,作者所給出的解決方案只是可行性方案,并不保證其是所碰到問(wèn)題的最佳解決方案。
案例涉及的所有項(xiàng)目都是基于Java語(yǔ)言開(kāi)發(fā)的,嚴(yán)格地講,所有模式適用的場(chǎng)景是基于Java語(yǔ)言搭建的服務(wù)。從另外一方面講,Java和C++的主要區(qū)別在于垃圾回收機(jī)制,所以,除去和垃圾回收機(jī)制緊密相關(guān)的模式之外,文章所描述的模式也適用于采用C++語(yǔ)言搭建的服務(wù)。對(duì)于基于其他語(yǔ)言開(kāi)發(fā)的服務(wù),讀者在閱讀以及實(shí)踐的過(guò)程中需要考慮語(yǔ)言之間的差別。
設(shè)計(jì)原則
必須說(shuō)明,本文中各種模式所要解決的問(wèn)題之所以會(huì)出現(xiàn),部分是因?yàn)楣こ處熯\(yùn)用了某些深層次的設(shè)計(jì)原則。有些設(shè)計(jì)原則看上去和優(yōu)秀的設(shè)計(jì)理念相悖,模式所解決的問(wèn)題似乎完全可以避免,但是它們卻被廣泛使用。“存在即合理”,世界上沒(méi)有完美的設(shè)計(jì)方案,任何方案都是一系列設(shè)計(jì)原則的妥協(xié)結(jié)果,所以本文主要關(guān)注點(diǎn)是解決所碰到的問(wèn)題而不是如何繞過(guò)這些設(shè)計(jì)原則。下面對(duì)文中重要的設(shè)計(jì)原則進(jìn)行詳細(xì)闡述,在后面需要運(yùn)用該原則時(shí)將不再解釋。
最小可用原則
最小可用原則(快速接入原則)有兩個(gè)關(guān)注點(diǎn):1. 強(qiáng)調(diào)快速接入,快速完成;2. 實(shí)現(xiàn)核心功能可用。這是一個(gè)被普遍運(yùn)用的原則,其目標(biāo)是縮短測(cè)試周期,增加試錯(cuò)機(jī)會(huì),避免過(guò)度設(shè)計(jì)。為了快速接入就必須最大限度地利用已有的解決方案或系統(tǒng)。從另外一個(gè)角度講,一個(gè)解決方案或系統(tǒng)只要能夠滿足基本需求,就滿足最小可用原則的應(yīng)用需求。過(guò)度強(qiáng)調(diào)快速接入原則會(huì)導(dǎo)致重構(gòu)風(fēng)險(xiǎn)的增加,原則上講,基于該原則去設(shè)計(jì)系統(tǒng)需要為重構(gòu)做好準(zhǔn)備。
經(jīng)濟(jì)原則
經(jīng)濟(jì)原則關(guān)注的是成本問(wèn)題,看起來(lái)很像最小可用原則,但是它們之間關(guān)注點(diǎn)不同。最小可用原則的目標(biāo)是通過(guò)降低開(kāi)發(fā)周期,快速接入而實(shí)現(xiàn)風(fēng)險(xiǎn)可控,而快速接入并不意味著成本降低,有時(shí)候?yàn)榱藢?shí)現(xiàn)快速接入可能需要付出巨大的成本。軟件項(xiàng)目的生命周期包括:預(yù)研、設(shè)計(jì)、開(kāi)發(fā)、測(cè)試、運(yùn)行、維護(hù)等階段。最小可用原則主要運(yùn)用在預(yù)研階段,而經(jīng)濟(jì)原則可以運(yùn)用在整個(gè)軟件生命周期里,也可以只關(guān)注某一個(gè)或者幾個(gè)階段。例如:運(yùn)行時(shí)經(jīng)濟(jì)原則需要考慮的系統(tǒng)成本包括單次請(qǐng)求的CPU、內(nèi)存、網(wǎng)絡(luò)、磁盤(pán)消耗等;設(shè)計(jì)階段的經(jīng)濟(jì)原則要求避免過(guò)度設(shè)計(jì);開(kāi)發(fā)階段的經(jīng)濟(jì)原則可能關(guān)注代碼復(fù)用,工程師資源復(fù)用等。
代碼復(fù)用原則
代碼復(fù)用原則分為兩個(gè)層次:第一個(gè)層次使用已有的解決方案或調(diào)用已存在的共享庫(kù)(Shared Library),也稱(chēng)為方案復(fù)用;第二個(gè)層次是直接在現(xiàn)有的代碼庫(kù)中開(kāi)發(fā),也稱(chēng)之為共用代碼庫(kù)。
方案復(fù)用是一個(gè)非常實(shí)用主義的原則,它的出發(fā)點(diǎn)就是最大限度地利用手頭已有的解決方案,即使這個(gè)方案并不好。方案的形式可以是共享庫(kù),也可以是已存在的服務(wù)。方案復(fù)用的例子參見(jiàn)避免蚊子大炮模式的具體案例。用搜索引擎服務(wù)來(lái)解決查找附近商家的問(wèn)題是一個(gè)性能很差的方案,但仍被很多工程師使用。方案復(fù)用原則的一個(gè)顯著優(yōu)點(diǎn)就是提高生產(chǎn)效率,例如:Java之所以能夠得到如此廣泛應(yīng)用,原因之一就是有大量可以重復(fù)利用的開(kāi)源庫(kù)。實(shí)際上“Write once, run anywhere”是Java語(yǔ)言最核心的設(shè)計(jì)理念之一。基于Java語(yǔ)言開(kāi)發(fā)的代碼庫(kù)因此得以在不同硬件平臺(tái)、不同操作系統(tǒng)上更廣泛地使用。
共用代碼庫(kù)要求在同一套代碼庫(kù)中完成所有功能開(kāi)發(fā)。采用這個(gè)原則,代碼庫(kù)中的所有功能編譯時(shí)可見(jiàn),新功能代碼可以無(wú)邊界的調(diào)用老代碼。另外,原代碼庫(kù)已存在的各種運(yùn)行、編譯、測(cè)試、配置環(huán)境可復(fù)用。主要有兩個(gè)方面地好處:1. 充分利用代碼庫(kù)中已有的基礎(chǔ)設(shè)施,快速接入新業(yè)務(wù);2. 直接調(diào)用原代碼中的基礎(chǔ)功能或原語(yǔ),避免網(wǎng)絡(luò)或進(jìn)程間調(diào)用開(kāi)銷(xiāo),性能更佳。共用代碼庫(kù)的例子參見(jiàn)垂直分割模式的具體案例。
從設(shè)計(jì)的角度上講,方案復(fù)用類(lèi)似于微服務(wù)架構(gòu)(Microservice Architecture,有些觀點(diǎn)認(rèn)為這是一種形式的SOA),而共用代碼庫(kù)和Monolithic Architecture很接近。總的來(lái)說(shuō),微服務(wù)傾向于面向接口編程,要求設(shè)計(jì)出可重用性的組件(Library或Service),通過(guò)分層組織各層組件來(lái)實(shí)現(xiàn)良好的架構(gòu)。與之相對(duì)應(yīng),Monolith Architecture則希望盡可能在一套代碼庫(kù)中開(kāi)發(fā),通過(guò)直接調(diào)用代碼中的基礎(chǔ)功能或原語(yǔ)而實(shí)現(xiàn)性能的優(yōu)化和快速迭代。使用Monolith Architecture有很大的爭(zhēng)議,被認(rèn)為不符合“設(shè)計(jì)模式”的理念。參考文獻(xiàn)[4],Monolithic Design主要的缺點(diǎn)包括:1. 缺乏美感;2. 很難重構(gòu);3. 過(guò)早優(yōu)化(參見(jiàn)文獻(xiàn)[6]Optimize judiciously); 4. 不可重用;5. 限制眼界。微服務(wù)架構(gòu)是很多互聯(lián)網(wǎng)公司的主流架構(gòu),典型的運(yùn)用公司包括Amazon、美團(tuán)等。Monolithic Architecture也有其忠實(shí)的粉絲,例如:Tripadvisor的全球網(wǎng)站就共用一套代碼庫(kù);基于性能的考慮,Linux最終選擇的也是Monolithic kernel的模式。
奧卡姆剃刀原則
系統(tǒng)設(shè)計(jì)以及代碼編寫(xiě)要遵循奧卡姆剃刀原則:Entities should not be multiplied unnecessarily。一般而言,一個(gè)系統(tǒng)的代碼量會(huì)隨著其功能增加而變多。系統(tǒng)的健壯性有時(shí)候也需要通過(guò)編寫(xiě)異常處理代碼來(lái)實(shí)現(xiàn)。異常考慮越周全,異常處理代碼量越大。但是隨著代碼量的增大,引入Bug的概率也就越大,系統(tǒng)也就越不健壯。從另外一個(gè)角度來(lái)講,異常流程處理代碼也要考慮健壯性問(wèn)題,這就形成了無(wú)限循環(huán)。所以在系統(tǒng)設(shè)計(jì)和代碼編寫(xiě)過(guò)程中,奧卡姆剃刀原則要求:一個(gè)功能模塊如非必要,就不要;一段代碼如非必寫(xiě),就不寫(xiě)。
