鑒于我在要完成的asp.net MVC 3 仿照博客園企業系統要用到測試數據,我自己輸入太累,所以我就抓取了博客園的部分列表數據,還請dudu不要見怪。
在抓取博客園數據的時候采用了正則表達式,所以有不熟悉正則表達式的朋友可以參考相關資料,其實很容易掌握,就是在具體的實例中會花些時間。
現在我就來把我抓取博客園數據的過程敘述一下,如果有朋友有更好的意見,歡迎提出來。
要使用正則表達式抓取數據,首先就要創建一個正則表達式進行匹配,我推薦使用regulator,這個正則表達式工具,我們可以先使用這個工具把我們要使用的正則表達式拼接出來,然后在程序中使用。
我發現博客園的首頁列表可以通過http://www.cnblogs.com/p1,p2...這種方式來直接訪問,這樣我們就可以直接通過url獲取數據,而不用模擬數據點擊事件來虛擬的點擊下一頁的那個按鈕獲取數據,更加方便。因為我的目的就是抓取一些數據,所以就簡單點。
1.首先就是要寫對應的sql Helper類,相信這是很多程序員都會掌握的,無非就是增刪改查的操作。在創建好了sqlhelper類之后,我們就可以開始進行抓取數據的邏輯處理。
2.創建BlogRegexController
public class BlogRegexController : Controller
{
public void ExecuteRegex()
{
string strBaseUrl = "http://www.cnblogs.com/p"; //定義博客園可以訪問的列表數據的基地址
for (int i = ; i = ; i++)//因為博客園首頁列表最大只有頁,所以我們這個循環就執行次
{
string strUrl = strBaseUrl + i.ToString();
BlogRege blogRegex = new BlogRege(); //定義的具體的Regex類 抓取博客園地址
string result = blogRegex.SendUrl(strUrl);
blogRegex.AnalysisHtml(result);
Response.Write("獲取成功");
}
}
//
// GET: /BlogRegex/
public ActionResult Index()
{
ExecuteRegex();
return View();
}
}
在controller中的ExecuteRegex()方法就是執行抓取博客園列表數據的功臣。
3.首先就是其中定義的BlogRege類,他負責抓取博客園列表數據并將其插入到數據庫中
public class BlogRege
{ //負責把數據插入到數據庫中 使用到的是sqlhelper類
public void Insert(string title, string content,string linkurl, int categoryID = )
{
SqlHelper helper = new SqlHelper();
helper.Insert(title, content, categoryID,linkurl);
}
/// summary>
/// 通過Url地址獲取具體網頁內容 發起一個請求獲得html內容
/// /summary>
/// param name="strUrl">/param>
/// returns>/returns>
public string SendUrl(string strUrl)
{
try
{
WebRequest webRequest = WebRequest.Create(strUrl);
WebResponse webResponse = webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string result = reader.ReadToEnd();
return result;
}
catch (Exception ex)
{
throw ex;
}
}
/// summary>
/// 分析Html 解析出里面具體的數據
/// /summary>
/// param name="htmlContent">/param>
public void AnalysisHtml(string htmlContent)
