正則表達式是一個特殊的字符序列,用于簡潔表達一組字符串特征,檢查一個字符串是否與某種模式匹配,使用起來十分方便。
在Python中,我們通過調用re庫來使用re模塊:
import re
正則表達式語法模式和操作符詳見:https://www.runoob.com/python/python-reg-expressions.html#flags
下面介紹Python常用的正則表達式處理函數。
re.match函數
re.match 函數從字符串的起始位置匹配正則表達式,返回match對象,如果不是起始位置匹配成功的話,match()就返回None。
re.match(pattern, string, flags=0)
pattern:匹配的正則表達式。
string:待匹配的字符串。
flags:標志位,用于控制正則表達式的匹配方式,如:是否區分大小寫,多行匹配等等。具體參數為:
re.I:忽略大小寫。
re.L:表示特殊字符集 \w, \W, \b, \B, \s, \S 依賴于當前環境。
re.M:多行模式。
re.S:即 . ,并且包括換行符在內的任意字符(. 不包括換行符)。
re.U:表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依賴于 Unicode 字符屬性數據庫。
re.X:為了增加可讀性,忽略空格和 # 后面的注釋。
import re
#從起始位置匹配
r1=re.match('abc','abcdefghi')
print(r1)
#不從起始位置匹配
r2=re.match('def','abcdefghi')
print(r2)
運行結果:
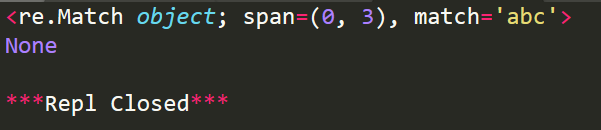
其中,span表示匹配成功的整個子串的索引。
使用group(num) 或 groups() 匹配對象函數來獲取匹配表達式。
group(num):匹配的整個表達式的字符串,group() 可以一次輸入多個組號,這時它將返回一個包含那些組所對應值的元組。
groups():返回一個包含所有小組字符串的元組,從 1 到 所含的小組號。
import re
s='This is a demo'
r1=re.match(r'(.*) is (.*)',s)
r2=re.match(r'(.*) is (.*?)',s)
print(r1.group())
print(r1.group(1))
print(r1.group(2))
print(r1.groups())
print()
print(r2.group())
print(r2.group(1))
print(r2.group(2))
print(r2.groups())
運行結果:
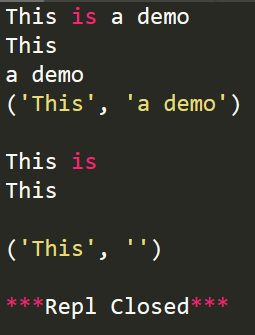
上述代碼中的(.*)和(.*?)表示正則表達式的貪婪匹配與非貪婪匹配,詳情見此:https://www.jb51.net/article/31491.htm
re.search函數
re.search函數掃描整個字符串并返回第一個成功的匹配,如果匹配成功則返回match對象,否則返回None。
re.search(pattern, string, flags=0)
pattern:匹配的正則表達式。
string:待匹配的字符串。
flags:標志位,用于控制正則表達式的匹配方式,如:是否區分大小寫,多行匹配等等。
import re
#從起始位置匹配
r1=re.search('abc','abcdefghi')
print(r1)
#不從起始位置匹配
r2=re.search('def','abcdefghi')
print(r2)
運行結果:
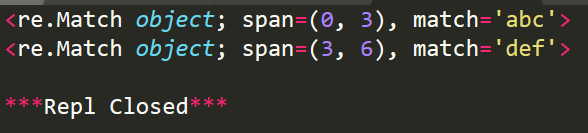
使用group(num) 或 groups() 匹配對象函數來獲取匹配表達式。
group(num=0):匹配的整個表達式的字符串,group() 可以一次輸入多個組號,這時它將返回一個包含那些組所對應值的元組。
groups():返回一個包含所有小組字符串的元組,從 1 到 所含的小組號。
import re
s='This is a demo'
r1=re.search(r'(.*) is (.*)',s)
r2=re.search(r'(.*) is (.*?)',s)
print(r1.group())
print(r1.group(1))
print(r1.group(2))
print(r1.groups())
print()
print(r2.group())
print(r2.group(1))
print(r2.group(2))
print(r2.groups())
運行結果:
從上面不難發現re.match與re.search的區別:re.match只匹配字符串的起始位置,只要起始位置不符合正則表達式就匹配失敗,而re.search是匹配整個字符串,直到找到一個匹配為止。
re.compile 函數
compile 函數用于編譯正則表達式,生成一個正則表達式對象,供 match() 和 search() 這兩個函數使用。
re.compile(pattern[, flags])
pattern:一個字符串形式的正則表達式。
flags:可選,表示匹配模式,比如忽略大小寫,多行模式等。