奧卡姆剃刀原則和最小可用原則有所區(qū)別。最小可用原則主要運(yùn)用于產(chǎn)品MVP階段,本文所指的奧卡姆剃刀原則主要指系統(tǒng)設(shè)計(jì)和代碼編寫(xiě)兩個(gè)方面,這是完全不同的兩個(gè)概念。MVP包含系統(tǒng)設(shè)計(jì)和代碼編寫(xiě),但同時(shí),系統(tǒng)設(shè)計(jì)和代碼編寫(xiě)也可以發(fā)生在成熟系統(tǒng)的迭代階段。
性能惡化模式
在講解性能優(yōu)化模式之前,有必要先探討一下性能惡化模式,因?yàn)椋?/p>
很多性能優(yōu)化模式的目標(biāo)之一就是避免系統(tǒng)進(jìn)入性能惡化模式;
不同性能優(yōu)化模式可能是避免同一種性能惡化模式;
同一種性能優(yōu)化模式可能在不同階段避免不同的性能惡化模式。
在此統(tǒng)一闡述性能惡化模式,避免下文重復(fù)解釋。為了便于讀者清晰識(shí)別惡化模式和優(yōu)化模式,惡化模式采用“XXX反模式”的方式進(jìn)行命名。
長(zhǎng)請(qǐng)求擁塞反模式(High Latency Invocating AntiPattern)
這是一種單次請(qǐng)求時(shí)延變長(zhǎng)而導(dǎo)致系統(tǒng)性能惡化甚至崩潰的惡化模式。對(duì)于多線程服務(wù),大量請(qǐng)求時(shí)間變長(zhǎng)會(huì)使線程堆積、內(nèi)存使用增加,最終可能會(huì)通過(guò)如下三種方式之一惡化系統(tǒng)性能:
線程數(shù)目變多導(dǎo)致線程之間CPU資源使用沖突,反過(guò)來(lái)進(jìn)一步延長(zhǎng)了單次請(qǐng)求時(shí)間;
線程數(shù)量增多以及線程中緩存變大,內(nèi)存消耗隨之劇增,對(duì)于基于Java語(yǔ)言的服務(wù)而言,又會(huì)更頻繁地full GC,反過(guò)來(lái)單次請(qǐng)求時(shí)間會(huì)變得更長(zhǎng);
內(nèi)存使用增多,會(huì)使操作系統(tǒng)內(nèi)存不足,必須使用Swap,可能導(dǎo)致服務(wù)徹底崩潰。
典型惡化流程圖如下圖:
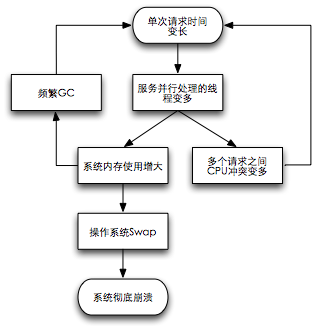
長(zhǎng)請(qǐng)求擁塞反模式所導(dǎo)致的性能惡化現(xiàn)象非常普遍,所以識(shí)別該模式非常重要。典型的場(chǎng)景如下:某復(fù)雜業(yè)務(wù)系統(tǒng)依賴(lài)于多個(gè)服務(wù),其中某個(gè)服務(wù)的響應(yīng)時(shí)間變長(zhǎng),隨之系統(tǒng)整體響應(yīng)時(shí)間變長(zhǎng),進(jìn)而出現(xiàn)CPU、內(nèi)存、Swap報(bào)警。系統(tǒng)進(jìn)入長(zhǎng)請(qǐng)求擁塞反模式的典型標(biāo)識(shí)包括:被依賴(lài)服務(wù)可用性變低、響應(yīng)時(shí)間變長(zhǎng)、服務(wù)的某段計(jì)算邏輯時(shí)間變長(zhǎng)等。
多次請(qǐng)求杠桿反模式(Levered Multilayer Invocating AntiPattern)
客戶(hù)端一次用戶(hù)點(diǎn)擊行為往往會(huì)觸發(fā)多次服務(wù)端請(qǐng)求,這是一次請(qǐng)求杠桿;每個(gè)服務(wù)端請(qǐng)求進(jìn)而觸發(fā)多個(gè)更底層服務(wù)的請(qǐng)求,這是第二次請(qǐng)求杠桿。每一層請(qǐng)求可能導(dǎo)致一次請(qǐng)求杠桿,請(qǐng)求層級(jí)越多,杠桿效應(yīng)就越大。在多次請(qǐng)求杠桿反模式下運(yùn)行的分布式系統(tǒng),處于深層次的服務(wù)需要處理大量請(qǐng)求,容易會(huì)成為系統(tǒng)瓶頸。與此同時(shí),大量請(qǐng)求也會(huì)給網(wǎng)絡(luò)帶來(lái)巨大壓力,特別是對(duì)于單次請(qǐng)求數(shù)據(jù)量很大的情況,網(wǎng)絡(luò)可能會(huì)成為系統(tǒng)徹底崩潰的導(dǎo)火索。典型惡化流程圖如下圖:
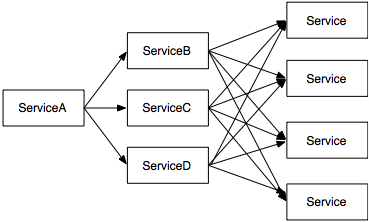
多次請(qǐng)求杠桿所導(dǎo)致的性能惡化現(xiàn)象非常常見(jiàn),例如:對(duì)于美團(tuán)推薦系統(tǒng),一個(gè)用戶(hù)列表請(qǐng)求會(huì)有多個(gè)算法參與,每個(gè)算法會(huì)召回多個(gè)列表單元(商家或者團(tuán)購(gòu)),每個(gè)列表單元有多種屬性和特征,而這些屬性和特征數(shù)據(jù)服務(wù)又分布在不同服務(wù)和機(jī)器上面,所以客戶(hù)端的一次用戶(hù)展現(xiàn)可能導(dǎo)致了成千上萬(wàn)的最底層服務(wù)調(diào)用。對(duì)于存在多次請(qǐng)求杠桿反模式的分布式系統(tǒng),性能惡化與流量之間往往遵循指數(shù)曲線關(guān)系。這意味著,在平常流量下正常運(yùn)行服務(wù)系統(tǒng),在流量高峰時(shí)通過(guò)線性增加機(jī)器解決不了可用性問(wèn)題。所以,識(shí)別并避免系統(tǒng)進(jìn)入多次請(qǐng)求杠桿反模式對(duì)于提高系統(tǒng)可用性而言非常關(guān)鍵。
反復(fù)緩存反模式(Recurrent Caching AntiPattern)
為了降低響應(yīng)時(shí)間,系統(tǒng)往往在本地內(nèi)存中緩存很多數(shù)據(jù)。緩存數(shù)據(jù)越多,命中率就越高,平均響應(yīng)時(shí)間就越快。為了降低平均響應(yīng)時(shí)間,有些開(kāi)發(fā)者會(huì)不加限制地緩存各種數(shù)據(jù),在正常流量情況下,系統(tǒng)響應(yīng)時(shí)間和吞吐量都有很大改進(jìn)。但是當(dāng)流量高峰來(lái)臨時(shí),系統(tǒng)內(nèi)存使用開(kāi)始增多,觸發(fā)了JVM進(jìn)行full GC,進(jìn)而導(dǎo)致大量緩存被釋放(因?yàn)橹髁鱆ava內(nèi)存緩存都采用SoftReference和WeakReference所導(dǎo)致的),而大量請(qǐng)求又使得緩存被迅速填滿,這就是反復(fù)緩存。反復(fù)緩存導(dǎo)致了頻繁的full GC,而頻繁full GC往往會(huì)導(dǎo)致系統(tǒng)性能急劇惡化。典型惡化流程圖如下圖:
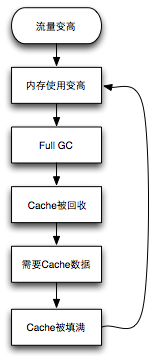
反復(fù)緩存所導(dǎo)致性能惡化的原因是無(wú)節(jié)制地使用緩存。緩存使用的指導(dǎo)原則是:工程師們?cè)谑褂镁彺鏁r(shí)必須全局考慮,精細(xì)規(guī)劃,確保數(shù)據(jù)完全緩存的情況下,系統(tǒng)仍然不會(huì)頻繁full GC。為了確保這一點(diǎn),對(duì)于存在多種類(lèi)型緩存以及系統(tǒng)流量變化很大的系統(tǒng),設(shè)計(jì)者必須嚴(yán)格控制緩存大小,甚至廢除緩存(這是典型為了提高流量高峰時(shí)可用性,而降低平均響應(yīng)時(shí)間的一個(gè)例子)。反復(fù)緩存反模式往往發(fā)生在流量高峰時(shí)候,通過(guò)線性增加機(jī)器和提高機(jī)器內(nèi)存可以大大減少系統(tǒng)崩潰的概率。
性能優(yōu)化模式
水平分割模式(Horizontal partitioning Pattern)
原理和動(dòng)機(jī)
典型的服務(wù)端運(yùn)行流程包含四個(gè)環(huán)節(jié):接收請(qǐng)求、獲取數(shù)據(jù)、處理數(shù)據(jù)、返回結(jié)果。在一次請(qǐng)求中,獲取數(shù)據(jù)和處理數(shù)據(jù)往往多次發(fā)生。在完全串行運(yùn)行的系統(tǒng)里,一次請(qǐng)求總響應(yīng)時(shí)間滿足如下公式:
一次請(qǐng)求總耗時(shí)=解析請(qǐng)求耗時(shí) + ∑(獲取數(shù)據(jù)耗時(shí)+處理數(shù)據(jù)耗時(shí)) + 組裝返回結(jié)果耗時(shí)
