目的:
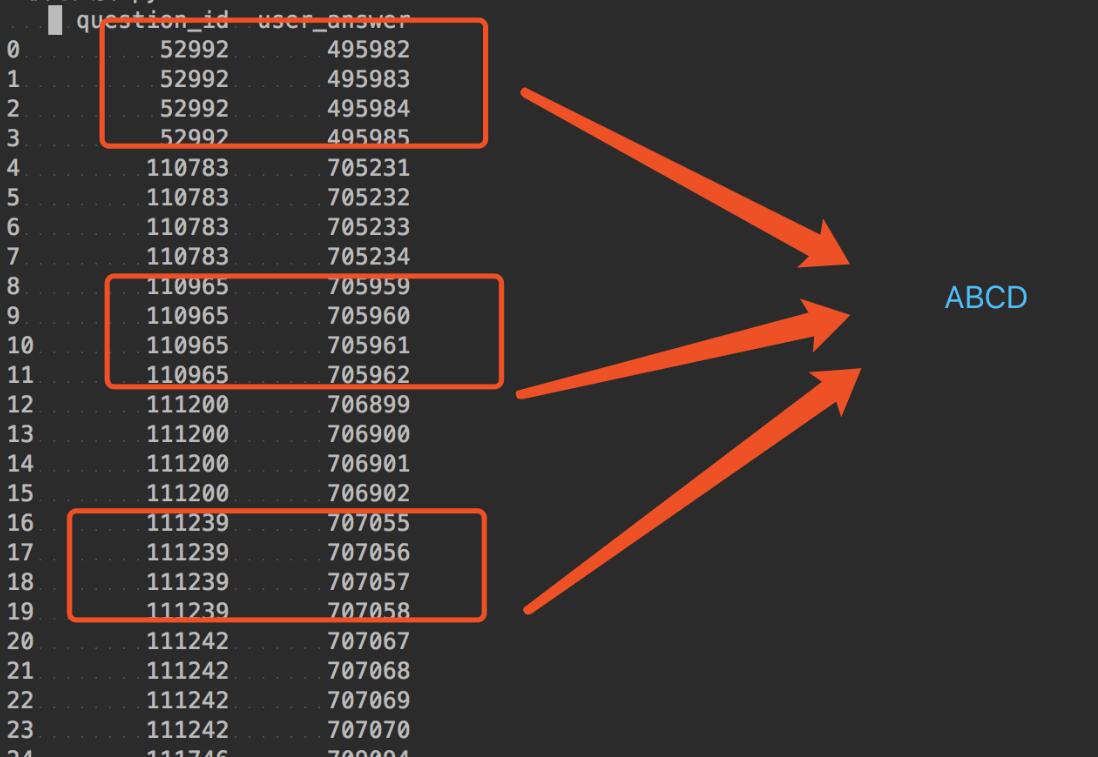
把question_id 對應的user_answer轉成ABCD
solution
dfa=df.groupby('question_id').nth(0).reset_index()
dfa['flag']='A'
dfb=df.groupby('question_id').nth(1).reset_index()
dfb['flag']='B'
dfc=df.groupby('question_id').nth(2).reset_index()
dfc['flag']='C'
dfd=df.groupby('question_id').nth(3).reset_index()
dfd['flag']='D'
resdf=dfa.append([dfb,dfc,dfd])
resdf.sort_values(by='question_id')
result:

focus:
g.nth(0)
#同
g.first()
g.head(1)
g.last()
g.nth(2)
g.nth(-1)
g.nth(0,dropna='any')
g.B.nth(0,dropna='all')
g.groups
g.get_group(134429)
g.discribe()
g.agg([np.mean,np.sum.np,std])
補充:pandas的分組取最大多行并求和函數(shù)nlargest()
在pandas庫里面,我們常常關心的是最大的前幾個,比如銷售最好的幾個產(chǎn)品,幾個店,等。之前講到的head(), 能夠看到看到DF里面的前幾行,如果需要看到最大或者最小的幾行就需要先進行排序。max()和min()可以看到最大或者最小值,但是只能看到一個值。
