| 代碼 | 含義 |
|---|---|
| @ | 原生順序 |
| = | 原生標準 |
| 小端 | |
| > | 大端 |
| ! | 網絡順序 |
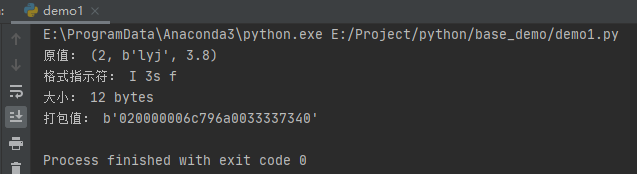
示例如下:
import struct
import binascii
values = (2, 'lyj'.encode('UTF-8'), 3.8)
endianness = [
('@', '原生順序'),
('=', '原生標準'),
('', '小端'),
('>', '大端'),
('!', '網絡順序'),
]
for code, name in endianness:
s = struct.Struct(code + ' I 3s f')
packed_data = s.pack(*values)
print("格式化字符串:", s.format, ' for ', name)
print("大小:", s.size, 'bytes')
print("打包:", binascii.hexlify(packed_data))
print("解包:", s.unpack(packed_data))
運行之后,效果如下:

如果想改變字節序來編碼,如上面代碼所示,只需要改變格式串中提供一個顯式的字節序指令,就可以很容易地覆蓋這個默認選擇。
通常在強調性能的情況下或者向擴展模塊傳入或傳出數據時才會處理二進制打包數據。
為了避免為每個打包結構分配一個新緩沖區所帶來的開銷,通常情況下,我們使用pack_into()和unpack_from()方法支持直接寫入預分配的緩沖區。
示例如下:
import struct
import binascii
import ctypes
import array
values = (2, 'lyj'.encode('UTF-8'), 3.8)
s = struct.Struct('I 3s f')
print("原始值:", values)
b = ctypes.create_string_buffer(s.size)
print("打包之前(緩沖區的值):", binascii.hexlify(b.raw))
s.pack_into(b, 0, *values)
print("打包之后(緩沖區的值):", binascii.hexlify(b.raw))
print("解包:", s.unpack_from(b, 0))
a = array.array('b', b'\0' * s.size)
print("打包之前(緩沖區的值):", binascii.hexlify(a))
s.pack_into(a, 0, *values)
print('打包之后(緩沖區的值):', binascii.hexlify(a))
print("解包:", s.unpack_from(a, 0))
運行之后,效果如下:
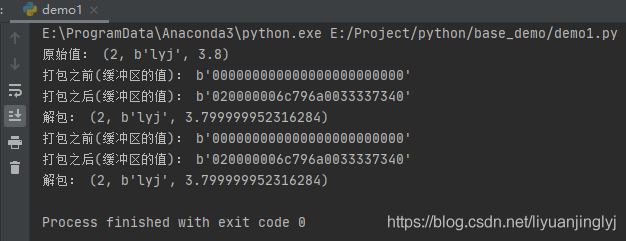
這里通過兩種方式,創建緩沖區。其中size屬性用于指出緩沖區需要的大小。
到此這篇關于Pytho 二進制數據結構Struct的具體使用的文章就介紹到這了,更多相關Pytho 二進制數據結構Struct內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!