大部分耗時(shí)長(zhǎng)的服務(wù)主要時(shí)間都花在中間兩個(gè)環(huán)節(jié),即獲取數(shù)據(jù)和處理數(shù)據(jù)環(huán)節(jié)。對(duì)于非計(jì)算密集性的系統(tǒng),主要耗時(shí)都用在獲取數(shù)據(jù)上面。獲取數(shù)據(jù)主要有三個(gè)來(lái)源:本地緩存,遠(yuǎn)程緩存或者數(shù)據(jù)庫(kù),遠(yuǎn)程服務(wù)。三者之中,進(jìn)行遠(yuǎn)程數(shù)據(jù)庫(kù)訪問(wèn)或遠(yuǎn)程服務(wù)調(diào)用相對(duì)耗時(shí)較長(zhǎng),特別是對(duì)于需要進(jìn)行多次遠(yuǎn)程調(diào)用的系統(tǒng),串行調(diào)用所帶來(lái)的累加效應(yīng)會(huì)極大地延長(zhǎng)單次請(qǐng)求響應(yīng)時(shí)間,這就增大了系統(tǒng)進(jìn)入長(zhǎng)請(qǐng)求擁塞反模式的概率。如果能夠?qū)Σ煌臉I(yè)務(wù)請(qǐng)求并行處理,請(qǐng)求總耗時(shí)就會(huì)大大降低。例如下圖中,Client需要對(duì)三個(gè)服務(wù)進(jìn)行調(diào)用,如果采用順序調(diào)用模式,系統(tǒng)的響應(yīng)時(shí)間為18ms,而采用并行調(diào)用只需要7ms。

水平分割模式首先將整個(gè)請(qǐng)求流程切分為必須相互依賴(lài)的多個(gè)Stage,而每個(gè)Stage包含相互獨(dú)立的多種業(yè)務(wù)處理(包括計(jì)算和數(shù)據(jù)獲取)。完成切分之后,水平分割模式串行處理多個(gè)Stage,但是在Stage內(nèi)部并行處理。如此,一次請(qǐng)求總耗時(shí)等于各個(gè)Stage耗時(shí)總和,每個(gè)Stage所耗時(shí)間等于該Stage內(nèi)部最長(zhǎng)的業(yè)務(wù)處理時(shí)間。
水平分割模式有兩個(gè)關(guān)鍵優(yōu)化點(diǎn):減少Stage數(shù)量和降低每個(gè)Stage耗時(shí)。為了減少Stage數(shù)量,需要對(duì)一個(gè)請(qǐng)求中不同業(yè)務(wù)之間的依賴(lài)關(guān)系進(jìn)行深入分析并進(jìn)行解耦,將能夠并行處理的業(yè)務(wù)盡可能地放在同一個(gè)Stage中,最終將流程分解成無(wú)法獨(dú)立運(yùn)行的多個(gè)Stage。降低單個(gè)Stage耗時(shí)一般有兩種思路:1. 在Stage內(nèi)部再?lài)L試水平分割(即遞歸水平分割),2. 對(duì)于一些可以放在任意Stage中進(jìn)行并行處理的流程,將其放在耗時(shí)最長(zhǎng)的Stage內(nèi)部進(jìn)行并行處理,避免耗時(shí)較短的Stage被拉長(zhǎng)。
水平分割模式不僅可以降低系統(tǒng)平均響應(yīng)時(shí)間,而且可以降低TP95響應(yīng)時(shí)間(這兩者有時(shí)候相互矛盾,不可兼得)。通過(guò)降低平均響應(yīng)時(shí)間和TP95響應(yīng)時(shí)間,水平分割模式往往能夠大幅度提高系統(tǒng)吞吐量以及高峰時(shí)期系統(tǒng)可用性,并大大降低系統(tǒng)進(jìn)入長(zhǎng)請(qǐng)求擁塞反模式的概率。
具體案例:
我們的挑戰(zhàn)來(lái)自為用戶(hù)提供高性能的優(yōu)質(zhì)個(gè)性化列表服務(wù),每一次列表服務(wù)請(qǐng)求會(huì)有多個(gè)算法參與,而每個(gè)算法基本上都采用“召回->特征獲取->計(jì)算”的模式。 在進(jìn)行性能優(yōu)化之前,算法之間采用順序執(zhí)行的方式。伴隨著算法工程師的持續(xù)迭代,算法數(shù)量越來(lái)越多,隨之而來(lái)的結(jié)果就是客戶(hù)端響應(yīng)時(shí)間越來(lái)越長(zhǎng),系統(tǒng)很容易進(jìn)入長(zhǎng)請(qǐng)求擁塞反模式。曾經(jīng)有一段時(shí)間,一旦流量高峰來(lái)臨,出現(xiàn)整條服務(wù)鏈路的機(jī)器CPU、內(nèi)存報(bào)警。在對(duì)系統(tǒng)進(jìn)行分析之后,我們采取了如下三個(gè)優(yōu)化措施,最終使得系統(tǒng)TP95時(shí)間降低了一半:
算法之間并行計(jì)算;
每個(gè)算法內(nèi)部,多次特征獲取進(jìn)行了并行處理;
在調(diào)度線程對(duì)工作線程進(jìn)行調(diào)度的時(shí)候,耗時(shí)最長(zhǎng)的線程最先調(diào)度,最后處理。
缺點(diǎn)和優(yōu)點(diǎn)
對(duì)成熟系統(tǒng)進(jìn)行水平切割,意味著對(duì)原系統(tǒng)的重大重構(gòu),工程師必須對(duì)業(yè)務(wù)和系統(tǒng)非常熟悉,所以要謹(jǐn)慎使用。水平切割主要有兩方面的難點(diǎn):
并行計(jì)算將原本單一線程的工作分配給多線程處理,提高了系統(tǒng)的復(fù)雜度。而多線程所引入的安全問(wèn)題讓系統(tǒng)變得脆弱。與此同時(shí),多線程程序測(cè)試很難,因此重構(gòu)后系統(tǒng)很難與原系統(tǒng)在業(yè)務(wù)上保持一致。
對(duì)于一開(kāi)始就基于單線程處理模式編寫(xiě)的系統(tǒng),有些流程在邏輯上能夠并行處理,但是在代碼層次上由于相互引用已經(jīng)難以分解。所以并行重構(gòu)意味著對(duì)共用代碼進(jìn)行重復(fù)撰寫(xiě),增大系統(tǒng)的整體代碼量,違背奧卡姆剃刀原則。
對(duì)于上面提到的第二點(diǎn),舉例如下:A和B是邏輯可以并行處理的兩個(gè)流程,基于單線程設(shè)計(jì)的代碼,假定處理完A后再處理B。在編寫(xiě)處理B邏輯代碼時(shí)候,如果B需要的資源已經(jīng)在處理A的過(guò)程中產(chǎn)生,工程師往往會(huì)直接使用A所產(chǎn)生的數(shù)據(jù),A和B之間因此出現(xiàn)了緊耦合。并行化需要對(duì)它們之間的公共代碼進(jìn)行拆解,這往往需要引入新的抽象,更改原數(shù)據(jù)結(jié)構(gòu)的可見(jiàn)域。
在如下兩種情況,水平切割所帶來(lái)的好處不明顯:
一個(gè)請(qǐng)求中每個(gè)處理流程需要獲取和緩存的數(shù)據(jù)量很大,而不同流程之間存在大量共享的數(shù)據(jù),但是請(qǐng)求之間數(shù)據(jù)共享卻很少。在這種情況下,流程處理完之后,數(shù)據(jù)和緩存都會(huì)清空。采用順序處理模式,數(shù)據(jù)可以被緩存在線程局部存儲(chǔ)(ThreadLocal)中而減少重復(fù)獲取數(shù)據(jù)的成本;如果采用水平切割的模式,在一次請(qǐng)求中,不同流程會(huì)多次獲取并緩存的同一類(lèi)型數(shù)據(jù),對(duì)于內(nèi)存原本就很緊張的系統(tǒng),可能會(huì)導(dǎo)致頻繁full GC,進(jìn)入反復(fù)緩存反模式。
某一個(gè)處理流程所需時(shí)間遠(yuǎn)遠(yuǎn)大于其他所有流程所需時(shí)間的總和。這種情況下,水平切割不能實(shí)質(zhì)性地降低請(qǐng)求響應(yīng)時(shí)間。
采用水平切割的模式可以降低系統(tǒng)的平均響應(yīng)時(shí)間和TP95響應(yīng)時(shí)間,以及流量高峰時(shí)系統(tǒng)崩潰的概率。雖然進(jìn)行代碼重構(gòu)比較復(fù)雜,但是水平切割模式非常容易理解,只要熟悉系統(tǒng)的業(yè)務(wù),識(shí)別出可以并行處理的流程,就能夠進(jìn)行水平切割。有時(shí)候,即使少量的并行化也可以顯著提高整體性能。對(duì)于新系統(tǒng)而言,如果存在可預(yù)見(jiàn)的性能問(wèn)題,把水平分割模式作為一個(gè)重要的設(shè)計(jì)理念將會(huì)大大地提高系統(tǒng)的可用性、降低系統(tǒng)的重構(gòu)風(fēng)險(xiǎn)。總的來(lái)說(shuō),雖然存在一些具體實(shí)施的難點(diǎn),水平分割模式是一個(gè)非常有效、容易識(shí)別和理解的模式。
垂直分割模式(Vertical partitioning Pattern)
原理和動(dòng)機(jī):