所以我們可以使用nlargest()函數(shù),nlargest()的優(yōu)點就是能一次看到最大的幾行,而且不需要排序。缺點就是只能看到最大的,看不到最小的。
我們來看看單價排在前十的數(shù)據(jù):
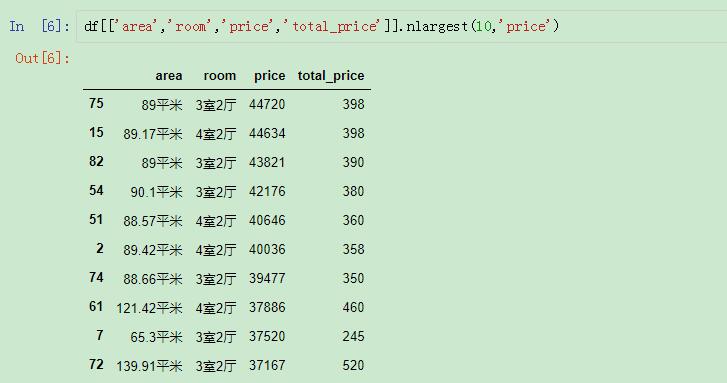
單價排在前十的數(shù)據(jù)
nlargest()的第一個參數(shù)就是截取的行數(shù)。第二個參數(shù)就是依據(jù)的列名。
這樣就可以篩選出單價最高的前十行,而且是按照單價從最高到最低進行排列的,所以還是按照之前的索引。
還可以按照total_price來進行排名:
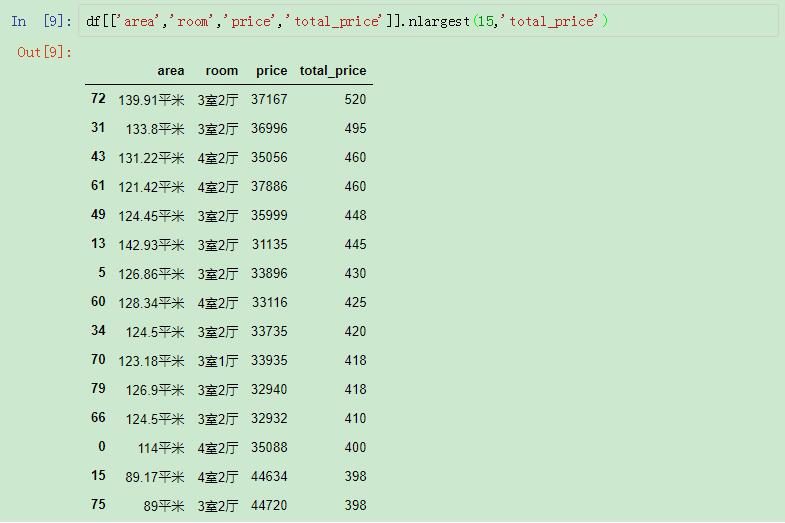
按照total_price排名
nlargest還有一個參數(shù),keep='first'或者'last'。當出現(xiàn)重復值的時候,keep='first',會選取在原始DataFrame里排在前面的,keep='last'則去排后面的。
由于nlagerst()不能去最小的多個值,如果我們一定要使用這個函數(shù)進行選取也是可以的.
先設置一個輔助列:
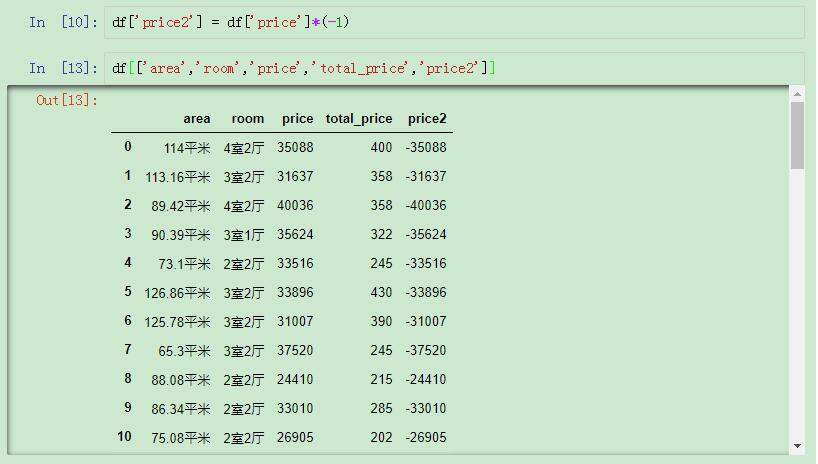
先設置一個輔助列
然后在進行選取:

以輔助列進行選取
當然了,也可以通過head()加上排序進行選取的。
那以前這些操作都可以通過其它函數(shù)來進行替代的話,nlargest()有什么必要介紹嗎?或者說學不學這個函數(shù)有什么關系嗎?