{//這個就是我在regulator正則表達式工具中拼接獲取到的正則表達式 還有一點請注意就是轉義字符的問題
string strPattern = "div\\s*class=\"post_item\">\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*div\\s*class=\"post_item_body\">\\s*h>a\\s*class=\"titlelnk\"\\s*href=\"(?href>.*)\"\\s*target=\"_blank\">(?title>.*)/a>.*\\s*p\\s*class=\"post_item_summary\">\\s*(?content>.*)\\s*/p>";
Regex regex = new Regex(strPattern, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant);
if (regex.IsMatch(htmlContent))
{
MatchCollection matchCollection = regex.Matches(htmlContent);
foreach (Match match in matchCollection)
{
string title = match.Groups[].Value;//獲取到的是列表數據的標題
string content = match.Groups[].Value;//獲取到的是內容
string linkurl=match.Groups[].Value;//獲取到的是鏈接到的地址
Insert(title, content,linkurl);//執行插入到數據庫的操作
}
}
}
}
4.通過上面的代碼我們可以很輕松的從博客園中獲取我們用來測試的數據,方便快捷,而且真實,比我們手動輸入的速度要快很多。
正則表達式其實不應該算是一種語言,只能算是一種語法,因為任何的語言包括C#,javascript等語言都對正則表達式有很好的支持,只是他們的使用語法稍有不同,其實只要我們可以正確的拼接出正則表達式,那么我們抓取任何網站的內容都可以很輕松的做到。前一段我試著抓取了淘寶的數據,一共抓取了有幾百萬條,我想應該還有很多沒有抓取到,不得不佩服淘寶,數據量太大。
回到我們使用的C#語言上,其實對正則表達式也有著非常好的支持,Regex就是用來對正則表達式進行操作的類,所有的對正則表達式的操作都在這個類中。
如果你對正則表達式還不是太熟悉,網上有一篇正則表達式30分鐘入門教程,大家可以參考一下,寫的很不錯。再加上使用一個正則表達式工具,相信可以抓取到任何你想的內容。
在拼接正則表達式的時候,可能會花費很長時間,畢竟要分析html結構,從中抓取內容。希望大家可以沉住氣,因為只要正則表達式拼接正確,那么一定可以抓取正確的內容。
為了避免大家說只說不做,那么我就把我抓取的博客園首頁內容秀一下,因為博客園首頁數據會有更新,所以大家可以看到這些數據都是在博客園中順序存在的。
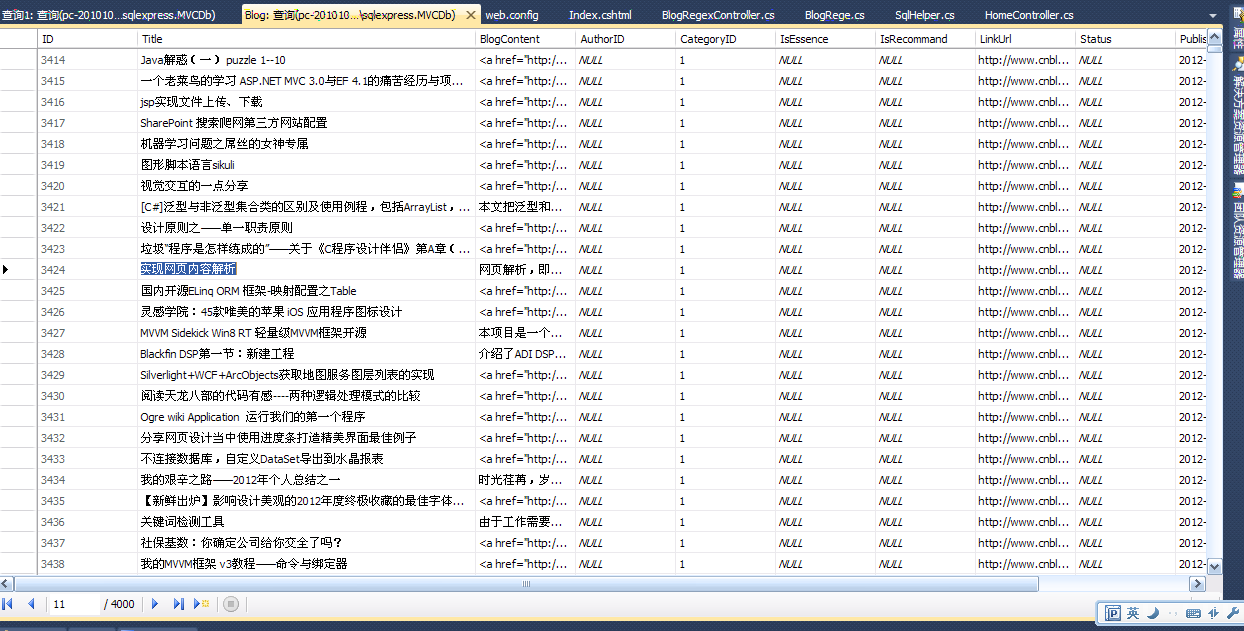
博客園每頁列表是20條,一共200頁,所以一共是4000條。數據抓取正確。
我以前說過,只是會代碼的程序員不一定是合格程序員,程序員應該盡可能的減少自己的工作量,因為我們都是高智商的人。所以我們應該積極的學習各種對我們的工作有幫助的框架或者是方法,比如IOC、Entity Framework或Nhibernate框架來減輕我們開發維護代碼的負擔,畢竟我們聽到需求要更改的反映,一般都是憤怒,然后大罵,最后才是修改。有些框架能夠幫助我們,給我們維護代碼帶來好心情,何樂而不為呢。
我最后說一句,因為我要開發一個簡單的仿照博客園的網站(MVC3),所以會用到各種技術準備,我提前寫出來把這些要用到的內容整理一下,為以后的開發加速。
下一次,我準備整理一下在MVC中使用文本編輯器KindEditor的方法,希望大家如果有好的意見或者資料可以提供一下,讓我也增加一些見識。謝謝各位
您可能感興趣的文章:- dw(dreamweaver)正則表達式函數列表
- python正則表達式抓取成語網站
- php使用curl和正則表達式抓取網頁數據示例