對(duì)于移動(dòng)互聯(lián)網(wǎng)節(jié)奏的公司,新需求往往是一波接一波。基于代碼復(fù)用原則,工程師們往往會(huì)在一個(gè)系統(tǒng)實(shí)現(xiàn)大量相似卻完全不相干的功能。伴隨著功能的增強(qiáng),系統(tǒng)實(shí)際上變得越來(lái)越脆弱。這種脆弱可能表現(xiàn)在系統(tǒng)響應(yīng)時(shí)間變長(zhǎng)、吞吐量降低或者可用性降低。導(dǎo)致系統(tǒng)脆弱原因主要來(lái)自?xún)煞矫娴臎_突:資源使用沖突和可用性不一致沖突。
資源使用沖突是導(dǎo)致系統(tǒng)脆弱的一個(gè)重要原因。不同業(yè)務(wù)功能并存于同一個(gè)運(yùn)行系統(tǒng)里面意味著資源共享,同時(shí)也意味著資源使用沖突。可能產(chǎn)生沖突的資源包括:CPU、內(nèi)存、網(wǎng)絡(luò)、I/O等。例如:一種業(yè)務(wù)功能,無(wú)論其調(diào)用量多么小,都有一些內(nèi)存開(kāi)銷(xiāo)。對(duì)于存在大量緩存的業(yè)務(wù)功能,業(yè)務(wù)功能數(shù)量的增加會(huì)極大地提高內(nèi)存消耗,從而增大系統(tǒng)進(jìn)入反復(fù)緩存反模式的概率。對(duì)于CPU密集型業(yè)務(wù),當(dāng)產(chǎn)生沖突的時(shí)候,響應(yīng)時(shí)間會(huì)變慢,從而增大了系統(tǒng)進(jìn)入長(zhǎng)請(qǐng)求擁塞反模式的可能性。
不加區(qū)別地將不同可用性要求的業(yè)務(wù)功能放入一個(gè)系統(tǒng)里,會(huì)導(dǎo)致系統(tǒng)整體可用性變低。當(dāng)不同業(yè)務(wù)功能糅合在同一運(yùn)行系統(tǒng)里面的時(shí)候,在運(yùn)維和機(jī)器層面對(duì)不同業(yè)務(wù)的可用性、可靠性進(jìn)行調(diào)配將會(huì)變得很困難。但是,在高峰流量導(dǎo)致系統(tǒng)瀕臨崩潰的時(shí)候,最有效的解決手段往往是運(yùn)維,而最有效手段的失效也就意味著核心業(yè)務(wù)的可用性降低。
垂直分割思路就是將系統(tǒng)按照不同的業(yè)務(wù)功能進(jìn)行分割,主要有兩種分割模式:部署垂直分割和代碼垂直分割。部署垂直分割主要是按照可用性要求將系統(tǒng)進(jìn)行等價(jià)分類(lèi),不同可用性業(yè)務(wù)部署在不同機(jī)器上,高可用業(yè)務(wù)單獨(dú)部署;代碼垂直分割就是讓不同業(yè)務(wù)系統(tǒng)不共享代碼,徹底解決系統(tǒng)資源使用沖突問(wèn)題。
具體案例:
我們的挑戰(zhàn)來(lái)自于美團(tuán)推薦系統(tǒng),美團(tuán)客戶(hù)端的多個(gè)頁(yè)面都有推薦列表。雖然不同的推薦產(chǎn)品需求來(lái)源不同,但是為了實(shí)現(xiàn)快速的接入,基于共用代碼庫(kù)原則,所有的推薦業(yè)務(wù)共享同一套推薦代碼,同一套部署。在一段時(shí)間內(nèi),我們發(fā)現(xiàn)push推薦和首頁(yè)“猜你喜歡推薦”的資源消耗巨大。特別是在push推薦的高峰時(shí)刻,CPU和內(nèi)存頻繁報(bào)警,系統(tǒng)不停地full GC,造成美團(tuán)用戶(hù)進(jìn)入客戶(hù)端時(shí),首頁(yè)出現(xiàn)大片空白。
在對(duì)系統(tǒng)進(jìn)行分析之后,得出兩個(gè)結(jié)論:
首頁(yè)“猜你喜歡”對(duì)用戶(hù)體驗(yàn)影響更大,應(yīng)該給予最高可用性保障,而push推薦給予較低可用性保障;
首頁(yè)“猜你喜歡”和push推薦都需要很大的本地緩存,有較大的內(nèi)存使用沖突,并且響應(yīng)時(shí)間都很長(zhǎng),有嚴(yán)重的CPU使用沖突。
因此我們采取了如下措施,一方面,解決了首頁(yè)“猜你喜歡”的可用性低問(wèn)題,減少了未來(lái)出現(xiàn)可用性問(wèn)題的概率,最終將其TP95響應(yīng)時(shí)間降低了40%;另一方面也提高了其他推薦產(chǎn)品的服務(wù)可用性和高峰吞吐量。
將首頁(yè)“猜你喜歡”推薦進(jìn)行單獨(dú)部署,而將push推薦和其他對(duì)系統(tǒng)資源要求不高的推薦部署在另一個(gè)集群上面;
對(duì)于新承接的推薦業(yè)務(wù),新建一套代碼,避免影響首頁(yè)推薦這種最高可用性的業(yè)務(wù)。
缺點(diǎn)和優(yōu)點(diǎn):
垂直分割主要的缺點(diǎn)主要有兩個(gè):
增加了維護(hù)成本。一方面代碼庫(kù)數(shù)量增多提高了開(kāi)發(fā)工程師的維護(hù)成本,另一方面,部署集群的變多會(huì)增加運(yùn)維工程師的工作量;
代碼不共享所導(dǎo)致的重復(fù)編碼工作。
解決重復(fù)編碼工作問(wèn)題的一個(gè)思路就是為不同的系統(tǒng)提供共享庫(kù)(Shared Library),但是這種耦合反過(guò)來(lái)可能導(dǎo)致部署機(jī)器中引入未部署業(yè)務(wù)的開(kāi)銷(xiāo)。所以在共享庫(kù)中要減少靜態(tài)代碼的初始化開(kāi)銷(xiāo),并將類(lèi)似緩存初始化等工作交給上層系統(tǒng)。總的來(lái)說(shuō),通過(guò)共享庫(kù)的方式引入的開(kāi)銷(xiāo)可以得到控制。但是對(duì)于業(yè)務(wù)密集型的系統(tǒng),由于業(yè)務(wù)往往是高度定制化的,共用一套代碼庫(kù)的好處是開(kāi)發(fā)工程師可以采用Copy-on-write的模式進(jìn)行開(kāi)發(fā),需要修改的時(shí)候隨時(shí)拷貝并修改。共享庫(kù)中應(yīng)該存放不容易變化的代碼,避免使用者頻繁升級(jí),所以并不適合這種場(chǎng)景。因此,對(duì)于業(yè)務(wù)密集型的系統(tǒng),分代碼所導(dǎo)致的重復(fù)編碼量是需要權(quán)衡的一個(gè)因素。
垂直分割是一個(gè)非常簡(jiǎn)單而又有效的性能優(yōu)化模式,特別適用于系統(tǒng)已經(jīng)出現(xiàn)問(wèn)題而又需要快速解決的場(chǎng)景。部署層次的分割既安全又有效。需要說(shuō)明的是部署分割和簡(jiǎn)單意義上的加機(jī)器不是一回事,在大部分情況下,即使不增加機(jī)器,僅通過(guò)部署分割,系統(tǒng)整體吞吐量和可用性都有可能提升。所以就短期而言,這幾乎是一個(gè)零成本方案。對(duì)于代碼層次的分割,開(kāi)發(fā)工程師需要在業(yè)務(wù)承接效率和系統(tǒng)可用性上面做一些折衷考慮。
恒變分離模式(Runtime 3NF Pattern)
原理和動(dòng)機(jī):
基于性能的設(shè)計(jì)要求變化的數(shù)據(jù)和不變的數(shù)據(jù)分開(kāi),這一點(diǎn)和基于面向?qū)ο蟮脑O(shè)計(jì)原則相悖。在面向?qū)ο蟮脑O(shè)計(jì)中,為了便于對(duì)一個(gè)對(duì)象有整體的把握,緊密相關(guān)的數(shù)據(jù)集合往往被組裝進(jìn)一個(gè)類(lèi),存儲(chǔ)在一個(gè)數(shù)據(jù)庫(kù)表,即使有部分?jǐn)?shù)據(jù)冗余(關(guān)于面向?qū)ο笈c性能沖突的討論網(wǎng)上有很多文章,本文不細(xì)講)。很多系統(tǒng)的主要工作是處理變化的數(shù)據(jù),如果變化的數(shù)據(jù)和不變的數(shù)據(jù)被緊密組裝在一起,系統(tǒng)對(duì)變化數(shù)據(jù)的操作將引入額外的開(kāi)銷(xiāo)。而如果易變數(shù)據(jù)占總數(shù)據(jù)比例非常小,這種額外開(kāi)銷(xiāo)將會(huì)通過(guò)杠桿效應(yīng)惡化系統(tǒng)性能。分離易變和恒定不變的數(shù)據(jù)在對(duì)象創(chuàng)建、內(nèi)存管理、網(wǎng)絡(luò)傳輸?shù)确矫娑加兄谛阅芴岣摺?/p>