這就是我們今天要重點介紹的,如果說要選擇不同location_road下的前五名要怎么操作呢?
很多人可能第一反應會想到先分組然后進行max()操作,但是這樣的操作只能選擇最大的一列:
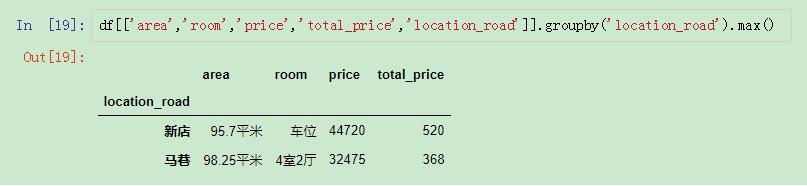
使用max()
但是使用max有一個問題,就是選取的是每一列的最大值,而不是選取最大值的那一行,也就是說只能在選取單列的最大值的時候才是準確的。
這個時候我們就要想到apply和lambda的自定義函數(shù)了:
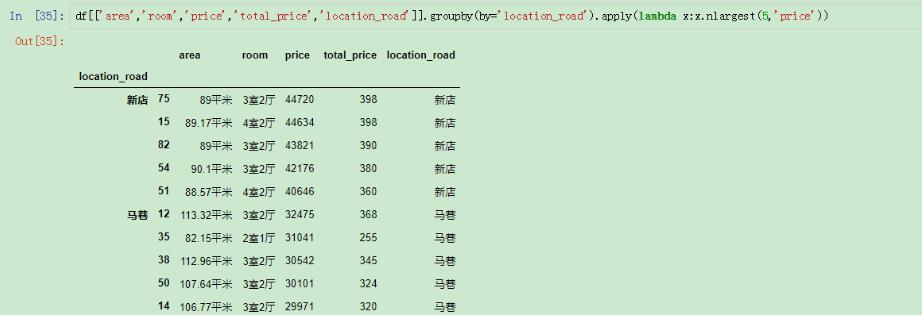
選取多個指標的TOP(N)
這樣就選出了不同loaction_road的price排在前五的行了。
nlargest()函數(shù)在這種場景下使用是非常方便的,而且結果也已經(jīng)默認排好順序了。
還有一些場景下需要計算分組的前幾名,然后在進行求和的,這個我們也可以使用nlargest進行操作:
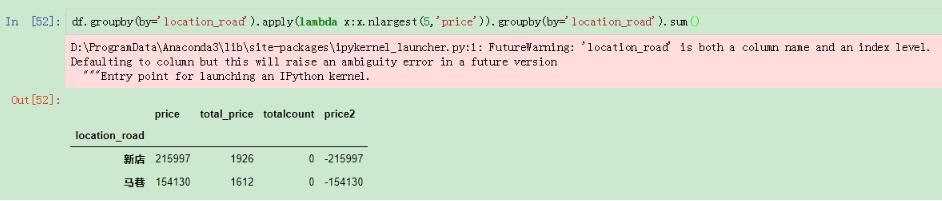
分組之后進行求和
使用這種方法會出現(xiàn)報錯提示,這個因為在列和索引都存在loaction_road,有重復,系統(tǒng)有警告,在實際使用時可以先改列名再操作。我們也可以換一種方式直接按照索引進行求和,這樣就沒有警告了:

以上為個人經(jīng)驗,希望能給大家一個參考,也希望大家多多支持腳本之家。如有錯誤或未考慮完全的地方,望不吝賜教。
您可能感興趣的文章:- Pandas中DataFrame的分組/分割/合并的實現(xiàn)
- pandas分組排序 如何獲取第二大的數(shù)據(jù)
- pandas group分組與agg聚合的實例
- pandas groupby分組對象的組內(nèi)排序解決方案
- pandas組內(nèi)排序,并在每個分組內(nèi)按序打上序號的操作
- pandas 實現(xiàn)某一列分組,其他列合并成list