import re
#匹配數字
r=re.compile(r'\d+')
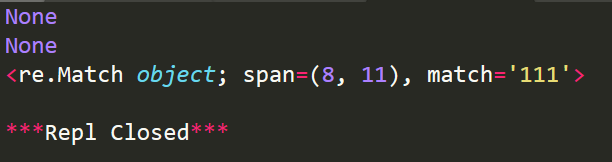
r1=r.match('This is a demo')
r2=r.match('This is 111 and That is 222',0,27)
r3=r.match('This is 111 and That is 222',8,27)
print(r1)
print(r2)
print(r3)
運行結果:
findall函數
搜索字符串,以列表形式返回正則表達式匹配的所有子串,如果沒有找到匹配的,則返回空列表。
需要注意的是,match 和 search 是匹配一次,而findall 匹配所有。
findall(string[, pos[, endpos]])
string:待匹配的字符串。
pos:可選參數,指定字符串的起始位置,默認為0。
endpos:可選參數,指定字符串的結束位置,默認為字符串的長度。
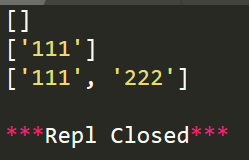
import re
#匹配數字
r=re.compile(r'\d+')
r1=r.findall('This is a demo')
r2=r.findall('This is 111 and That is 222',0,11)
r3=r.findall('This is 111 and That is 222',0,27)
print(r1)
print(r2)
print(r3)
運行結果:
re.finditer函數
和 findall 類似,在字符串中找到正則表達式所匹配的所有子串,并把它們作為一個迭代器返回。
re.finditer(pattern, string, flags=0)
pattern:匹配的正則表達式。
string:待匹配的字符串。
flags:標志位,用于控制正則表達式的匹配方式,如是否區分大小寫,多行匹配等。
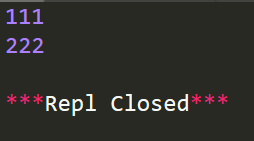
import re
r=re.finditer(r'\d+','This is 111 and That is 222')
for i in r:
print (i.group())
運行結果:
re.split函數
將一個字符串按照正則表達式匹配的子串進行分割后,以列表形式返回。
re.split(pattern, string[, maxsplit=0, flags=0])
pattern:匹配的正則表達式。
string:待匹配的字符串。
maxsplit:分割次數,maxsplit=1分割一次,默認為0,不限次數。
flags:標志位,用于控制正則表達式的匹配方式,如:是否區分大小寫,多行匹配等。
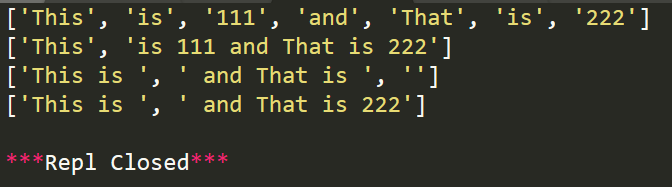
import re
r1=re.split('\W+','This is 111 and That is 222')
r2=re.split('\W+','This is 111 and That is 222',maxsplit=1)
r3=re.split('\d+','This is 111 and That is 222')
r4=re.split('\d+','This is 111 and That is 222',maxsplit=1)
print(r1)
print(r2)
print(r3)
print(r4)
運行結果:
re.sub函數
re.sub函數用于替換字符串中的匹配項。
re.sub(pattern, repl, string, count=0, flags=0)
pattern:正則中的模式字符串。
repl:替換的字符串,也可為一個函數。
string:要被查找替換的原始字符串。
count:模式匹配后替換的最大次數,默認0表示替換所有的匹配。
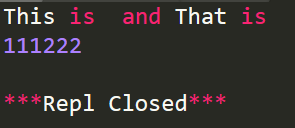
import re
r='This is 111 and That is 222'
# 刪除字符串中的數字
r1=re.sub(r'\d+','',r)
print(r1)
# 刪除非數字的字符串
r2=re.sub(r'\D','',r)
print(r2)
運行結果:
參考資料:
https://www.runoob.com/python/python-reg-expressions.html#flags
到此這篇關于Python常用的正則表達式處理函數詳解的文章就介紹到這了,更多相關python 正則表達式處理函數內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- 一文秒懂python正則表達式常用函數
- Python編程快速上手——strip()函數的正則表達式實現方法分析
- 關于Python正則表達式 findall函數問題詳解
- python使用正則表達式的search()函數實現指定位置搜索功能
- python正則表達式re之compile函數解析
- Python正則表達式常用函數總結
- Python中正則表達式match()、search()函數及match()和search()的區別詳解