恒變分離模式的原理非常類(lèi)似與數(shù)據(jù)庫(kù)設(shè)計(jì)中的第三范式(3NF):第三范式主要解決的是靜態(tài)存儲(chǔ)中重復(fù)存儲(chǔ)的問(wèn)題,而恒變分離模式解決的是系統(tǒng)動(dòng)態(tài)運(yùn)行時(shí)候恒定數(shù)據(jù)重復(fù)創(chuàng)建、傳輸、存儲(chǔ)和處理的問(wèn)題。按照3NF,如果一個(gè)數(shù)據(jù)表的每一記錄都依賴(lài)于一些非主屬性集合,而這些非主屬性集合大量重復(fù)出現(xiàn),那么應(yīng)該考慮對(duì)被依賴(lài)的非主屬性集合定義一個(gè)新的實(shí)體(構(gòu)建一個(gè)新的數(shù)據(jù)表),原數(shù)據(jù)庫(kù)的記錄依賴(lài)于新實(shí)體的ID。如此一來(lái)數(shù)據(jù)庫(kù)重復(fù)存儲(chǔ)數(shù)據(jù)量將大大降低。類(lèi)似的,按照恒變分離模式,對(duì)于一個(gè)實(shí)體,如果系統(tǒng)處理的只是這個(gè)實(shí)體的少量變化屬性,應(yīng)該將不變的屬性定義為一個(gè)新實(shí)體(運(yùn)行時(shí)的另一個(gè)類(lèi),數(shù)據(jù)庫(kù)中的另一個(gè)表),原來(lái)實(shí)體通過(guò)ID來(lái)引用新實(shí)體,那么原有實(shí)體在運(yùn)行系統(tǒng)中的數(shù)據(jù)傳輸、創(chuàng)建、網(wǎng)絡(luò)開(kāi)銷(xiāo)都會(huì)大大降低。
案例分析:
我們的挑戰(zhàn)是提供一個(gè)高性能、高一致性要求的團(tuán)購(gòu)服務(wù)(DealService)。系統(tǒng)存在一些多次請(qǐng)求杠桿反模式問(wèn)題,客戶(hù)端一次請(qǐng)求會(huì)導(dǎo)致幾十次DealService讀取請(qǐng)求,每次獲取上百個(gè)團(tuán)購(gòu)詳情信息,服務(wù)端單機(jī)需要支持每秒萬(wàn)次級(jí)別的吞吐量。基于需求,系統(tǒng)大體框架設(shè)計(jì)如下:
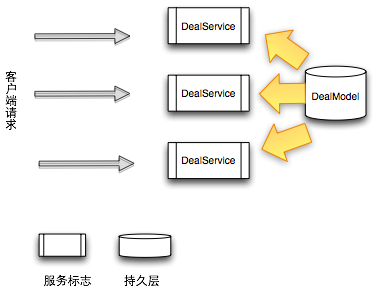
每個(gè)DealService定期從持久層同步所有發(fā)生變化的deal信息,所有的deal信息保存在內(nèi)存里面。在最初的設(shè)計(jì)里面,數(shù)據(jù)庫(kù)只有一個(gè)數(shù)據(jù)表DealModelTable,程序里面也只有一個(gè)實(shí)體類(lèi)DealModel。由于銷(xiāo)量、價(jià)格、用戶(hù)評(píng)價(jià)等信息的頻發(fā)變化,為了達(dá)到高一致性要求,服務(wù)系統(tǒng)每分鐘需要從數(shù)據(jù)庫(kù)同步幾萬(wàn)條記錄。隨著美團(tuán)團(tuán)購(gòu)數(shù)量的增多和用戶(hù)活躍度的增加,系統(tǒng)出現(xiàn)了三個(gè)問(wèn)題:
團(tuán)購(gòu)服務(wù)網(wǎng)卡頻繁報(bào)警,由于這是高性能低延時(shí)服務(wù),又導(dǎo)致了大量的客戶(hù)端超時(shí)異常;
頻繁的full GC,這是由于每條數(shù)據(jù)庫(kù)記錄更新都會(huì)導(dǎo)致運(yùn)行系統(tǒng)里面老的DealModel實(shí)體被銷(xiāo)毀,新的DealModels實(shí)體被創(chuàng)建;
數(shù)據(jù)庫(kù)從庫(kù)滯后主庫(kù),使得服務(wù)數(shù)據(jù)一致性降低,原因是數(shù)據(jù)庫(kù)系統(tǒng)寫(xiě)數(shù)據(jù)量巨大。
在對(duì)系統(tǒng)進(jìn)行分析之后,我們采用了如下措施,大大降低了網(wǎng)絡(luò)傳輸?shù)臄?shù)據(jù)量,緩解了主從數(shù)據(jù)庫(kù)同步壓力,使得客戶(hù)端的超時(shí)異常從高峰時(shí)候的9%降低到了小于0.01%(低于萬(wàn)分之一):
將DealModelTable中的銷(xiāo)量、價(jià)格、用戶(hù)評(píng)價(jià)等常變的信息單獨(dú)構(gòu)建一張數(shù)據(jù)表VariableDealModel;
同時(shí)在代碼中為銷(xiāo)量、價(jià)格、用戶(hù)評(píng)價(jià)等常變數(shù)據(jù)創(chuàng)建一個(gè)單獨(dú)的類(lèi)VariableDealModel;
DealService對(duì)兩張表進(jìn)行分別同步;
如果DealModelTable的記錄產(chǎn)生了更新,運(yùn)行系統(tǒng)銷(xiāo)毀老的DealModel實(shí)體并創(chuàng)建新的DealModel實(shí)體;
如果只是VariableDealModel的記錄產(chǎn)生了更新,只對(duì)VariableDealModel的屬性進(jìn)行更改。
缺點(diǎn)和優(yōu)點(diǎn):
采用恒變分離模式,主要有三個(gè)缺點(diǎn):
不符合面向?qū)ο蟮脑O(shè)計(jì)原則。原本概念上統(tǒng)一的實(shí)體被切分成多個(gè)實(shí)體,會(huì)給開(kāi)發(fā)工程師帶來(lái)一些理解上的困難,因此增加維護(hù)成本。進(jìn)一步而言,這會(huì)增加引入額外Bug的概率(實(shí)際上面向?qū)ο笾匀绱耸軞g迎的一個(gè)重要原因就是容易理解)。
增加了類(lèi)不變量(Class invariant)的維護(hù)難度。很多情況下,Class invariant是通過(guò)語(yǔ)言所提供的封裝(Encapsulation)特性來(lái)維護(hù)的。當(dāng)一個(gè)類(lèi)變成多個(gè)類(lèi),Class invariant可能會(huì)被破壞。如果必須維護(hù)Class invariant,而這種Class invariant又發(fā)生在不同實(shí)體之間,那么往往是把不變的屬性從不變實(shí)體移到易變的實(shí)體中去。
一張數(shù)據(jù)庫(kù)表變成多張,也會(huì)增加維護(hù)成本。
在如下兩種場(chǎng)景下,恒變分離模式所帶來(lái)的好處有限:
易變數(shù)據(jù)導(dǎo)致的操作和傳輸并不頻繁,不是系統(tǒng)主要操作;
易變數(shù)據(jù)占整體數(shù)據(jù)的比例很高,杠桿效應(yīng)不顯著,通過(guò)恒變分離模式不能根本性地解決系統(tǒng)性能問(wèn)題。
總的來(lái)說(shuō),恒變分離模式非常容易理解,其應(yīng)用往往需要滿足兩個(gè)條件:易變數(shù)據(jù)占整體數(shù)據(jù)比例很低(比例越低,杠桿效應(yīng)越大)和易變數(shù)據(jù)所導(dǎo)致的操作又是系統(tǒng)的主要操作。在該場(chǎng)景下,如果系統(tǒng)性能已經(jīng)出現(xiàn)問(wèn)題,犧牲一些可維護(hù)性就顯得物有所值。
大部分系統(tǒng)都是由多種類(lèi)型的數(shù)據(jù)構(gòu)成,大多數(shù)數(shù)據(jù)類(lèi)型的都包含易變、少變和不變的屬性。盲目地進(jìn)行恒變分離會(huì)導(dǎo)致系統(tǒng)的復(fù)雜度指數(shù)級(jí)別的增加,系統(tǒng)變得很難維護(hù),所以系統(tǒng)設(shè)計(jì)者必須在高性能和高維護(hù)性之間找到一個(gè)平衡點(diǎn)。作者的建議是:對(duì)于復(fù)雜的業(yè)務(wù)系統(tǒng),盡量按照面向?qū)ο蟮脑瓌t進(jìn)行設(shè)計(jì),只有在性能出現(xiàn)問(wèn)題的時(shí)候才開(kāi)始考慮恒變分離模式;而對(duì)于高性能,業(yè)務(wù)簡(jiǎn)單的基礎(chǔ)數(shù)據(jù)服務(wù),恒變分離模式應(yīng)該是設(shè)計(jì)之初的一個(gè)重要原則。
數(shù)據(jù)局部性模式(Locality Pattern)
原理和動(dòng)機(jī):
數(shù)據(jù)局部性模式是多次請(qǐng)求杠桿反模式的針對(duì)性解決方案。在大數(shù)據(jù)和強(qiáng)調(diào)個(gè)性化服務(wù)的時(shí)代,一個(gè)服務(wù)消費(fèi)幾十種不同類(lèi)型數(shù)據(jù)的現(xiàn)象非常常見(jiàn),同時(shí)每一種類(lèi)型的數(shù)據(jù)服務(wù)都有可能需要一個(gè)大的集群(多臺(tái)機(jī)器)提供服務(wù)。這就意味著客戶(hù)端的一次請(qǐng)求有可能會(huì)導(dǎo)致服務(wù)端成千上萬(wàn)次調(diào)用操作,很容易使系統(tǒng)進(jìn)入多次請(qǐng)求杠桿反模式。在具體開(kāi)發(fā)過(guò)程中,導(dǎo)致數(shù)據(jù)服務(wù)數(shù)量暴增的主要原因有兩個(gè):1. 緩存濫用以及缺乏規(guī)劃,2. 數(shù)據(jù)量太大以至于無(wú)法在一臺(tái)機(jī)器上提供全量數(shù)據(jù)服務(wù)。數(shù)據(jù)局部性模的核心思想是合理組織數(shù)據(jù)服務(wù),減少服務(wù)調(diào)用次數(shù)。具體而言,可以從服務(wù)端和客戶(hù)端兩個(gè)方面進(jìn)行優(yōu)化。
服務(wù)端優(yōu)化方案的手段是對(duì)服務(wù)進(jìn)行重新規(guī)劃。對(duì)于數(shù)據(jù)量太大以至于無(wú)法在一臺(tái)機(jī)器上存儲(chǔ)全量數(shù)據(jù)的場(chǎng)景,建議采用Bigtable或類(lèi)似的解決方案提供數(shù)據(jù)服務(wù)。典型的Bigtable的實(shí)現(xiàn)包括Hbase、Google Cloud Bigtable等。實(shí)際上數(shù)據(jù)局部性是Bigtable的一個(gè)重要設(shè)計(jì)原則,其原理是通過(guò)Row key和Column key兩個(gè)主鍵來(lái)對(duì)數(shù)據(jù)進(jìn)行索引,并確保同一個(gè)Row key索引的所有數(shù)據(jù)都在一臺(tái)服務(wù)器上面。通過(guò)這種數(shù)據(jù)組織方式,一次網(wǎng)絡(luò)請(qǐng)求可以獲取同一個(gè)Row key對(duì)應(yīng)的多個(gè)Column key索引的數(shù)據(jù)。缺乏規(guī)劃也是造成服務(wù)數(shù)量劇增的一個(gè)重要原因。很多通過(guò)統(tǒng)計(jì)和挖掘出來(lái)的特征數(shù)據(jù)往往是在漫長(zhǎng)的時(shí)間里由不同team獨(dú)立產(chǎn)生的。而對(duì)于每種類(lèi)型數(shù)據(jù),在其產(chǎn)生之初,由于不確定其實(shí)際效果以及生命周期,基于快速接入原則,服務(wù)提供者往往會(huì)用手頭最容易實(shí)施的方案,例如采用Redis Cache(不加選擇地使用緩存會(huì)導(dǎo)致緩存濫用)。數(shù)據(jù)服務(wù)之間缺乏聯(lián)動(dòng)以及缺乏標(biāo)準(zhǔn)接入規(guī)劃流程就會(huì)導(dǎo)致數(shù)據(jù)服務(wù)數(shù)量膨脹。數(shù)據(jù)局部性原則對(duì)規(guī)劃的要求,具體而言是指:1. 數(shù)據(jù)由盡可能少的服務(wù)器來(lái)提供,2. 經(jīng)常被一起使用的數(shù)據(jù)盡可能放在同一臺(tái)服務(wù)器上。
客戶(hù)端優(yōu)化有如下幾個(gè)手段:
本地緩存,對(duì)于一致性要求不高且緩存命中率較高的數(shù)據(jù)服務(wù),本地緩存可以減少服務(wù)端調(diào)用次數(shù);
批處理,對(duì)于單機(jī)或者由等價(jià)的機(jī)器集群提供的數(shù)據(jù)服務(wù),盡可能采用批處理方式,將多個(gè)請(qǐng)求合成在一個(gè)請(qǐng)求中;
客戶(hù)端Hash,對(duì)于需要通過(guò)Hash將請(qǐng)求分配到不同數(shù)據(jù)服務(wù)機(jī)器的服務(wù),盡量在客戶(hù)端進(jìn)行Hash,對(duì)于落入同一等價(jià)集群的請(qǐng)求采用批處理方式進(jìn)行調(diào)用。
案例分析:
我們的挑戰(zhàn)來(lái)自于美團(tuán)的推薦、個(gè)性化列表和個(gè)性化搜索服務(wù)。這些個(gè)性化系統(tǒng)需要獲取各種用戶(hù)、商家和團(tuán)購(gòu)信息。信息類(lèi)型包括基本屬性和統(tǒng)計(jì)屬性。最初,不同屬性數(shù)據(jù)由不同的服務(wù)提供,有些是RPC服務(wù),有些是Redis服務(wù),有些是HBase或者數(shù)據(jù)庫(kù),參見(jiàn)下圖:
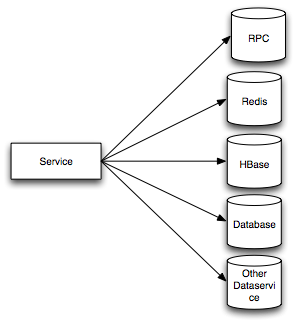
通常而言,客戶(hù)端每個(gè)用戶(hù)請(qǐng)求都會(huì)觸發(fā)多個(gè)算法。一方面,每個(gè)算法都會(huì)召回幾十甚至幾百個(gè)團(tuán)購(gòu)或者商家ID,團(tuán)購(gòu)和商家基礎(chǔ)屬性被均勻地分配到幾十臺(tái)Redis里面(如下圖),產(chǎn)生了大量的Redis請(qǐng)求,極端情況下,一次客戶(hù)端請(qǐng)求所觸發(fā)的團(tuán)購(gòu)基礎(chǔ)數(shù)據(jù)請(qǐng)求就超過(guò)了上千次;另一方面,用戶(hù)特征屬性信息有十幾種,每種屬性也由單獨(dú)的服務(wù)提供,服務(wù)端網(wǎng)絡(luò)調(diào)用次數(shù)暴增。在一段時(shí)間里,很多系統(tǒng)都進(jìn)入了多次請(qǐng)求杠桿反模式,Redis服務(wù)器的網(wǎng)卡經(jīng)常被打死,多次進(jìn)行擴(kuò)容,提高線程池線程數(shù)量,絲毫沒(méi)有改善。
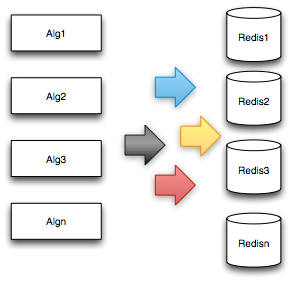
在對(duì)系統(tǒng)進(jìn)行分析之后,按照數(shù)據(jù)局部性模式的原則,我們采用了如下手段,徹底解決了系統(tǒng)多次請(qǐng)求杠桿反模式的問(wèn)題:
采用大內(nèi)存服務(wù)器存儲(chǔ)所有的團(tuán)購(gòu)和商家基礎(chǔ)信息,每個(gè)算法只要一次網(wǎng)絡(luò)請(qǐng)求就可以獲取所有的信息;
服務(wù)端采用多線程方式提供服務(wù),避免了Redis單一線程模式下單個(gè)請(qǐng)求慢所帶來(lái)的連鎖效應(yīng);
借鑒類(lèi)似Bigtable的數(shù)據(jù)組織方式,將用戶(hù)的多種特征采用兩個(gè)維度(用戶(hù)維度和特征類(lèi)型)進(jìn)行索引,確保同一用戶(hù)的信息只存放在一臺(tái)機(jī)器上面,減少網(wǎng)絡(luò)調(diào)用數(shù)量。
缺點(diǎn)和優(yōu)點(diǎn):
數(shù)據(jù)局部性模式并不適用于系統(tǒng)初級(jí)階段。在初級(jí)階段,最小可用原則往往是主要設(shè)計(jì)原則之一,出于兩方面的考慮:一方面,在初級(jí)階段,很難預(yù)測(cè)所要提供服務(wù)的數(shù)據(jù)是否有效而且能夠長(zhǎng)期使用,以及未來(lái)的調(diào)用量;另一方面,在初級(jí)階段,工程師可能無(wú)法預(yù)測(cè)最終的調(diào)用模式,而不同的調(diào)用模式會(huì)導(dǎo)致數(shù)據(jù)局部性方案的設(shè)計(jì)不同。對(duì)于已經(jīng)大量使用的數(shù)據(jù)服務(wù),采用數(shù)據(jù)局部性模式進(jìn)行重構(gòu)必然要改變老的調(diào)用模式,這一方面會(huì)引入新的Bug,另一方面也意味著巨大的工作量。需要特別強(qiáng)調(diào)的是,數(shù)據(jù)處于系統(tǒng)的最底層,對(duì)于結(jié)構(gòu)復(fù)雜而又重要的數(shù)據(jù),重構(gòu)所帶來(lái)可靠性、一致性和工作量都是需要權(quán)衡的因素。對(duì)于請(qǐng)求量比較小的數(shù)據(jù)服務(wù),即使一次請(qǐng)求會(huì)觸發(fā)嚴(yán)重的請(qǐng)求杠桿效應(yīng),但是如果原始觸發(fā)請(qǐng)求數(shù)量在可預(yù)見(jiàn)的時(shí)間內(nèi)沒(méi)有明顯變多的跡象,進(jìn)行數(shù)據(jù)服務(wù)重構(gòu)可能得不償失。
數(shù)據(jù)局部性模式能夠解決多次請(qǐng)求杠桿反模式所導(dǎo)致的問(wèn)題,但它并非大數(shù)據(jù)的產(chǎn)物,CPU、編譯器的設(shè)計(jì)理念里早就融入了該模式,所以很容易被工程師理解。雖然過(guò)度設(shè)計(jì)在系統(tǒng)初級(jí)階段是一個(gè)要盡量避免的事情,但是理解和掌握數(shù)據(jù)局部性模式對(duì)于設(shè)計(jì)出一個(gè)可擴(kuò)展、可重用的系統(tǒng)有很大幫助。很多成熟的系統(tǒng)因?yàn)槎啻握?qǐng)求杠桿反模式而導(dǎo)致系統(tǒng)頻繁崩潰,理解數(shù)據(jù)局部性模式的原則有助于提高工程師分析解決問(wèn)題的能力,而在確認(rèn)了系統(tǒng)存在請(qǐng)求杠桿問(wèn)題后,數(shù)據(jù)局部性原則是一件非常銳利的武器。
避免蚊子大炮模式(Avoiding Over-generalized Solution Pattern)
原理和動(dòng)機(jī):
“用大炮打蚊子”本來(lái)是大材小用的意思,但是細(xì)致想一想,用大炮打蚊子,成功率不高。對(duì)于開(kāi)發(fā)工程師而言,一方面為了快速承接業(yè)務(wù),按照方案復(fù)用原則,總是盡可能地利用現(xiàn)有系統(tǒng),這使得系統(tǒng)功能越來(lái)越強(qiáng)大;另一方面,提高系統(tǒng)的通用性或可重用性也是工程師們?cè)谠O(shè)計(jì)系統(tǒng)的一個(gè)重要目標(biāo)。隨著這兩個(gè)過(guò)程的相互獨(dú)立演化,采用通用方案解決特定問(wèn)題的現(xiàn)象隨處可見(jiàn),形象地說(shuō),這就像大炮打蚊子。大炮成本很高,蚊子的數(shù)量眾多,最終的結(jié)局往往是蚊子戰(zhàn)勝了大炮。
“避免蚊子大炮模式”是經(jīng)濟(jì)原則在運(yùn)行時(shí)系統(tǒng)的運(yùn)用,它要求采用最節(jié)省資源(CPU、內(nèi)存等)的方法來(lái)解決所面臨的問(wèn)題,資源浪費(fèi)會(huì)帶來(lái)未來(lái)潛在的風(fēng)險(xiǎn)。工程師接到一個(gè)需求的時(shí)候,需要思考的不僅僅是如何復(fù)用現(xiàn)有的系統(tǒng),減少開(kāi)發(fā)時(shí)間,還需要考慮現(xiàn)有系統(tǒng)為處理每個(gè)新需求訪問(wèn)所需運(yùn)行時(shí)成本,以及新需求的預(yù)期訪問(wèn)量。否則,不加辨別地利用現(xiàn)有系統(tǒng),不僅僅增大了重構(gòu)風(fēng)險(xiǎn),還有可能交叉影響,對(duì)現(xiàn)有系統(tǒng)所支持的服務(wù)造成影響。從另外一個(gè)角度講,工程師在構(gòu)建一個(gè)可重用系統(tǒng)的時(shí)候,要明確其所不能解決和不建議解決的問(wèn)題,而對(duì)于不建議解決的問(wèn)題,在文檔中標(biāo)明潛在的風(fēng)險(xiǎn)。
案例分析:
我們的挑戰(zhàn)是為移動(dòng)用戶(hù)尋找其所在位置附近的商家信息。美團(tuán)有非常完善的搜索系統(tǒng),也有資深的搜索工程師,所以一個(gè)系統(tǒng)需要查找附近的商家的時(shí)候,往往第一方案就是調(diào)用搜索服務(wù)。但是在美團(tuán),太多的服務(wù)有基于LBS的查詢(xún)需求,導(dǎo)致搜索請(qǐng)求量直線上升,這本來(lái)不屬于搜索的主營(yíng)業(yè)務(wù),在一段時(shí)間里面反倒成了搜索的最多請(qǐng)求來(lái)源。而搜索引擎在如何從幾十萬(wàn)商家里面找最近的幾百商家方面的性能非常差,因此一段時(shí)間里,搜索服務(wù)頻繁報(bào)警。不僅僅搜索服務(wù)可用性受到了影響,所有依賴(lài)于LBS的服務(wù)的可用性都大大降低。
在對(duì)系統(tǒng)分析之后,我們認(rèn)為更適合解決最短直線距離的算法應(yīng)該是k-d tree,在快速實(shí)現(xiàn)了基于k-d tree的LBS Search解決方案之后,我們用4臺(tái)服務(wù)器輕松解決了30多臺(tái)搜索服務(wù)器無(wú)法解決的問(wèn)題,平均響應(yīng)時(shí)間從高峰時(shí)的100ms降低到300ns,性能取得了幾百倍的提高。
缺點(diǎn)和優(yōu)點(diǎn):
避免蚊子大炮模式的問(wèn)題和數(shù)據(jù)局部性模式類(lèi)似,都與最小可用原則相沖突。在系統(tǒng)設(shè)計(jì)初級(jí)階段,尋求最優(yōu)方案往往意味著過(guò)度設(shè)計(jì),整個(gè)項(xiàng)目在時(shí)間和成本變得不可控,而為每個(gè)問(wèn)題去找最優(yōu)秀的解決方案是不現(xiàn)實(shí)的奢求。最優(yōu)化原則的要求是全面的,不僅僅要考慮的運(yùn)行時(shí)資源,還需要考慮工程師資源和時(shí)間成本等,而這些點(diǎn)往往相互矛盾。在如下情況下,避免蚊子大炮模式所帶來(lái)的好處有限:在可預(yù)見(jiàn)的未來(lái),某個(gè)業(yè)務(wù)請(qǐng)求量非常小,這時(shí)候花大量精力去找最優(yōu)技術(shù)方案效果不明顯。
在設(shè)計(jì)階段,避免蚊子大炮模式是一個(gè)需要工程師去權(quán)衡的選擇,需要在開(kāi)發(fā)成本和系統(tǒng)運(yùn)行成本之間保持一個(gè)平衡點(diǎn)。當(dāng)很多功能融入到一個(gè)通用系統(tǒng)里而出現(xiàn)性能問(wèn)題的時(shí)候,要拆分出來(lái)每一個(gè)功能點(diǎn)所造成的影響也不是件輕易的事情,所以采用分開(kāi)部署而共用代碼庫(kù)的原則可以快速定位問(wèn)題,然后有針對(duì)性地解決“蚊子大炮”問(wèn)題。總的來(lái)說(shuō),在設(shè)計(jì)階段,避免蚊子大炮模式是工程師們進(jìn)行分析和設(shè)計(jì)的一個(gè)重要準(zhǔn)則,工程師可以暫時(shí)不解決潛在的問(wèn)題,但是一定要清楚潛在的危害。構(gòu)建可重用系統(tǒng)或方案,一定要明確其所不能解決和不建議解決的問(wèn)題,避免過(guò)度使用。
實(shí)時(shí)離線分離模式(Sandbox Pattern)
原理和動(dòng)機(jī):
本模式的極端要求是:離線服務(wù)永遠(yuǎn)不要調(diào)用實(shí)時(shí)服務(wù)。該模式比較簡(jiǎn)單也容易理解,但是,嚴(yán)格地講它不是一種系統(tǒng)設(shè)計(jì)模式,而是一種管理規(guī)范。離線服務(wù)和在線服務(wù)從可用性、可靠性、一致性的要求上完全不同。原則上,工程師在編寫(xiě)離線服務(wù)代碼的時(shí)候,應(yīng)該遵循的就是離線服務(wù)編程規(guī)范,按照在線服務(wù)編程規(guī)范要求,成本就會(huì)大大提高,不符合經(jīng)濟(jì)原則;從另外一方面講,按照離線服務(wù)的需求去寫(xiě)在線服務(wù)代碼,可用性、可靠性、一致性等往往得不到滿足。
具體而言,實(shí)時(shí)離線分離模式建議如下幾種規(guī)范:
如果離線程序需要訪問(wèn)在線服務(wù),應(yīng)該給離線程序單獨(dú)部署一套服務(wù);
類(lèi)似于MapReduce的云端多進(jìn)程離線程序禁止直接訪問(wèn)在線服務(wù);
分布式系統(tǒng)永遠(yuǎn)不要直接寫(xiě)傳統(tǒng)的DBMS。
案例分析:
因?yàn)檫`反實(shí)時(shí)離線分離模式而導(dǎo)致的事故非常常見(jiàn)。有一次,因?yàn)橐粋€(gè)離線程序頻繁的向Tair集群寫(xiě)數(shù)據(jù),每一次寫(xiě)10M數(shù)據(jù),使得整個(gè)Tair集群宕機(jī)。另一次,因?yàn)镾torm系統(tǒng)直接寫(xiě)MySQL數(shù)據(jù)庫(kù)導(dǎo)致數(shù)據(jù)庫(kù)連接數(shù)耗盡,從而使在線系統(tǒng)無(wú)法連接數(shù)據(jù)庫(kù)。
缺點(diǎn)和優(yōu)點(diǎn):
為了實(shí)現(xiàn)實(shí)時(shí)在線分離,可能需要為在線環(huán)境和離線環(huán)境單獨(dú)部署,維護(hù)多套環(huán)境所帶來(lái)運(yùn)維成本是工程師需要考慮的問(wèn)題。另一方面,在線環(huán)境的數(shù)據(jù)在離線環(huán)境中可能很難獲取,這也是很多離線系統(tǒng)直接訪問(wèn)在線系統(tǒng)的原因。但是,遵從實(shí)時(shí)離線分離模式是一個(gè)非常重要的安全管理準(zhǔn)則,任何違背這個(gè)準(zhǔn)則的行為都意味著系統(tǒng)性安全漏洞,都會(huì)增大線上故障概率。
降級(jí)模式(Degradation Pattern)
原理和動(dòng)機(jī):
降級(jí)模式是系統(tǒng)性能保障的最后一道防線。理論上講,不存在絕對(duì)沒(méi)有漏洞的系統(tǒng),或者說(shuō),最好的安全措施就是為處于崩潰狀態(tài)的系統(tǒng)提供預(yù)案。從系統(tǒng)性能優(yōu)化的角度來(lái)講,不管系統(tǒng)設(shè)計(jì)地多么完善,總會(huì)有一些意料之外的情況會(huì)導(dǎo)致系統(tǒng)性能惡化,最終可能導(dǎo)致崩潰,所以對(duì)于要求高可用性的服務(wù),在系統(tǒng)設(shè)計(jì)之初,就必須做好降級(jí)設(shè)計(jì)。根據(jù)作者的經(jīng)驗(yàn),良好的降級(jí)方案應(yīng)該包含如下措施:
在設(shè)計(jì)階段,確定系統(tǒng)的開(kāi)始惡化數(shù)值指標(biāo)(例如:響應(yīng)時(shí)間,內(nèi)存使用量);
當(dāng)系統(tǒng)開(kāi)始惡化時(shí),需要第一時(shí)間報(bào)警;
在收到報(bào)警后,或者人工手動(dòng)控制系統(tǒng)進(jìn)入降級(jí)狀態(tài),或者編寫(xiě)一個(gè)智能程序讓系統(tǒng)自動(dòng)降級(jí);
區(qū)分系統(tǒng)所依賴(lài)服務(wù)的必要性,一般分為:必要服務(wù)和可選服務(wù)。必要服務(wù)在降級(jí)狀態(tài)下需要提供一個(gè)快速返回結(jié)果的權(quán)宜方案(緩存是常見(jiàn)的一種方案),而對(duì)于可選服務(wù),在降級(jí)時(shí)系統(tǒng)果斷不調(diào)用;
在系統(tǒng)遠(yuǎn)離惡化情況時(shí),需要人工恢復(fù),或者智能程序自動(dòng)升級(jí)。
典型的降級(jí)策略有三種:流量降級(jí)、效果降級(jí)和功能性降級(jí)。流量降級(jí)是指當(dāng)通過(guò)主動(dòng)拒絕處理部分流量的方式讓系統(tǒng)正常服務(wù)未降級(jí)的流量,這會(huì)造成部分用戶(hù)服務(wù)不可用;效果降級(jí)表現(xiàn)為服務(wù)質(zhì)量的降級(jí),即在流量高峰時(shí)期用相對(duì)低質(zhì)量、低延時(shí)的服務(wù)來(lái)替換高質(zhì)量、高延時(shí)的服務(wù),保障所有用戶(hù)的服務(wù)可用性;功能性降級(jí)也表現(xiàn)為服務(wù)質(zhì)量的降級(jí),指的是通過(guò)減少功能的方式來(lái)提高用戶(hù)的服務(wù)可用性。效果降級(jí)和功能性降級(jí)比較接近,效果降級(jí)強(qiáng)調(diào)的是主功能服務(wù)質(zhì)量的下降,功能性降級(jí)更多強(qiáng)調(diào)的是輔助性功能的缺失。做一個(gè)類(lèi)比如下:計(jì)劃將100個(gè)工程師從北京送到夏威夷度假,但是預(yù)算不夠。采用流量降級(jí)策略,只有50工程師做頭等艙去了夏威夷度假,其余工程師繼續(xù)編寫(xiě)程序(這可不好);效果降級(jí)策略下,100個(gè)工程師都坐經(jīng)濟(jì)艙去夏威夷;采用功能性降級(jí)策略,100個(gè)工程師都坐頭等艙去夏威夷,但是飛機(jī)上不提供食品和飲料。
案例分析:
我們的系統(tǒng)大量使用了智能降級(jí)程序。在系統(tǒng)惡化的時(shí)候,智能降級(jí)程序自動(dòng)降級(jí)部分流量,當(dāng)系統(tǒng)恢復(fù)的時(shí)候,智能降級(jí)程序自動(dòng)升級(jí)為正常狀態(tài)。在采用智能降級(jí)程序之前,因?yàn)橄到y(tǒng)降級(jí)問(wèn)題,整體系統(tǒng)不可用的情況偶爾發(fā)生。采用智能降級(jí)程序之后,基本上沒(méi)有因?yàn)樾阅軉?wèn)題而導(dǎo)致的系統(tǒng)整體不可用。我們的智能降級(jí)程序的主要判定策略是服務(wù)響應(yīng)時(shí)間,如果出現(xiàn)大量長(zhǎng)時(shí)間的響應(yīng)異常或超時(shí)異常,系統(tǒng)就會(huì)走降級(jí)流程,如果異常數(shù)量變少,系統(tǒng)就會(huì)自動(dòng)恢復(fù)。
缺點(diǎn)和優(yōu)點(diǎn):
為了使系統(tǒng)具備降級(jí)功能,需要撰寫(xiě)大量的代碼,而降級(jí)代碼往往比正常業(yè)務(wù)代碼更難寫(xiě),更容易出錯(cuò),所以并不符合奧卡姆剃刀原則。在確定使用降級(jí)模式的前提下,工程師需要權(quán)衡這三種降級(jí)策略的利弊。大多數(shù)面向C端的系統(tǒng)傾向于采用效果降級(jí)和功能性降級(jí)策略,但是有些功能性模塊(比如下單功能)是不能進(jìn)行效果和功能性降級(jí)的,只能采用流量降級(jí)策略。對(duì)于不能接受降級(jí)后果的系統(tǒng),必須要通過(guò)其他方式來(lái)提高系統(tǒng)的可用性。
總的來(lái)說(shuō),降級(jí)模式是一種設(shè)計(jì)安全準(zhǔn)則,任何高可用性要求的服務(wù),必須要按照降級(jí)模式的準(zhǔn)則去設(shè)計(jì)。對(duì)于違背這條設(shè)計(jì)原則的系統(tǒng),或早或晚,系統(tǒng)總會(huì)因?yàn)槟承﹩?wèn)題導(dǎo)致崩潰而降低可用性。不過(guò),降級(jí)模式并非不需要成本,也不符合最小可用原則,所以對(duì)于處于MVP階段的系統(tǒng),或者對(duì)于可用性要求不高的系統(tǒng),降級(jí)模式并非必須采納的原則。
其他性能優(yōu)化建議:
對(duì)于無(wú)法采用系統(tǒng)性的模式方式講解的性能優(yōu)化手段,作者也給出一些總結(jié)性的建議:
刪除無(wú)用代碼有時(shí)候可以解決性能問(wèn)題,例如:有些代碼已經(jīng)不再被調(diào)用但是可能被初始化,甚至占有大量?jī)?nèi)存;有些代碼雖然在調(diào)用但是對(duì)于業(yè)務(wù)而言已經(jīng)無(wú)用,這種調(diào)用占用CPU資源。
避免跨機(jī)房調(diào)用,跨機(jī)房調(diào)用經(jīng)常成為系統(tǒng)的性能瓶頸,特別是那些偽batch調(diào)用(在使用者看起來(lái)是一次性調(diào)用,但是內(nèi)部實(shí)現(xiàn)采用的是順序單個(gè)調(diào)用模式)對(duì)系統(tǒng)性能影響往往非常巨大
。
總結(jié)
Christopher Alexander曾說(shuō)過(guò):"Each pattern describes a problem which occurs over and over again in our environment, and then describes the core of the solution to that problem, in such a way that you can use this solution a million times over, without ever doing it the same way twice" 。 盡管Christopher Alexander指的是建筑模式,軟件設(shè)計(jì)模式適用,基于同樣的原因,性能優(yōu)化模式也適用。每個(gè)性能優(yōu)化模式描述的都是工程師們?nèi)粘9ぷ髦薪?jīng)常出現(xiàn)的問(wèn)題,一個(gè)性能優(yōu)化模式可以解決確定場(chǎng)景下的某一類(lèi)型的問(wèn)題。所以要理解一個(gè)性能優(yōu)化模式不僅僅要了解性能模式的所能解決的問(wèn)題以及解決手段,還需要清楚該問(wèn)題所發(fā)生的場(chǎng)景和需要付出的代價(jià)。
最后,本文所描述的性能優(yōu)化模式只是作者的工作經(jīng)驗(yàn)總結(jié),都是為了解決由以下三種情況所造成的性能問(wèn)題:1. 日益增長(zhǎng)的用戶(hù)數(shù)量,2. 日漸復(fù)雜的業(yè)務(wù),3. 急劇膨脹的數(shù)據(jù),但是這些遠(yuǎn)非該領(lǐng)域里面的所有模式。對(duì)于文章中提到的其他性能優(yōu)化建議,以及現(xiàn)在和將來(lái)可能碰到的性能問(wèn)題,作者還會(huì)不斷抽象,在未來(lái)總結(jié)出更多的模式。性能問(wèn)題涉及領(lǐng)域非常廣泛,而模式是一個(gè)非常好的講解性能問(wèn)題以及解決方案的方式,作者有理由相信,無(wú)論是在作者所從事的工作領(lǐng)域里面還是在其他的領(lǐng)域里面,新的性能優(yōu)化模式會(huì)不斷涌現(xiàn)。希望通過(guò)本文的講述,對(duì)碰到同樣問(wèn)題的工程師們有所幫助,同時(shí)也拋磚引玉,期待出現(xiàn)更多的基于模式方式講解性能優(yōu)化的文章。
